Down And Out
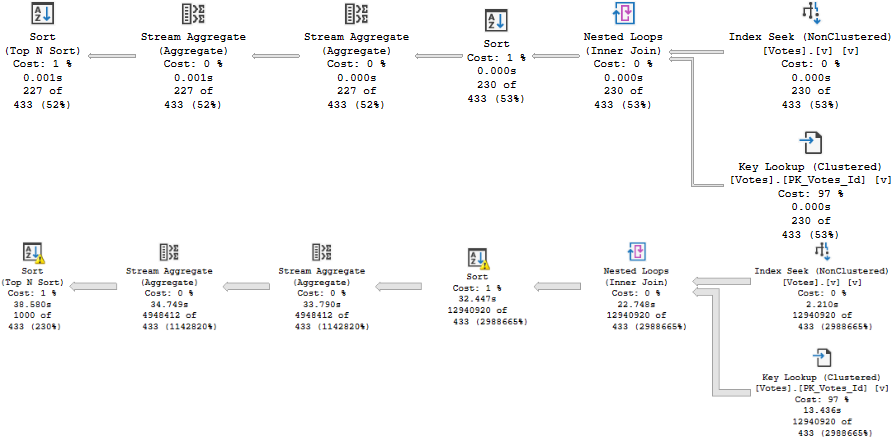
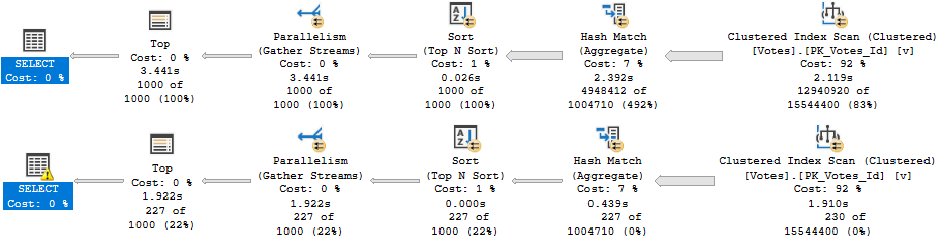
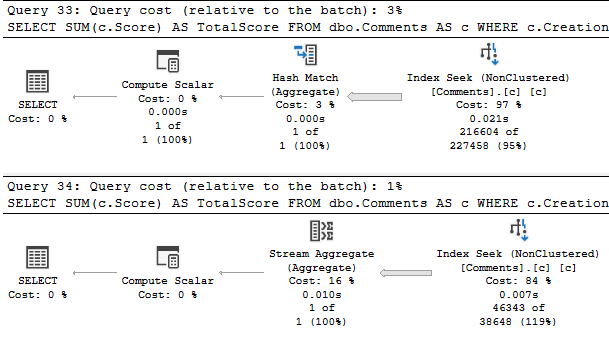
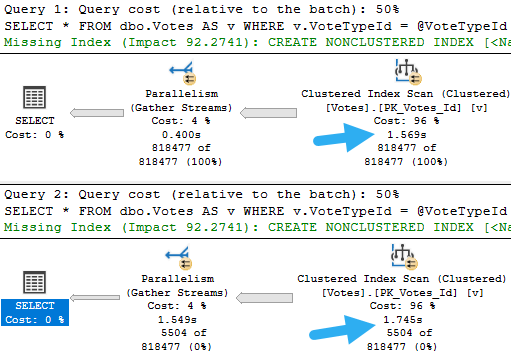
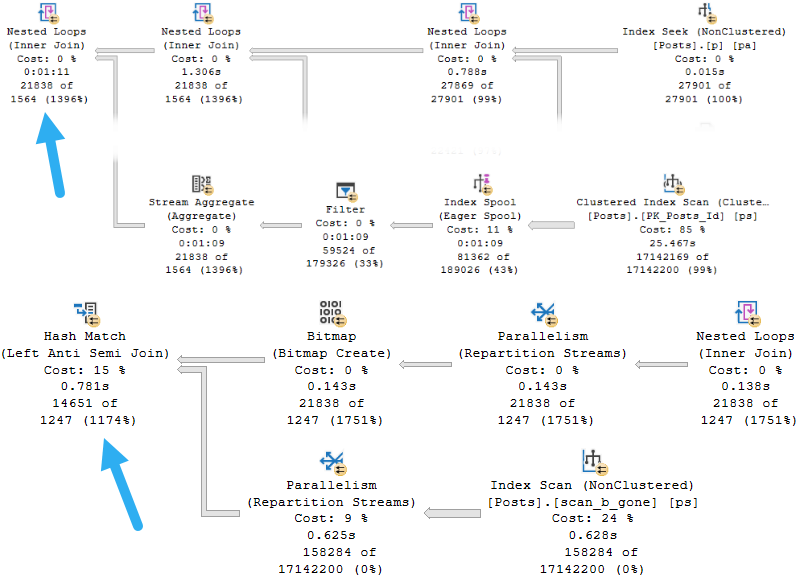
There are lots of different ways that parameter sniffing can manifest in both the operators chosen, the order of operators chosen, and the resources acquired by a query when a plan is compiled. At least in my day-to-day consulting, one of the most common reasons for plans being disagreeable is around insufficient indexes.
One way to fix the issue is to fix the index. We’ll talk about a way to do it without touching the indexes tomorrow.
Let’s say we have this index to start with. Maybe it was good for another query, and no one ever thought twice about it. After all, you rebuild your indexes every night, what other attention could they possible need?
CREATE INDEX v
ON dbo.Votes(VoteTypeId, CreationDate);
If we had a query with a where clause on those two columns, it’d be be able to find data pretty efficiently.
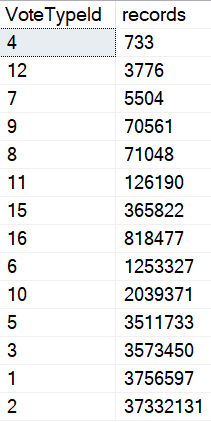
But how much data will it find? How many of each VoteTypeId are there? What range of dates are we looking for?
Well, that depends on our parameters.
Cookie Cookie
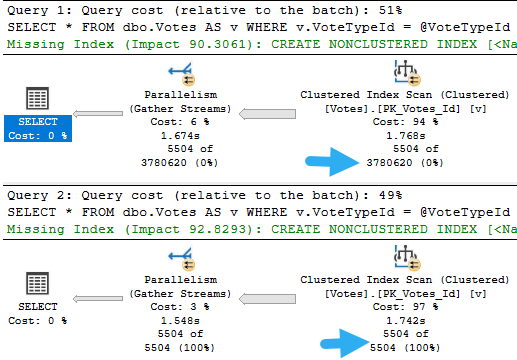
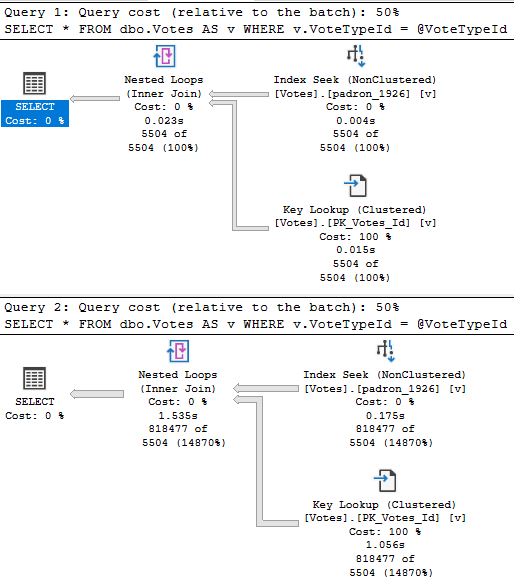
Here’s our stored procedure. There’s one column in it that isn’t in our index. What a bummer.
CREATE OR ALTER PROCEDURE dbo.VoteCount (@VoteTypeId INT, @YearsBack INT)
AS
BEGIN
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC;
END;
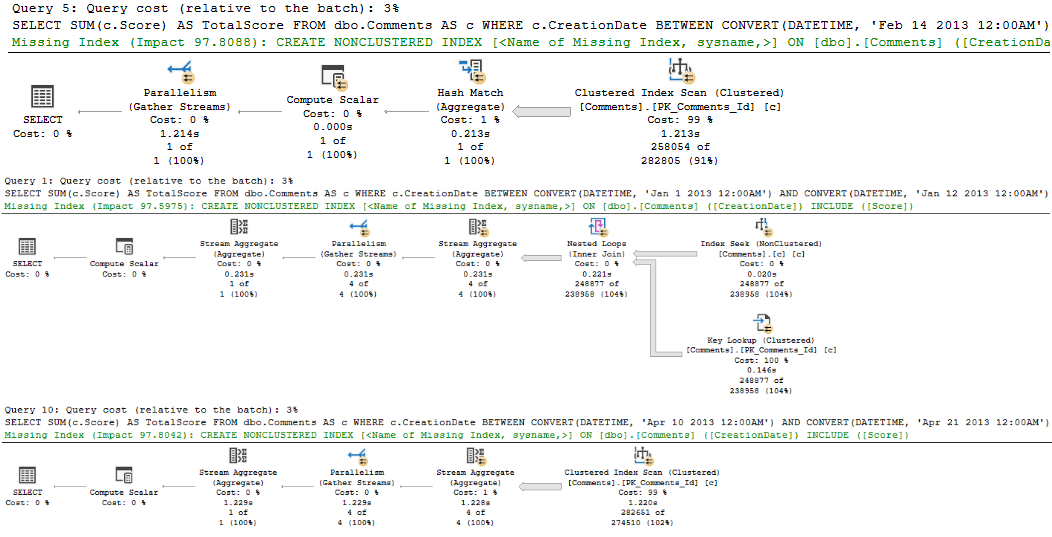
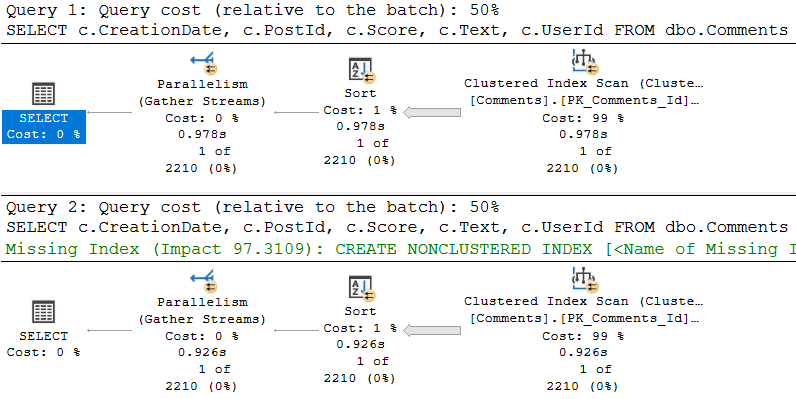
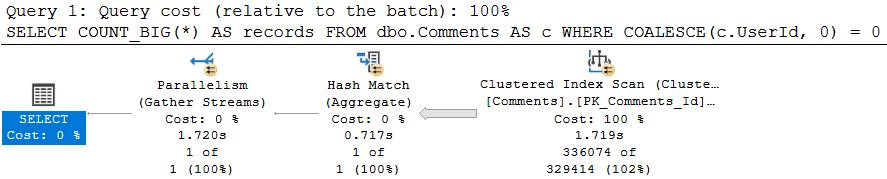
That doesn’t matter for a small amount of data, whether it’s encountered because of the parameters used, or the size of the data the procedure is developed and tested against. Testing against unrealistic data is a recipe for disaster, of course.
Cookie Cookie
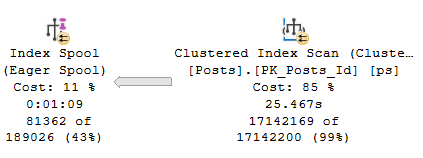
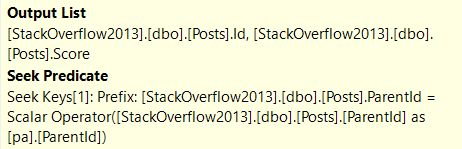
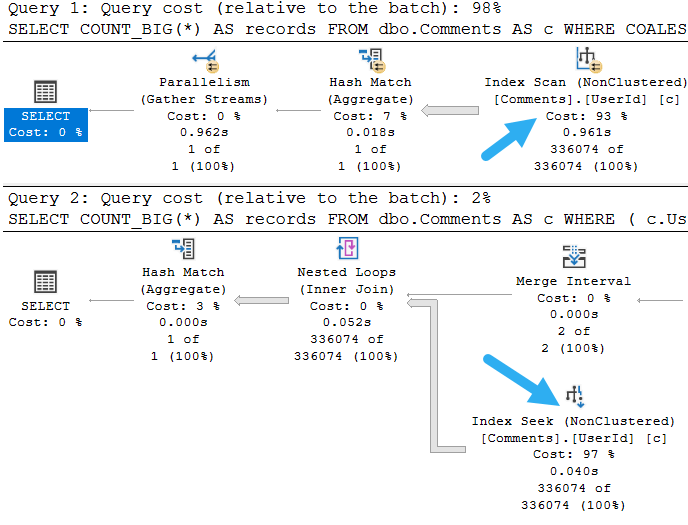
What can be tricky is that if the sniffing is occurring with the lookup plan, the optimizer won’t think enough of it to request a covering index, either in plan or in the index DMVs. It’s something you’ll have to figure out on your own.
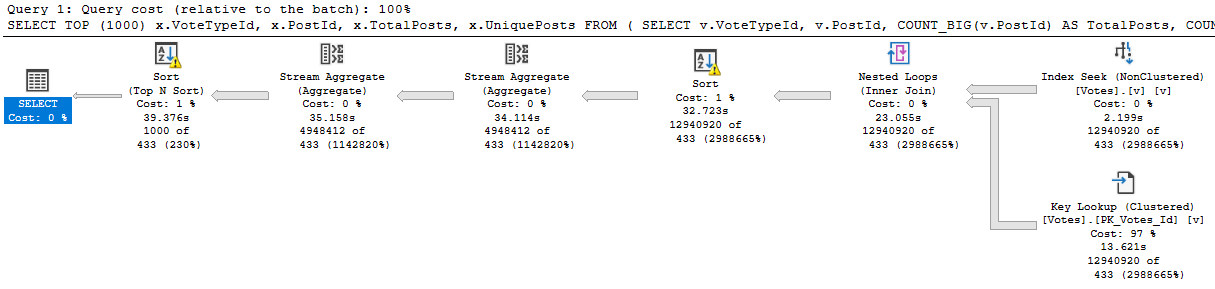
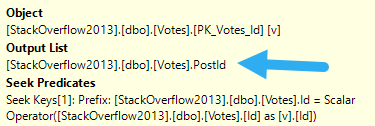
So we need to add that to the index, but where? That’s an interesting question, and we’ll answer it in tomorrow’s post.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.