‘Splainin
When you run a query, the optimizer has a lot to think about. One of those things is if the plan will benefit from parallelism.
That generally happens as long as:
- The plan isn’t trivial — it has to receive full optimization
- Nothing is artificially inhibiting parallelism (like scalar functions or table variable modifications)
- If the serial plan cost is greater than the Cost Threshold For Parallelism (CTFP)
As long as all those qualifications are met, the optimizer will come up with competing parallel plans. If it locates a parallel plan that’s cheaper than the serial plan, it’ll get chosen.
This is determined at a high level by adding up the CPU and I/O costs of each operator in the serial plan, and doing the same for the parallel plan with the added costs of one or more parallel exchanges added in.
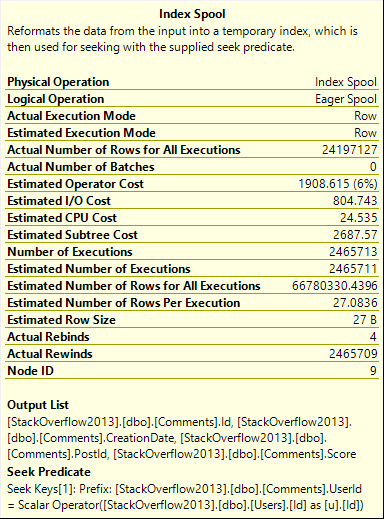
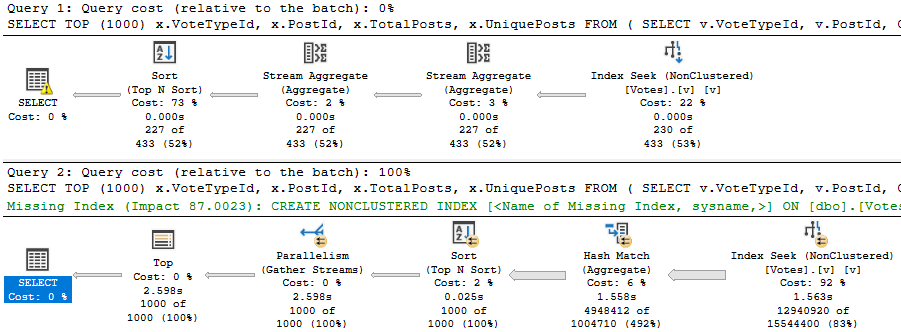
Yesterday we saw a case where the Gather Streams operator was costed quite highly, and it prevented a parallel plan from being chosen, despite the parallel plan in this case being much faster.
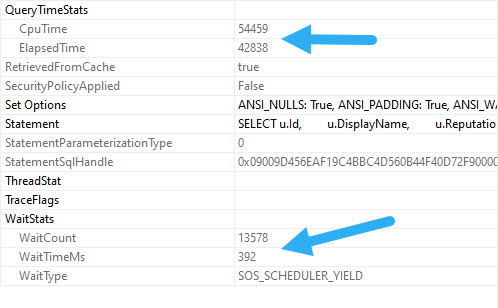
It’s important to note that costing for plans is not a direct reflection of actual time or effort, nor is it accurate to your local configuration.
They’re estimates used to come up with a plan. When you get an actual plan, there are no added-in “Actual Cost” metrics.
How Nested Loops Is Different
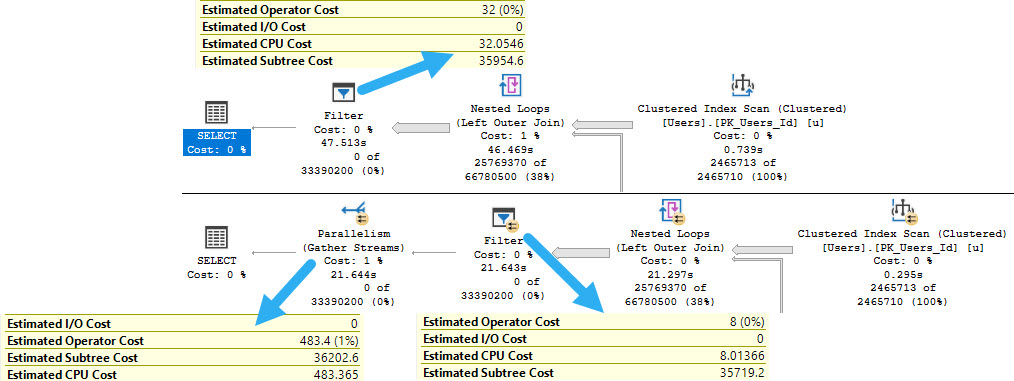
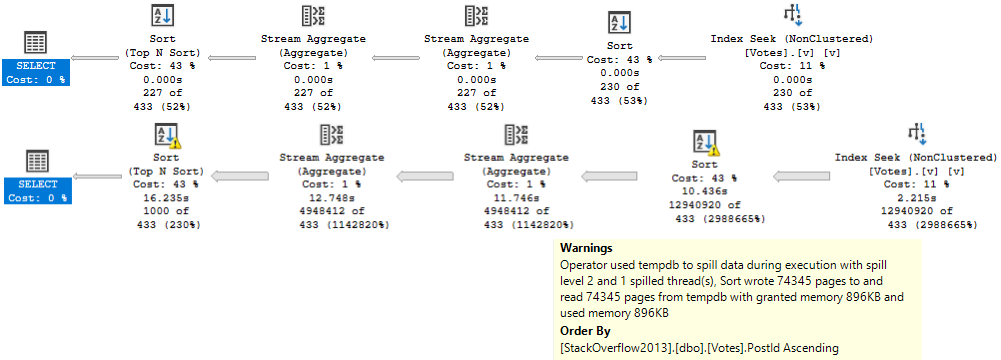
In merge or hash join plans, both sides of the join are part of the costing algorithm to decide if parallelism should be engaged.
An example with a hash join:

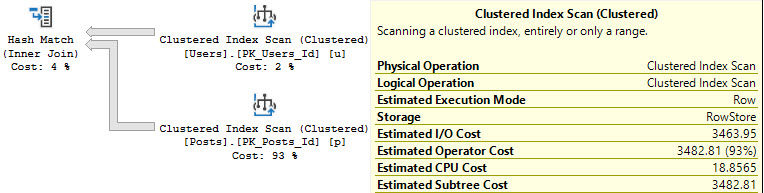
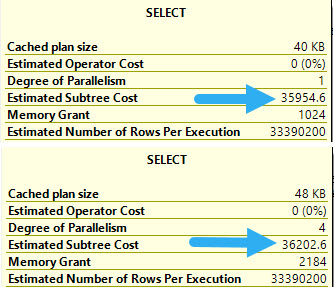
The estimated CPU cost of scanning the Posts table is reduced by 14 or so query bucks. The I/O cost doesn’t change at all.
In this case, it results in a parallel plan being naturally chosen, because the overall plan cost for the parallel plan is cheaper.
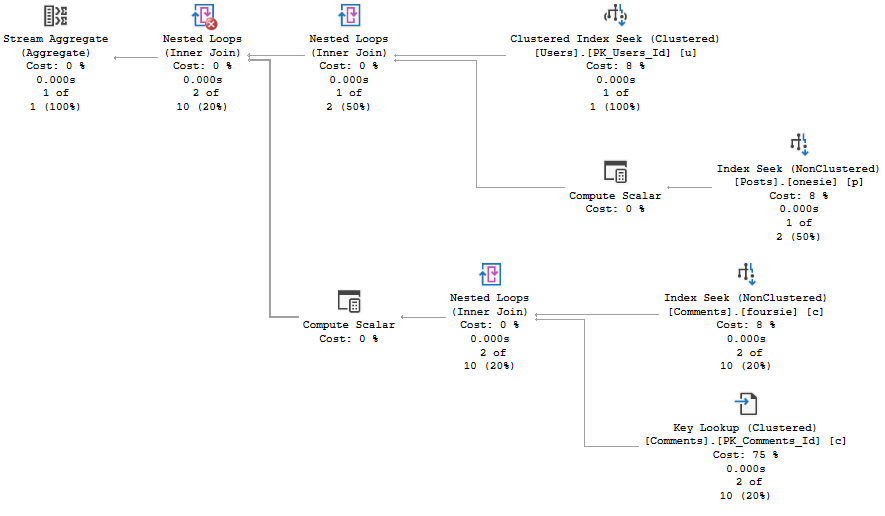
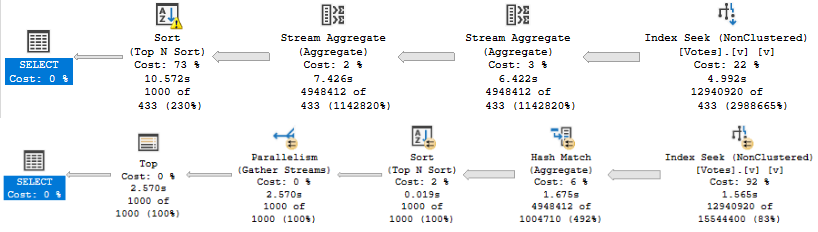
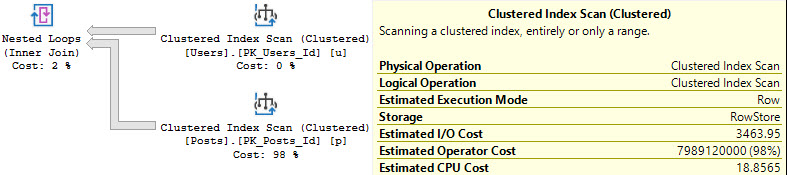
For Nested Loops, it’s different:
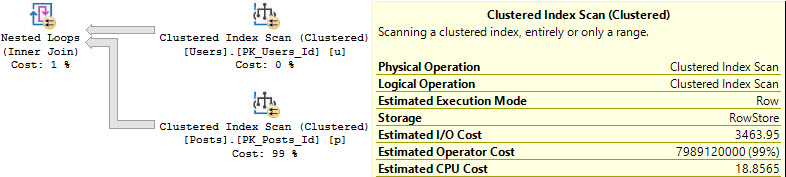
Slashing Prices
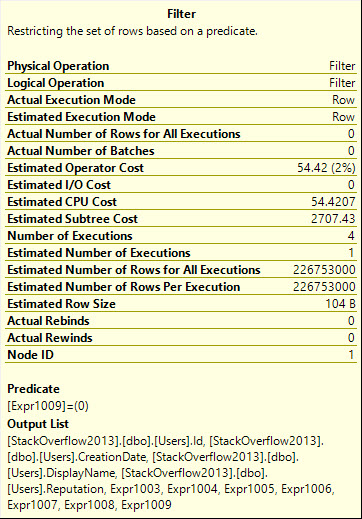
In Nested Loops plans, only the stuff on the outer side of the join experiences a cost reduction by engaging parallelism.
That means that if you’ve got a plan shaped like this that you need to go parallel, you need to figure out how to make the outside as expensive on CPU as possible.
In a lot of cases, you can use ORDER BY to achieve this because it can introduce a Sort operator into the query plan.
Of course, where that Sort operator ends up can change things.
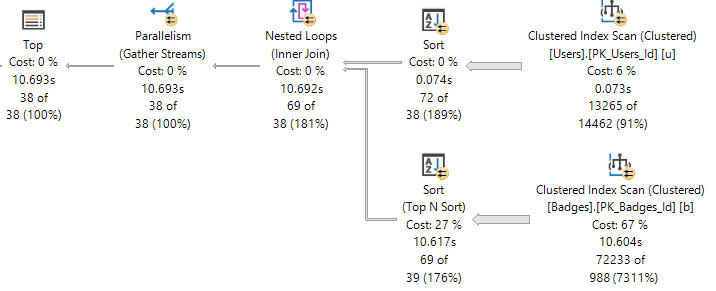
For example, if I ask to order results by Reputation here:
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text --Text in the select list
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0
ORDER BY u.Reputation DESC;
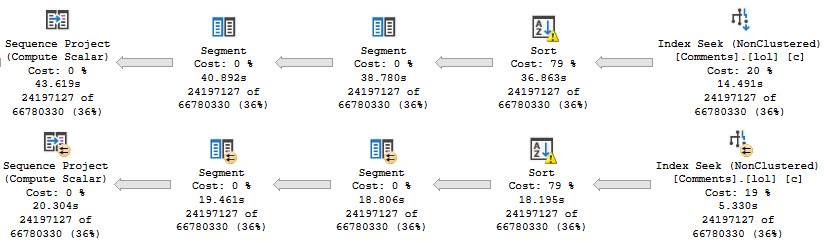
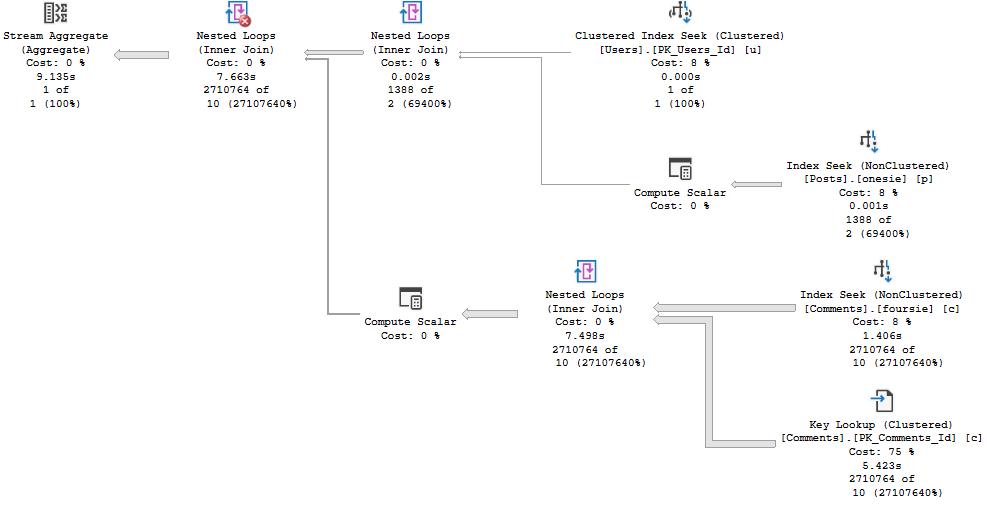
The Sort ends up before the join, and only applies to relatively few rows, and the plan stays serial.

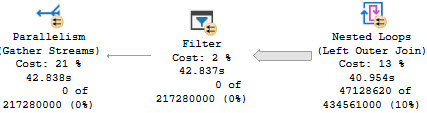
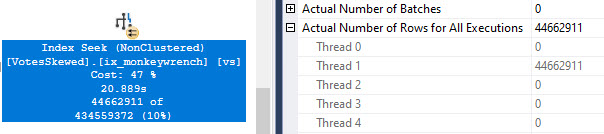
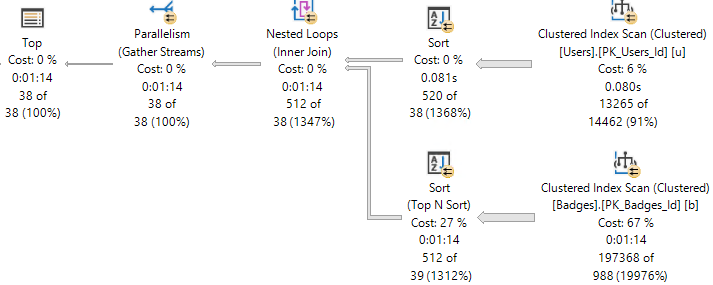
But if I ask for something from inside of the cross apply to be ordered, the number of rows the optimizer expects to have to sort increases dramatically, and so does the cost.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text --Text in the select list
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0
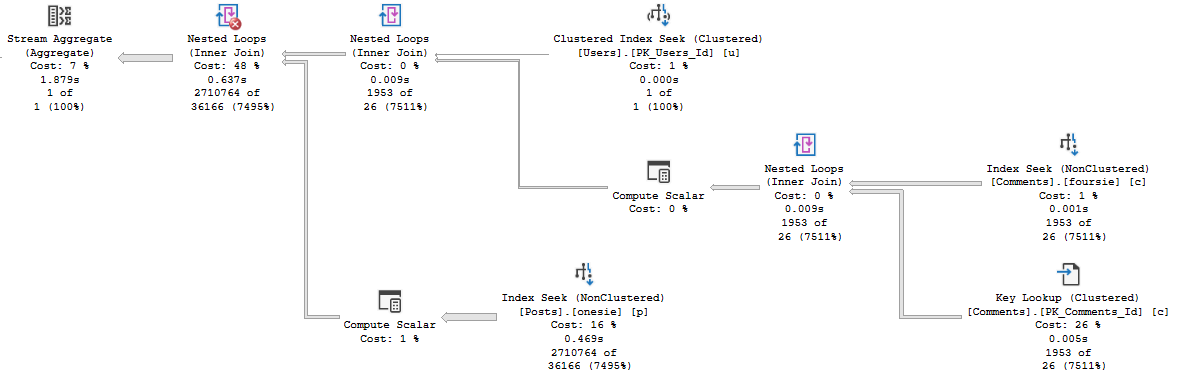
ORDER BY ca.CreationDate DESC;

The additional cost on the outer side tilts the optimizer towards a parallel plan.
There’s No Such Thing As A Free Cool Trick™
This, of course, comes at a cost. While you do gain efficiency in the query finishing much faster, the Sort operator asks for a nightmare of memory.
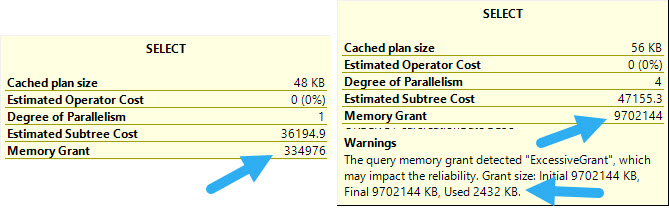
If you have ~10GB of memory to spare for a memory grant, cool. This might be great.
Of course, there are other ways to control memory grants via hints and resource governor, etc.
In some cases, adding an index helps, but if we do that then we’ll lose the added cost and the parallel plan.
Like most things in life, it’s about tradeoffs.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.