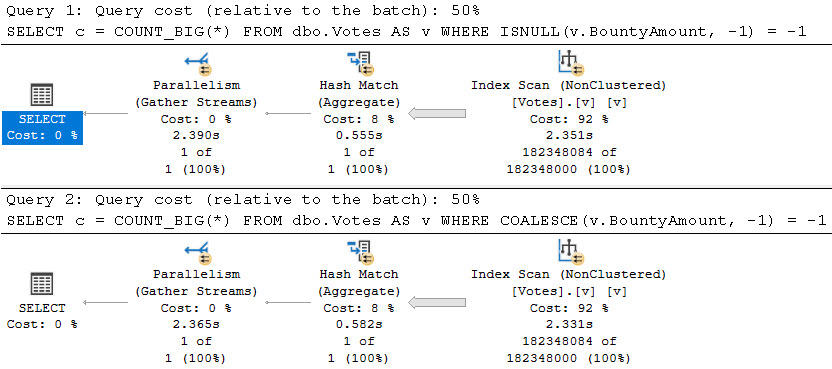
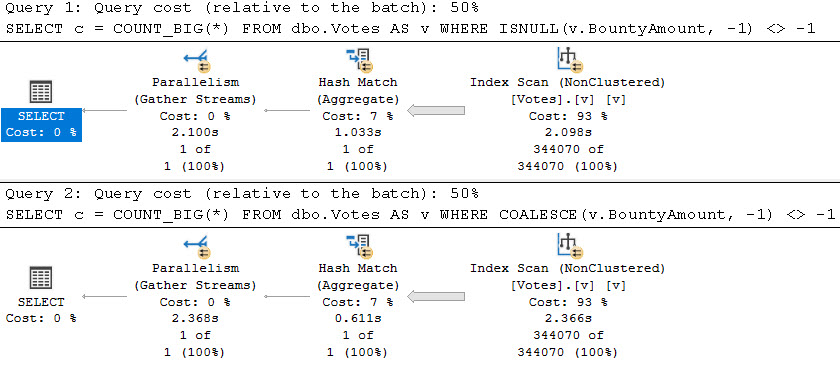
At Microsoft Ignite 2021, public preview for new “premium-series” hardware was announced for Azure SQL Managed Instances. There’s even a black friday sort of sale during this month where you can do testing on premium-series VMs without paying for the compute costs. As someone without free cloud bucks: sign me up!
I did some basic query benchmarking to get an idea of the performance difference between the new premium VMs and the standard gen 5 VMs. The test VMs aren’t identical in specs: the standard-series has 4 vCore with 20.4 GB of memory and the premium-series has 8 vCore with 56 GB of memory. I will attempt to call out any situations where that spec difference had a measurable impact.
What is an Intel 8370C processor?
When I see an Intel CPU model that I’m not familiar with, the first thing I do is try to look it up on the Intel Ark website. Unfortunately, like other cloud specific CPUs, there is no information available there on the Intel 8370C. I did try to ask around but I didn’t get very far. Here’s everything that I know:
- 3rd Generation Intel® Xeon® Scalable Processors
- Ice Lake code name
- At least 24 cores per socket
- 2.8 GHz base
- Turbo clock speed of 3.5GHz
- Intel Turbo Boost Technology 2.0
- Intel AVX-512
- Intel Deep Learning Boost
That will have to do. It’s a bit annoying trying to compare on-prem performance numbers to MI when we don’t have full details about the processor in the cloud, but this seems to be how it is.
What is a Managed Instance vCore?
There are a few things that you need to know in order to put a vCPU or vCore count into perspective:
1) What is the hardware in the physical host? For Managed instances, we know that the gen 5 series physical hosts have Intel E5-2673 v4, SP-8160, or 8272CL processors. For the premium-series, we know that the physical hosts only have Intel 8370C processors. We may not know exactly what those processors are, but we at least have some information.
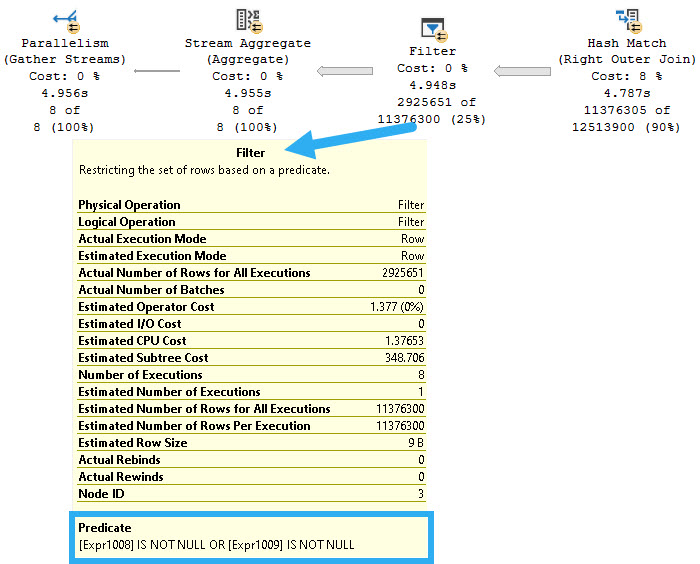
2) How are the logical cores in the VM spread over the physical costs of the physical host? In other words, are 4 vCores generally spread over 2 physical cores on the host or are they spread over a single hyperthread each from four different physical cores? Those configurations will result in very different application throughput. In a blog post that I haven’t written yet, I present evidence that you should think of Managed Instance VMs as being spread over the minimum number of physical cores on the host. In other words, a 4 vCore VM will at most get 2X the throughput of a single query running at MAXDOP 1.
3) How much CPU oversubscription is there at the physical host level? Your VM may be fighting for CPU time with other VMs on the same physical host. With MI, you only have access to the SQL Server instance. As far as I know, there really isn’t a way to tell if your query runtime is getting penalized due to activity by some other VM. I’ve seen query performance degrade on MI instances with nothing else going on. The only way that I know to explain it is some kind of oversubscription at the host level. Note that Microsoft only offers compute isolation for standard-series VMs at 40+ vCores and for premium-series VMs at 64+ vCores.
You might be wondering why I’m writing all of this in a blog post about query performance testing. The reason is simple: CPU time at the individual query level may be a significantly less consistent performance metric on Managed Instances compared to what you’re used to. As an example from this round of testing, the same query used both 1289 ms of CPU and 1929 ms of CPU under conditions that appeared to be identical. Both hyperthreading and VM oversubscription can contribute to “inflated” CPU times. You might be getting time on one of the processor’s logical cores but that time is shared with whatever else may be running on the other logical core. And who even knows what HyperV is doing in terms of scheduling?
With that said, I did not observe the wild variances in CPU time on the premium-series VM. I suspect that this is a property of the public preview nature of the VM. Still, I ran all queries five times each and averaged the results to mitigate the CPU variance problem. When query tuning on Managed Instances in the real world, do note that if your rewrite reduces CPU time by 20%, you may have not accomplished anything. You’ll need to test performance many times or evaluate performance in a different way, perhaps by examining the query plan shape or (gasp!) looking at logical reads.
While Loop Test
The first test that I did was the simple WHILE loop described here. Managed Instances have significant observer overhead for this code compared to a vanilla SQL Server install. Perhaps it has something to do with all of the extended event sessions mentioned in the MI error log. It could be said that testing this T-SQL is really just benchmarking that observer overhead. However, it’s still CPU work, so why not do it?
The premium-series VM took an average of 663 CPU ms compared to 1043 CPU ms for the standard VMs.
Cross Join Test
For the next test case, I wanted to reduce the observer overhead but still execute a CPU-bound query with a minimum of time lost to waits. I decided on the following query which calculates 6.5 million checksums:
SELECT MIN(CHECKSUM(CAST(t1.number AS BIGint) + CAST(t2.number AS BIGint)))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
OPTION (MAXDOP 1, NO_PERFORMANCE_SPOOL);
The query plan isn’t very exciting:
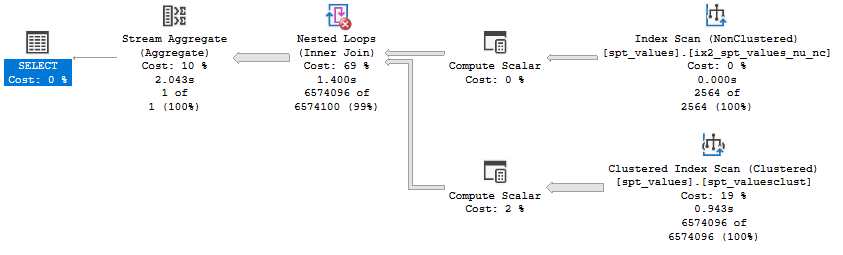
The premium-series VM took an average of 1277 CPU ms compared to 1876 CPU ms for the standard VMs.
Batch Mode Test
I also wanted to run a query that does some batch mode work without spilling to tempdb. I don’t know if it applies here, but in some cases, CPUs with newer instruction sets can get better performance with batch mode operations. First I created a simple CCI:
CREATE TABLE dbo.BatchModeTest (
ID1 BIGINT NOT NULL,
ID2 BIGINT NOT NULL,
ID3 BIGINT NOT NULL,
STRING VARCHAR(100),
INDEX CCI CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.BatchModeTest WITH (TABLOCK)
SELECT q.RN, q.RN, q.RN, REPLICATE('Z', 100)
FROM
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) q
OPTION (MAXDOP 1);
I then tested the performance of the following query:
SELECT COUNT_BIG(DISTINCT ID1)
FROM BatchModeTest
OPTION (MAXDOP 1);
The premium-series VM took an average of 724 CPU ms compared to 1162 CPU ms for the standard VMs.
On a batch mode related note, I observed that Managed Instances don’t seem to have the fix for the “queries on CCIs can get trivial plans which result in no batch mode” issue that was addressed with SQL Server 2017. I sent this feedback to Microsoft and it was received positively, so perhaps there will be an update one day on Managed Instances that addresses that problem. I have to admit that I’m curious as to how such a situation is possible. Are there other fixes that haven’t been ported to the Managed Instance bits yet? Performance tuning in the cloud is difficult enough without the absence of performance fixes implemented years ago in the boxed product!
Application Query Tests
I also tested two of our application queries which are known pain points for our end users. I am not able to share any information about the queries, but you may consider them to be significantly more “real world” compared to the previous tests done so far. As with the other tests conducted so far, both queries used significantly less CPU time on the premium-series managed instance. Here are all of the performance testing results so far:
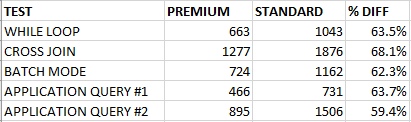
I will note once again that the VMs aren’t identical in specs: the standard-series has 4 vCore with 20.4 GB of memory and the premium-series has 8 vCore with 56 GB of memory. With that said, tempdb spills would have contributed to at most a 30 ms difference in CPU time for the application queries.
Maintenance Tests
By popular demand, I also tested a few maintenance activities. I ran DBCC CHECKTABLE against one of the largest tables in the database. It took 44 seconds to complete on the premium-series and 65 seconds to complete on the standard-series.
Rebuilding an index of a table was more interesting. The premium-series VM took significantly longer than the standard-series: 209 seconds vs 158 seconds. However, the premium-series tests used significantly less CPU: 55 seconds vs 109 seconds. I saw a lot of LOGBUFFER waits on the premium-series VM that weren’t observed on the standard-series. As far as I can tell, storage performance should have been identical between the two VMs. Perhaps I just got unlikely, or maybe the root cause of this difference will be addressed before premium-series VMs become generally available.
Final Thoughts
Based on limited public preview results, the new premium-series VMs are significantly more CPU efficient than the standard-series VMs for several different types of queries. I saw a 40% reduction in CPU time across the board in my testing. Workloads with queries that are CPU bound may be able to reduce their overall vCore count and still see improved query performance by switching to the premium-series VMs. For our workload, based on the information that I have, I would prefer a 24 vCore premium-series VM over a 32 vCore standard-series VM. It’s a cheaper option with slightly more memory and more CPU power. Other workloads that aren’t as CPU bound may not see the same benefits from switching to the Intel 8370C. Perhaps the 15% price premium isn’t worth it in all cases.
For VM sizes that don’t qualify for compute isolation (fewer than 64 vCores), I suspect that these test results are biased in favor of the premium-series. It’s just speculation on my part, but I didn’t see the kind of oversubscription at the host level with the premium-series that I’m used to seeing on the standard-series MI VMs. It is possible that the premium-series VMs will have less of a performance advantage compared to the standard-series once they become generally available.
I’ll add that databases platforms, and software in general, are supposed to serve us and make our lives easier. Too often it feels like we’re the ones serving the database platforms instead. That’s part of why I’m such a big advocate for using the right hardware for your important relational database workloads. It’s really hard to get excited when spinning up a new Managed Instance VM only to get something on an E5-2673 v4 physical host. That doesn’t sound like the right hardware to me.
Thanks for reading!