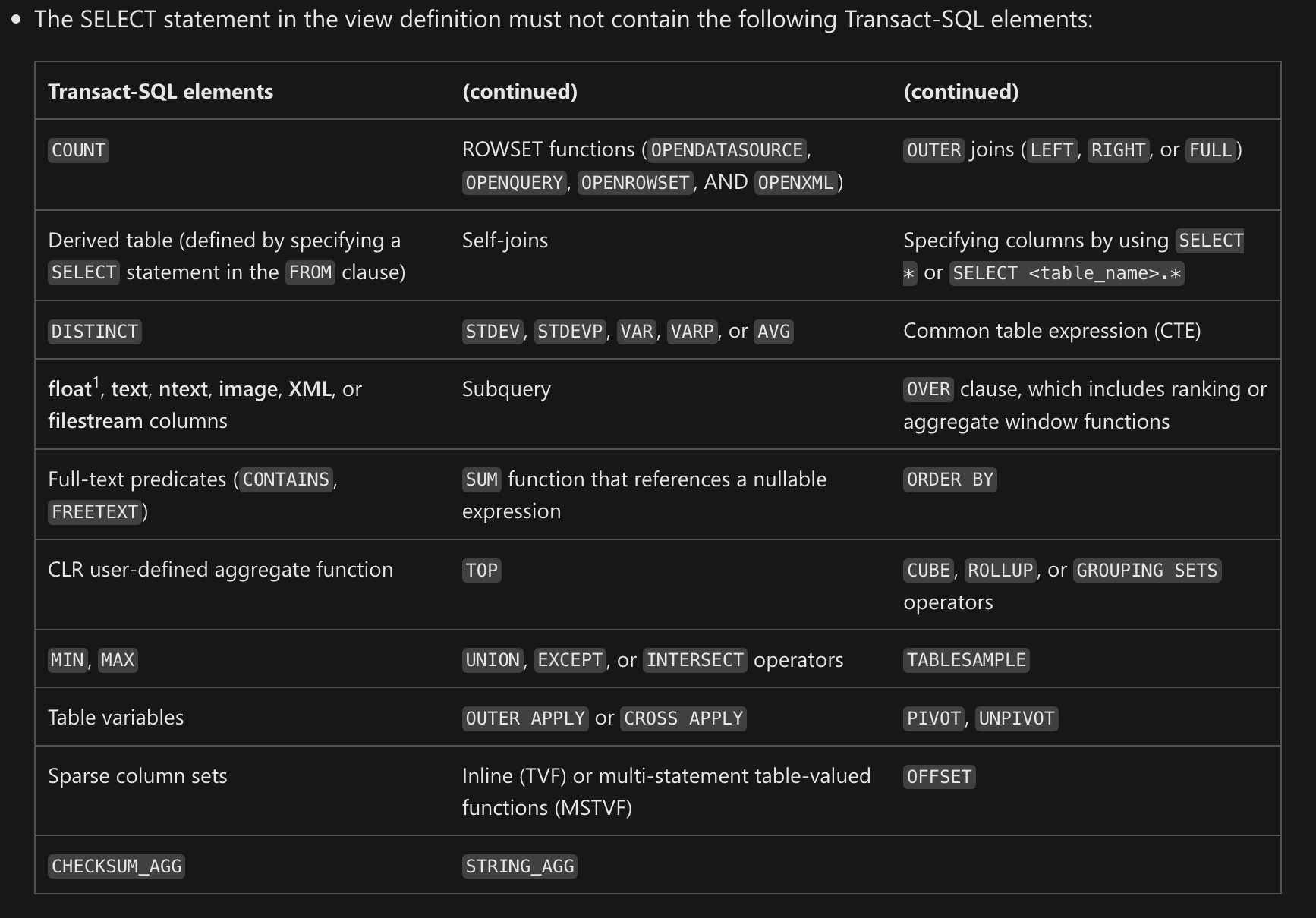
This is a list of things I see in data warehouses that make me physically ill:
Unique constraints of any kind: Primary Keys, Indexes, etc. Make things unique during your staging process. Don’t make your indexes do that work.
Foreign Keys: Referential integrity should be guaranteed from your data source. If it can’t be, there’s no sense in making it happen in your data warehouse. Foreign Keys in SQL Server suck anyway, and slow the hell out of large data loads.
Clustered row store indexes: At this point in time, when you need a clustered index, it ought to be a clustered column store index.
Tables with “lots” of nonclustered row store indexes: They’ll only slow down your load times a whole bunch. Replace them with nonclustered column store indexes.
Standard Edition: The CPU limit of 24 cores is probably fine, but the buffer pool cap of 128GB and strict limitations on column store/batch mode are horrendous.
I know what you’re thinking looking at this list: I can drop and re-create things like unique constraints, foreign keys, and nonclustered indexes. You sure can, but you’re wasting a ton of time.
Data warehouses have a completely different set of needs from transaction systems. The sooner you stop treating data warehouses like AdventureWorks, the better.
That’s all.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Normally people handle errors to… handle errors. But I came across someone doing something sort of interesting recently.
Before we talk about that, let’s talk about the more normal way of capturing errors from T-SQL:
CREATE OR ALTER PROCEDURE
dbo.error_muffler
(
@i int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
SELECT
x = 1/@i;
END TRY
BEGIN CATCH
/*Do some logging or something?*/
THROW;
END CATCH;
END;
So if we execute our procedure like this, it’ll throw a divide by zero error:
EXEC dbo.error_muffler
@i = 0;
Msg 8134, Level 16, State 1, Procedure dbo.error_muffler, Line 12 [Batch Start Line 33]
Divide by zero error encountered.
Well, good. That’s reasonable.
Empty Iterator
What I recently saw someone doing was using an empty catch block to suppress errors:
CREATE OR ALTER PROCEDURE
dbo.error_muffler
(
@i int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
SELECT
x = 1/@i;
END TRY
BEGIN CATCH
/*Nothing here now*/
END CATCH;
END;
GO
So if you execute the above procedure, all it returns is an empty result with no error message.
Kinda weird.
Like not having finger or toenails.
Trigger Happy
Of course (of course!) this doesn’t work for triggers by default, because XACT_ABORT is on by default..
CREATE TABLE
dbo.catch_errors
(
id int NOT NULL
);
GO
CREATE OR ALTER TRIGGER
dbo.bury_errors
ON
dbo.catch_errors
AFTER INSERT
AS
BEGIN
BEGIN TRY
UPDATE c
SET c.id = NULL
FROM dbo.catch_errors AS c;
END TRY
BEGIN CATCH
END CATCH;
END;
GO
If we try to insert a row here, we’ll get a really weird error message, unswallowed.
INSERT
dbo.catch_errors
(
id
)
VALUES
(
1
);
Womp:
Msg 3616, Level 16, State 1, Line 29
An error was raised during trigger execution. The batch has been aborted and the user transaction, if any, has been rolled back.
If we were to SET XACT_ABORT OFF; in the trigger definition, it would work as expected.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is advice that I have to give less frequently these days, but is absolutely critical when I do.
With SQL Server 2016, suggestions that I’d normally make to folks became the default behavior
1117 and 1118 for tempdb performance and contention
2371 for stats update threshold improvements on large tables
By far the most common trace flag that I still have to get turned on is 8048. Please read the post at the link before telling me that it’s not necessary.
There are a lot of trace flags that I usually have people turn off, too. Most common at the 12XX trace flags that stick deadlock information in the error log.
There are far better ways to get at that information these days, like using the system health extended event session.
Lessen Earned
There are query-level trace flags that make sense sometimes, too as part of query tuning and experimentation.
Some of these have been replaced by written hints, too:
8649 can be replaced by OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));
8690 can be replaced by OPTION(NO_PERFORMANCE_SPOOL);
Others are quite interesting to get more details about the optimization process. They almost all require 3604 to be used as well, to output messages the to console.
2315: Memory allocations taken during compilation
2363: (2014+) Statistics Info
2372: Shows memory utilization during the different optimization stages
2373: Shows memory utilization while applying optimization rules and deriving properties
7352: Show final query tree (post-optimization rewrites)
8605: Initial query tree
8606: Additional LogOp trees
8607: Optimizer output tree
8608: Input tree copied into memo
8609: Operation counts
8612: Extra LogOp info
8615: Final memo
8619: Applied transformation rules
8620: Add memo arguments to trace flag 8619
8621: Rule with resulting tree
8670: Disables Search2 phase of optimization
8671: Disables logic that prunes memo and prevents optimizer from stopping due to “Good Enough Plan found”
8675: Optimization phases and timing
8757: Disable trivial plan generation
9204: Interesting statistics loaded (< 2014)
9292: Interesting statistics (< 2014)
If this all seems daunting, it’s because it is. And in most cases, it should be. But like… Why not make trace flags safeguards?
Diagnostic
Microsoft creates trace flags to change default product behavior, often to solve a problem.
If you read through a cumulative update patch notes, you might find some documentation (no seriously, stop laughing) that says you need to apply the CU and enable a trace flag to see a problem get resolved.
It would be nice if SQL Server were a bit more proactive and capable of self-healing. If the issue at hand is detected, why not enable the trace flag automatically? There’s no need for it to act like a sinking ship.
I get that it’s not feasible all the time, and that some of them truly are only effective at startup (but that seems like something that could be done, too).
When you run many online transactions on a database in Microsoft SQL Server 2019, you notice severe spinlock contention. The severe contention is generally observed on new generation and high-end systems. The following conditions apply to severe spinlock contention:
Requires modern hardware, such as Intel Skylake processors
Requires a server that has many CPUs
Requires a high number of concurrent users
Symptoms may include unexpected high CPU usage
Okay, some of this stuff can be (or is interrogated at startup as part of Hekaton checks). Maybe some is subjective, like what constitutes a high number of concurrent users, or CPU.
But there’s more!
Note In SQL Server 2019 Cumulative Update 16, we fixed spinlock contention on SPL_HOBT_HASH and SPL_COMPPLAN_SKELETON.
Okay, and…
Note Trace flag 8101 has to be turned on to enable the fix.
That seems far less subjective, and a good opportunity to self-heal a little bit. Flip the switch, SQL Server.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Third party monitoring tools are in rough shape these days. That’s all I’m gonna say about the situation. I get enough letters from lawyers on account of my BTS fanfic sites.
With that out of the way, let’s talk about something you can do to get a handle on which queries are having problems: Enable Query Store.
You can do that using this command:
ALTER DATABASE
[YourDatabase]
SET QUERY_STORE
(
OPERATION_MODE = READ_WRITE,
MAX_STORAGE_SIZE_MB = 1024,
QUERY_CAPTURE_MODE = AUTO
);
The reason I use this command specifically us because it will override some bad defaults that have been corrected over various service packs and cumulative updates.
You know what I hate doing? Stopping to look at which service packs and cumulative updates fixed certain Query Store defaults.
The important things that this script does is:
Turn on Query Store
Give it a decent amount of space to store data in
Not capture every single tiny little query that runs
What a nice setup.
Okay, Now What?
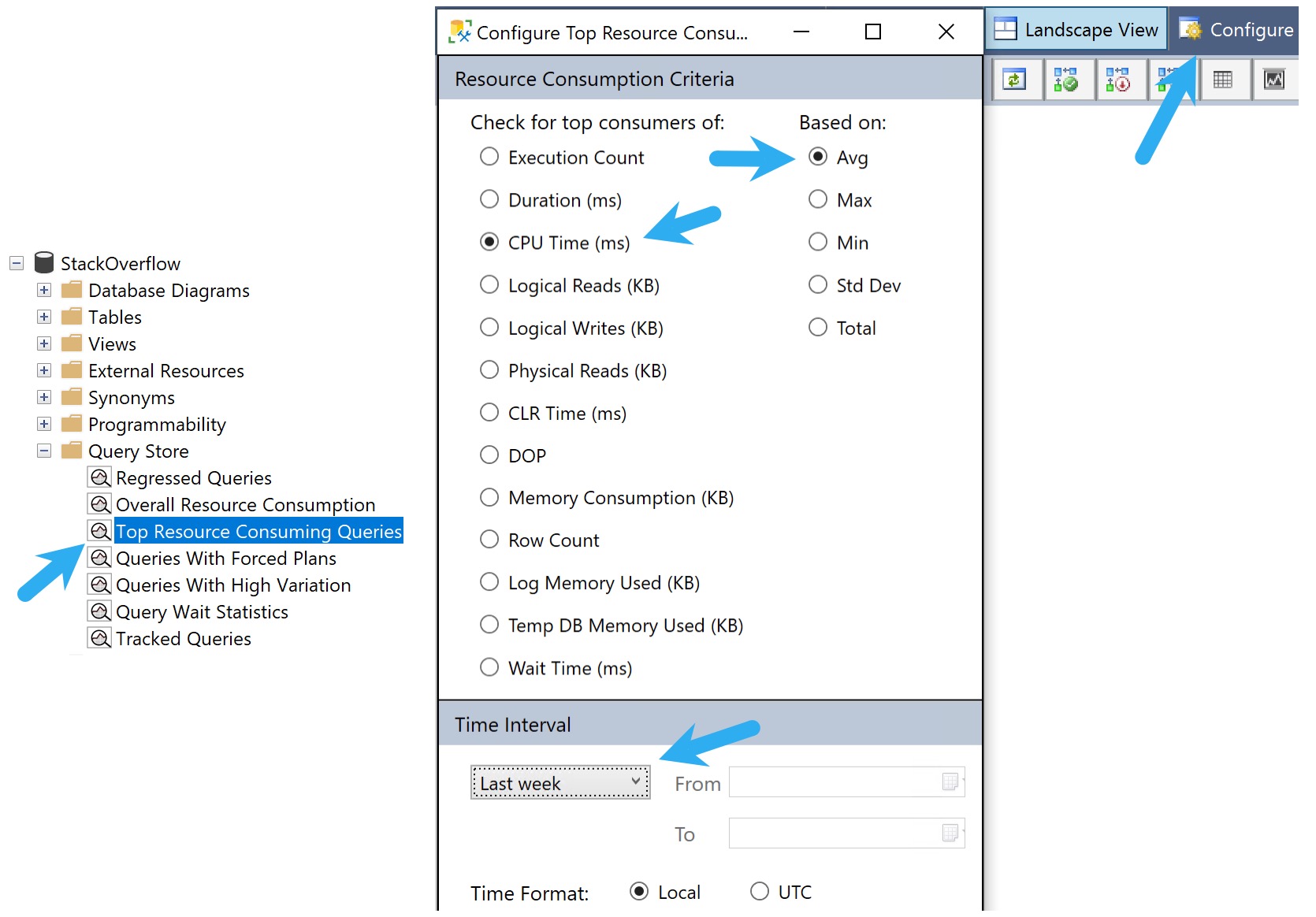
Once Query Store is enabled, assuming the goal is to track down and solve performance problems, the easiest way to start digging in is the GUI.
I usually go into Top Resource Consuming Queries, then look at what used the most average CPU over the last week.
cherry
This view won’t tell you everything of course, but it’s a good starting place.
Okay, But I Need More
The GUI itself right now doesn’t allow for much beyond showing you the top whatever by whatever for whenever. If you want to search through Query Store data for specific plan or query IDs, procedure names, or query text, you’ll need to use my free script sp_QuickieStore.
To get you started, here are a bunch of example commands:
--Get help!
EXEC dbo.sp_QuickieStore
@help = 1;
--Find top 10 sorted by memory
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@sort_order = 'memory',
@top = 10;
--Search for specific query_ids
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@top = 10,
@include_query_ids = '13977, 13978';
--Search for specific plan_ids
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@sort_order = 'memory',
@top = 10,
@start_date = '20210320',
@include_plan_ids = '1896, 1897';
--Ignore for specific query_ids
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@top = 10,
@ignore_query_ids = '13977, 13978';
--Ignore for specific plan_ids
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@sort_order = 'memory',
@top = 10,
@start_date = '20210320',
@ignore_plan_ids = '1896, 1897';
--Search for queries within a date range
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@sort_order = 'memory',
@top = 10,
@start_date = '20210320',
@end_date = '20210321';
--Search for queries with a minimum execution count
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@top = 10,
@execution_count = 10;
--Search for queries over a specific duration
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@top = 10,
@duration_ms = 10000;
--Search for a specific stored procedure
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@procedure_name = 'top_percent_sniffer';
--Search for specific query tex
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@query_text_search = 'WITH Comment'
--Use expert mode to return additional columns
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@sort_order = 'memory',
@top = 10,
@expert_mode = 1;
--Use format output to add commas to larger numbers
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@sort_order = 'memory',
@top = 10,
@format_output = 1;
--Use wait filter to search for queries responsible for high waits
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@wait_filter = 'memory',
@sort_order = 'memory';
--Troubleshoot performance
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@troubleshoot_performance = 1;
--Debug dynamic SQL and temp table contents
EXEC dbo.sp_QuickieStore
@database_name = 'StackOverflow2013',
@debug = 1;
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I need to start this post off by saying something that may not be obvious to you: Not all parameter sniffing is bad.
Sure, every time you hear someone say “parameter sniffing” they want to teach you about something bad, but there’s a lot more to it than that.
Parameter sniffing is normally great. You heard me. Most of the time, you don’t want SQL Server generating new query plans all the time.
And yet I see people go to extreme measures to avoid parameter sniffing from ever happening, like:
Local variables
Recompiling
What you care about is parameter sensitivity. That’s when SQL Server comes up with totally different execution plans for the same query depending on which parameter value it gets compiled with. In those cases, there’s usually a chance that later executions with different parameter values don’t perform very well using the original query plan.
The thing is, sometimes you need to introduce potentially bad parameter sensitivity in order to fix other problems on a server.
What’s Your Problem?
The problem we’re trying to solve here is application queries being sent in with literal values, instead of parametrized values.
The result is a plan cache that looks like this:
unethical
Of course, if you can fix the application, you should do that too. But fixing all the queries in an application can take a long time, if you even have access to make those changes, or a software vendor who will listen.
The great use case for this setting is, of course, that it happens all at once, unless you’re doing weird things.
You can turn it on for a specific database by running this command:
ALTER DATABASE
[YourDatabase]
SET PARAMETERIZATION FORCED;
Good or Bad?
The argument for doing this is to drastically reduce CPU from queries constantly compiling query plans, and to reduce issues around constantly caching and evicting plans, and creating an unstable plan cache.
Of course, after you turn it on, you now open your queries up to parameter sensitivity issues. The good news is that you can fix those, too.
99% of parameter sniffing problems I see come down to indexing issues.
Non-covering indexes that give the optimizer a choice between Seek + Lookup and Clustered Index Scan
Lots of single key column indexes that don’t make sense to use across different searches
Suboptimal indexes suggested by various tooling that got implemented without any critical oversight
And of course, if you’ve got Query Store enabled, you can pretty easily force a plan.
Speaking of which, I still have to talk a lot of folks into turning that on, too. Let’s talk about that tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thing I really hate about Standard Edition is the lack of a way to globally reduce the allowed memory grant default.
Out of the box, any query can come along and ask for ~25% of your server’s max server memory setting, and SQL Server is willing to loan out ~75% at once across a bunch of queries.
That impacts Standard Edition users way more than Enterprise Edition users, because of the Standard Edition buffer pool limit of 128GB.
A lot of folks misinterpret that limit — I’ve had several exchanges with big name hardware vendors where they insist 128GB is the overall RAM limit, so you’re likely getting bad advice from everywhere — and they end up with a server that only has 128GB of RAM in it.
Big mistake. Bump that up to 192GB and set Max Server Memory to ~180GB or so.
But I digress. Or whatever the word if for getting back to the real point.
I forget, if I ever knew.
Control Top
For all you high rollers out there on Enterprise Edition, you have an easy way to fight against SQL Server’s bad memory grant habits.
Before we do that, it’s important to make a few notes here:
SQL Server introduced batch mode memory grant feedback in 2016
SQL Server introduced batch mode on row store in 2019
Depending on your compatibility level, you may not be taking advantage of those things, but in either case the feedback might be kicking in too late. See, it’s not a runtime decision, it’s a decision that takes place after a query runs.
By then, it’s already sucked up 25% of your memory and probably stolen a whole bunch of space from your precious buffer pool. A properly filled buffer pool is important so your queries don’t get dry-docked going out to slowpoke disk all the live long day.
A lot of the time, folks I work with will have a ton of queries asking for bunk memory grants that are way bigger than they should be.
You can use this query to examine your plan cache for those things.
WITH
unused AS
(
SELECT TOP (100)
oldest_plan =
MIN(deqs.creation_time) OVER(),
newest_plan =
MAX(deqs.creation_time) OVER(),
deqs.statement_start_offset,
deqs.statement_end_offset,
deqs.plan_handle,
deqs.execution_count,
deqs.max_grant_kb,
deqs.max_used_grant_kb,
unused_grant =
deqs.max_grant_kb - deqs.max_used_grant_kb,
deqs.min_spills,
deqs.max_spills
FROM sys.dm_exec_query_stats AS deqs
WHERE (deqs.max_grant_kb - deqs.max_used_grant_kb) > 1024.
AND deqs.max_grant_kb > 5242880.
ORDER BY
unused_grant DESC
)
SELECT
plan_cache_age_hours =
DATEDIFF
(
HOUR,
u.oldest_plan,
u.newest_plan
),
query_text =
(
SELECT [processing-instruction(query)] =
SUBSTRING
(
dest.text,
( u.statement_start_offset / 2 ) + 1,
(
(
CASE u.statement_end_offset
WHEN -1
THEN DATALENGTH(dest.text)
ELSE u.statement_end_offset
END - u.statement_start_offset
) / 2
) + 1
)
FOR XML PATH(''),
TYPE
),
deqp.query_plan,
u.execution_count,
u.max_grant_kb,
u.max_used_grant_kb,
u.min_spills,
u.max_spills,
u.unused_grant
FROM unused AS u
OUTER APPLY sys.dm_exec_sql_text(u.plan_handle) AS dest
OUTER APPLY sys.dm_exec_query_plan(u.plan_handle) AS deqp
ORDER BY
u.unused_grant DESC
OPTION (RECOMPILE, MAXDOP 1);
If you have a bunch of those, and you want a quick fix until you can do more meaningful query and index tuning, you can use Resource Governor to reduce the 25% default to a lower number.
Scripted, For Your Pleasure
You can use this script to enable and reconfigure Resource Governor to use a lower memory grant percent.
/*The first time enables Resource Governor*/
ALTER RESOURCE GOVERNOR
RECONFIGURE;
/*This reduces the memory grant cap to 10%*/
ALTER WORKLOAD GROUP
[default]
WITH
(
REQUEST_MAX_MEMORY_GRANT_PERCENT = ?
);
/*This completes the change*/
ALTER RESOURCE GOVERNOR
RECONFIGURE;
You’ll have to fill in the question mark yourself, of course. Without looking at your system, I have no idea what it should be.
If you’d like help with that, hit the link below to schedule a sales call.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One of the very first performance problems that developers will run into when using SQL Server is locking, and often deadlocks.
Though deadlocks have their root in (b)locking behavior, not all blocking leads to deadlocks.
Some (b)locking will just go on forever, ha ha ha.
The reason there are so many SQL Server blog posts about NOLOCK hints, and so much confusion about what it does, is because of defaults.
The worst part that it’s a default that shouldn’t be, and… somehow people have this sunny view of what NOLOCK does, but they all have a very negative view of better solutions to the problem.
What NOLOCK Really Does
I have this conversation at least twice a week, despite having written about it plenty of times.
And other people writing about it many times.
For years.
It does not mean your query doesn’t take locks, it means your query doesn’t respect locks taken by other queries. It’s not that read committed is so great, it’s that read uncommitted is so bad.
As soon as the drive reaches infinite Improbability, it passes through every conceivable point in every conceivable universe simultaneously. An incredible range of highly improbable things can happen due to these effects.
Perhaps not quite that eccentric, but you get the idea. While a modification in flight, a query with a NOLOCK (or READ UNCOMMITTED) hint may read those changes while they’re happening.
Incomplete inserts
Incomplete deletes
Incomplete updates
Inserts and deletes are a bit more straight forward. Say you’re inserting or deleting 10 rows, and either one is halfway done when your select query that is running with flaming knives and scissors a NOLOCK hint comes along.
You would read:
The first five inserted rows
The remaining five rows to be deleted
For updates, things are a little trickier because you might end up with an in-place update or per-index update.
You can read:
Partially changed rows
From an index that hasn’t been modified yet
Something in between
This is not what you want to happen.
Even if you have a million excuses as to why it works okay for you (it’s just a mobile app; they can refresh, we only need close-enough reports; users make changes and then read them later) I promise you that it’s not something you want to happen, because you can’t fully predict the ramifications of many concurrent modifications and selects running all together.
What You Really Want To Happen Instead
The utter beauty of these solutions is that they give you reliable results. They may not be perfect for every situation, but for probably like 99% of cases where you’re using NOLOCK hints everywhere anyway, they do.
Rather than futz about with the Infinite Improbabilities that could be read from modifications that are neither here nor there but are certainly not completed, you read the last known good version of a row or set of rows that are currently locked.
There you have it! No more uncertainty, puzzled users, additional database requests to refresh wonky-looking data, or anything like that.
It’s just you and your crisp, clean data.
If you’re on SQL Server 2019 and using Accelerated Database Recovery, the known-good versions of your precious data will be stored locally, per-database.
In all other scenarios, the row versioning goes off to tempdb.
Your select queries can read that data without being impeded by locks, and without all of incorrectness.
What options do you have to take advantage of these miraculous functionalities?
Those sound pretty close, but let’s talk a little bit more about them.
Isolation Levels, Not In Depth
It’s difficult to cover every potential reservation or concern someone may have about isolation levels. If you have an application that depends on certain locking guarantees to correctly process certain events, you may need read committed, or something beyond read committed (like repeatable read or serializable) to hold the correct locks.
If that’s your app design, then your job becomes query and index tuning to make sure that your queries run as quickly as possible to reduce the locking surface area of each one. This post is not for you.
This post is largely geared towards folks who have NOLOCK everywhere like some sort of incantation against performance problems, who hopefully aren’t totally stuck in their ways.
Here are some of the potential downsides of optimistic isolation levels:
Prior to SQL Server 2019, you’re going to add some load to tempdb
If you’re currently using NOLOCK everywhere, or if someone starts suggesting you use it everywhere for better performance, know that you have better options out there.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the age of column store indexes, indexed views have a bit less attractiveness about them. Unless of course you’re on Standard Edition, which is useless when it comes to column store.
I think the biggest mark in favor of indexed views over column store in Standard Edition is that there is no DOP restriction on them, where batch mode execution is limited to DOP 2.
One of the more lovely coincidences that has happened of late was me typing “SQL Server Stranded Edition” originally up above.
Indeed.
There are some good use cases for indexed views where column store isn’t a possibility, though. What I mean by that is they’re good at whipping up big aggregations pretty quickly.
Here are some things you oughtta know about them before trying to use them, though. The first point is gonna sound really familiar.
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
QUOTED_IDENTIFIER ON
ANSI_NULLS ON
ANSI_PADDING ON
ANSI_WARNINGS ON
ARITHABORT ON
CONCAT_NULL_YIELDS_NULL ON
NUMERIC_ROUNDABORT OFF
Second, you’ll wanna use the NOEXPAND hint when you touch an indexed view. Not only because that’s the only way to guarantee the view definition doesn’t get expanded by the optimizer, but also because (even in Enterprise Edition) that’s the only way to get statistics generated on columns in the view.
If you’ve ever seen a warning for missing column statistics on an indexed view, this is likely why. Crazy town, huh?
Third, indexed views maintain changes behind the scenes automatically, and that maintenance can really slow down modifications if you don’t have indexes that support the indexed view definition.
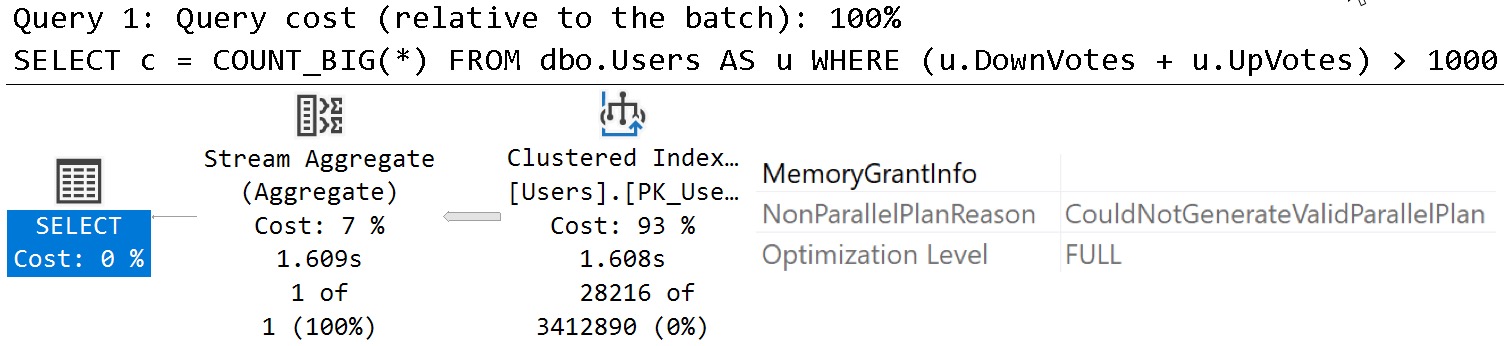
Eighth, if your indexed view has an aggregation in it, you need to have a COUNT_BIG(*) column in the view definition.
Buuuuuut, if you don’t group by anything, you don’t need one.
Ninth, yeah, you can’t use DISTINCT in the indexed view, but if you can use GROUP BY, and the optimizer can match queries that use DISTINCT to your indexed view.
CREATE OR ALTER VIEW
dbo.shabu_shabu
WITH SCHEMABINDING
AS
SELECT
u.Id,
u.DisplayName,
u.Reputation,
Dracula =
COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation > 100000
GROUP BY
u.Id,
u.Reputation,
u.DisplayName;
GO
CREATE UNIQUE CLUSTERED INDEX
cuqadoodledoo
ON dbo.shabu_shabu
(
Id
);
SELECT DISTINCT
u.Id
FROM dbo.Users AS u
WHERE u.Reputation > 100000;
Ends up with this query plan:
balance
Tenth, the somewhat newly introduced GREATEST and LEAST functions do work in indexed views, which certainly makes things interesting.
I suppose that makes sense, since they’re probably just CASE expressions internally, but after everything we’ve talked about, sometimes it’s surprising when anything works.
Despite It All
When indexed views are the right choice, they can really speed up a lot of annoying aggregations among their other utilities.
This week we talked a lot about different things we can do to tables to make queries faster. This is stuff that I end up recommended pretty often, but there’s even more stuff that just didn’t make the top 5 cut.
Next week we’ll talk about some database and server level settings that can help fix problems that I end up telling clients to flip the switch on.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Remember yesterday? Yeah, me either. But I do have access to yesterday’s blog post, so I can at least remember that.
What a post that was.
We talked about filtered indexes, some of the need-to-know points, when to use them, and then a sad shortcoming.
Today we’re going to talk about how to overcome that shortcoming, but… there’s stuff you need to know about these things, too.
We’re gonna start off with some Deja Vu!
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
QUOTED_IDENTIFIER ON
ANSI_NULLS ON
ANSI_PADDING ON
ANSI_WARNINGS ON
ARITHABORT ON
CONCAT_NULL_YIELDS_NULL ON
NUMERIC_ROUNDABORT OFF
Second, computed columns are sort of like regular columns: you can only search them efficiently if you index them.
This may come as a surprise to you, but indexes put data in order so that it’s easier to find things in them.
The second thing you should know about the second thing here is that you don’t need to persist computed columns to add an index to them, or to get statistics generated for the computed values (but there are some rules we’ll talk about later).
For example, let’s say you do this:
ALTER TABLE dbo.Users ADD TotalVotes AS (UpVotes + DownVotes);
CREATE INDEX u ON dbo.Users (TotalVotes) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
The index gets created just fine. This is incredibly handy if you need to add a computed column to a large table, because there won’t be any blocking while adding the column. The index is another matter, depending on if you’re using Enterprise Edition.
Third, SQL Server is picky about them, kind of. The problem is a part of the query optimization process called expression matching that… matches… expressions.
For example, these two queries both have expressions in them that normally wouldn’t be SARGable — meaning you couldn’t search a normal index on (Upvotes, Downvotes) efficiently.
But because we have an indexed computed column, one of them gets a magic power, and the other one doesn’t.
Because it’s backwards.
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.UpVotes + u.DownVotes) > 1000;
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.DownVotes + u.UpVotes) > 1000;
connection
See what happens when you confuse SQL Server?
If you have full control of the code, it’s probably safer to reference the computed column directly rather than rely on expression matching, but expression matching can be really useful when you can’t change the code.
Fourth, don’t you ever ever never ever ever stick a scalar UDF in a computed column or check constraint. Let’s see what happens:
CREATE FUNCTION dbo.suck(@Upvotes int, @Downvotes int)
RETURNS int
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
RETURN (SELECT @Upvotes + @Downvotes);
END;
GO
ALTER TABLE dbo.Users ADD TotalVotes AS dbo.suck(UpVotes, DownVotes);
CREATE INDEX u ON dbo.Users (TotalVotes) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.DownVotes + u.UpVotes) > 1000;
Remember that this is the query that has things backwards and doesn’t use the index on our computed column, but look what happened to the query plan:
me without makeup
Querying a completely different index results in a plan that SQL Server can’t parallelize because of the function.
Fifth: Column store indexes are weird with them. There’s an odd bit of a matrix, too.
Anything before SQL Server 2017, no dice
Any nonclustered columnstore index through SQL Server 2019, no dice
For 2017 and 2019, you can create a clustered columnstore index on a table with a computed column as long as it’s not persisted
--Works
CREATE TABLE clustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date));
CREATE CLUSTERED COLUMNSTORE INDEX c ON dbo.clustered_columnstore;
--Doesn't work
CREATE TABLE nonclustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date));
CREATE NONCLUSTERED COLUMNSTORE INDEX n ON dbo.nonclustered_columnstore(id, some_date, next_date, diff_date);
--Clean!
DROP TABLE dbo.clustered_columnstore, dbo.nonclustered_columnstore;
--Doesn't work, but throws a misleading error
CREATE TABLE clustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date) PERSISTED);
CREATE CLUSTERED COLUMNSTORE INDEX c ON dbo.clustered_columnstore;
--Still doesn't work
CREATE TABLE nonclustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date) PERSISTED);
CREATE NONCLUSTERED COLUMNSTORE INDEX n ON dbo.nonclustered_columnstore(id, some_date, next_date, diff_date);
--Clean!
DROP TABLE dbo.clustered_columnstore, dbo.nonclustered_columnstore;
General Uses
The most general use for computed columns is to materialize an expression that a query has to filter on, but that wouldn’t otherwise be able to take advantage of an index to locate rows efficiently, like the UpVotes and DownVotes example above.
Even with an index on UpVotes, DownVotes, nothing in your index keeps track of what row values added together would be.
SQL Server has to do that math every time the query runs and then filter on the result. Sometimes those expressions can be pushed to an index scan, and other times they need a Filter operator later in the plan.
Consider a query that inadvisably does one of these things:
function(column) = something
column + column = something
column + value = something
value + column = something
column = case when …
value = case when column…
convert_implicit(column) = something
As long as all values are known ahead of time — meaning they’re not a parameter, variable, or runtime constant like GETDATE() — you can create computed columns that you can index and make searches really fast.
Take this query and index as an example:
SELECT c = COUNT_BIG(*) FROM dbo.Posts AS p WHERE DATEDIFF(YEAR, p.CreationDate, p.LastActivityDate) > 9;
CREATE INDEX p ON dbo.Posts(CreationDate, LastActivityDate) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
The best we can do is still to read every row via a scan:
still not good
But we can fix that by computing and indexing:
ALTER TABLE dbo.Posts ADD ComputedDiff AS DATEDIFF(YEAR, CreationDate, LastActivityDate);
CREATE INDEX p ON dbo.Posts(ComputedDiff) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE, DROP_EXISTING = ON);
And now our query plan is much faster, without needing to go parallel, or more parallel, to get faster:
improvement!
SQL Server barely needs to flinch to finish that query, and we get an actually good estimate to boot.
Crappy Limitations
While many computed columns can be created, not all can be indexed. For example, something like this would be lovely to have and to have indexed:
ALTER TABLE dbo.Users ADD RecentUsers AS DATEDIFF(DAY, LastAccessDate, SYSDATETIME());
CREATE INDEX u ON dbo.Users (RecentUsers);
While the column creation does succeed, the index creation failed:
Msg 2729, Level 16, State 1, Line 177
Column ‘RecentUsers’ in table ‘dbo.Users’ cannot be used in an index or statistics or as a partition key because it is non-deterministic.
You also can’t reach out to other tables:
ALTER TABLE dbo.Users ADD HasABadge AS CASE WHEN EXISTS (SELECT 1/0 FROM dbo.Badges AS b WHERE b.UserId = Id) THEN 1 ELSE 0 END;
SQL Server doesn’t like that:
Msg 1046, Level 15, State 1, Line 183
Subqueries are not allowed in this context. Only scalar expressions are allowed.
There are other, however these are the most common disappointments I come across.
Some of the things that computed columns fall flat with are things we can remedy with indexed views, but boy howdy are there a lot of gotchas.
We’ll talk about those tomorrow!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
For all the good indexes do, sometimes you just don’t need them to cover all of the data in a table for various reasons.
There are a number of fundamentals that you need to understand about them (that any good consultant will tell you about), but I wanna cover them here just in case you had an unfortunate run-in with a less-than-stellar consultant.
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
QUOTED_IDENTIFIER ON
ANSI_NULLS ON
ANSI_PADDING ON
ANSI_WARNINGS ON
ARITHABORT ON
CONCAT_NULL_YIELDS_NULL ON
NUMERIC_ROUNDABORT OFF
Second, you need to be careful about parameterized queries. If your filtered index and query looks like this:
CREATE INDEX u ON dbo.Users(Reputation) WHERE Reputation > 100000;
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE u.Reputation > @Reputation;
The optimizer will not use your filtered index, because it has to pick a safe and cache-able plan that works for any input to the @Reputation parameter (this goes for local variables, too).
To get around this, you can use:
Recompile hint
Literal value
Potentially unsafe dynamic SQL
Third, you need to have the columns in your filtering expression be somewhere in your index definition (key or include) to help the optimizer choose your index in some situations.
Let’s say you have a filtered index that looks like this:
CREATE INDEX u ON dbo.Users(DisplayName) WHERE Reputation > 100000;
As thing stand, all the optimizer knows is that the index is filtered to Reputation values over 100k. If you need to search within that range, like 100k-200k, or >= 500k, it has to get those values from somewhere, and it has the same options as it does for other types of non-covering indexes:
Ignore the index you thoughtfully created and use another index
Use a key lookup to go back to the clustered index to filter specific values
General Uses
The most common uses that I see are:
Indexing for soft deletes
Indexing unique values and avoiding NULLs
Indexing for hot data
Indexing skewed data to create a targeted histogram
There are others, but one thing to consider when creating filtered indexes is how much of your data will be excluded by the definition.
If more than half of your data is going to end up in there, you may want to think hard about what you’re trying to accomplish.
Another potential use that I sometimes find for them is using the filter to avoid needing an overly-wide index key.
Let’s say you have a super important query that looks like this:
SELECT
u.DisplayName,
TotalScore =
SUM(p.Score)
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.AcceptedAnswerId > 0
AND p.ClosedDate IS NULL
AND p.Score > @Score
AND p.OwnerUserId = @OwnerUserId
ORDER BY TotalScore DESC;
You’re looking at indexing for one join clause predicate and four additional where clause predicates. Do you really want five key columns in your index? No?
How about this?
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, Score)
INCLUDE
(PostTypeId, AcceptedAnswerId, ClosedDate)
WHERE
(PostTypeId = 1 AND AcceptedAnswerId > 0 AND ClosedDate IS NULL)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
This will allow your query to pre-seek to the the literal value predicates, and then evaluate the parameterized predicates in the key of the index.
Crappy Limitations
There are lots of things you might want to filter an index on, like an expression. But you can’t.
I think one of the best possible use cases for a filtered index that is currently not possible is to isolate recent data. For example, I’d love to be able to create a filtered index like this:
CREATE INDEX u ON dbo.Users(DisplayName) WHERE CreationDate > DATEADD(DAY, -30, CONVERT(date, SYSDATETIME()));
So I could just just isolate data in the table that was added in the last 30 days. This would have a ton of applications!
But then the index would have to be self-updating, churning data in and out on its own.
For something like that, you’ll need a computed column. But even indexing those can be tricky, so we’ll talk about those tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.