A while back, the CMU Database group started hosting a series of database talks that gave the folks behind new and interesting databases a chance to talk about what they’re working on, why they built it, how they’re different from what’s around, and more.
I really enjoyed a bunch of them, and I think you might too, so this week I’m posting my favorite ones.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A while back, the CMU Database group started hosting a series of database talks that gave the folks behind new and interesting databases a chance to talk about what they’re working on, why they built it, how they’re different from what’s around, and more.
I really enjoyed a bunch of them, and I think you might too, so this week I’m posting my favorite ones.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I know what you’re thinking: Who cares about that free database?
Well, it’s not necessarily the Postgres part that you might care about, but more the fact that a third party is developing software to do what major vendors aren’t doing.
This sort of thing might come to SQL Server someday, and it probably should. The self-tuning features in Azure are ass.
Thanks for reading.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In my quest to love indexed views more, I’m always trying new things with them to solve problems.
Occasionally, I am pleasantly surprised by what can be accomplished with them. Occasionally.
Today was not an occasion. Let’s take an unfortunate look.
CREATE TABLE
dbo.IndexedViewMe
(
id int PRIMARY KEY CLUSTERED
);
GO
CREATE VIEW
dbo.TheIndexedView
WITH SCHEMABINDING
AS
SELECT
ivm.id
FROM dbo.IndexedViewMe AS ivm;
GO
CREATE UNIQUE CLUSTERED INDEX
uqi
ON dbo.TheIndexedView
(id);
INSERT
dbo.IndexedViewMe
(
id
)
SELECT
x.c
FROM
(
SELECT 1
UNION ALL
SELECT 2
) AS x(c);
This gives us a tiny little table and indexed view. If we try to do either of these things, it doesn’t go well:
CREATE INDEX
i
ON dbo.TheIndexedView
(id)
WHERE
id = 2;
Msg 10610, Level 16, State 1, Line 40
Filtered index ‘i’ cannot be created on object ‘dbo.TheIndexedView’ because it is not a user table. Filtered indexes are only supported on tables.
If you are trying to create a filtered index on a view, consider creating an indexed view with the filter expression incorporated in the view definition.
CREATE STATISTICS
s
ON dbo.TheIndexedView
(id)
WHERE
id = 2;
Msg 10623, Level 16, State 1, Line 47
Filtered statistics ‘s’ cannot be created on object ‘dbo.TheIndexedView’ because it is not a user table. Filtered statistics are only supported on user tables.
Sort of a bummer, that. And it strikes me that it’s an odd limitation — especially for the statistics — but what can you do?
Indexed views haven’t changed aside from bug fixes in forever and a day. I doubt there’ll be any real investment in enhancing them anytime soon.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You know those tables, right? The ones where developers went and got lazy or didn’t know any better and decided every string column was going to be gigantic.
They may have read, of course, that SQL Server’s super-smart variable length data types only consume necessary space.
It’s free real estate.
Except it isn’t, especially not when it comes to query memory grants.
The bigger a string column’s defined byte length is, the bigger the optimizer’s memory grant for it will be.
Memory Grant Primer
In case you need some background, the short story version is:
All queries ask for some memory for general execution needs
Sorts, Hashes, and Optimized Nested Loops ask for additional memory grants
Memory grants are decided based on things like number of rows, width of rows, and concurrently executing operators
Memory grants are divided by DOP, not multiplied by DOP
By default, any query can ask for up to 25% of max server memory for a memory grant
Approximately 75% of max server memory is available for memory grants at one
Needless to say, memory grants are very sensitive to misestimates by the optimizer. Going over can be especially painful, because that memory will most often get pulled from the buffer pool, and queries will end up going to disk more.
Underestimates often mean spills to disk, of course. Those are usually less painful, but can of course be a problem when they’re large enough. In particular, hash spills are worth paying extra attention to.
Memory grant feedback does supply some relief under modern query execution models. That’s a nice way of saying probably not what you have going on.
Query Noogies
Getting back to the point: It’s a real pain in the captain’s quarters to modify columns on big tables, even if it’s reducing the size.
SQL Server’s storage engine has to check page values to make sure you’re not gonna lose any data fidelity in the process. That’ a nice way of saying you’re not gonna truncate any strings.
But if you do something cute like run a MAX(LEN(StringCol) and see what you’re up against, you can use a view on top of your table to assuage SQL Server’s concerns about such things.
After all, functions are temporary. Data types are forever (usually).
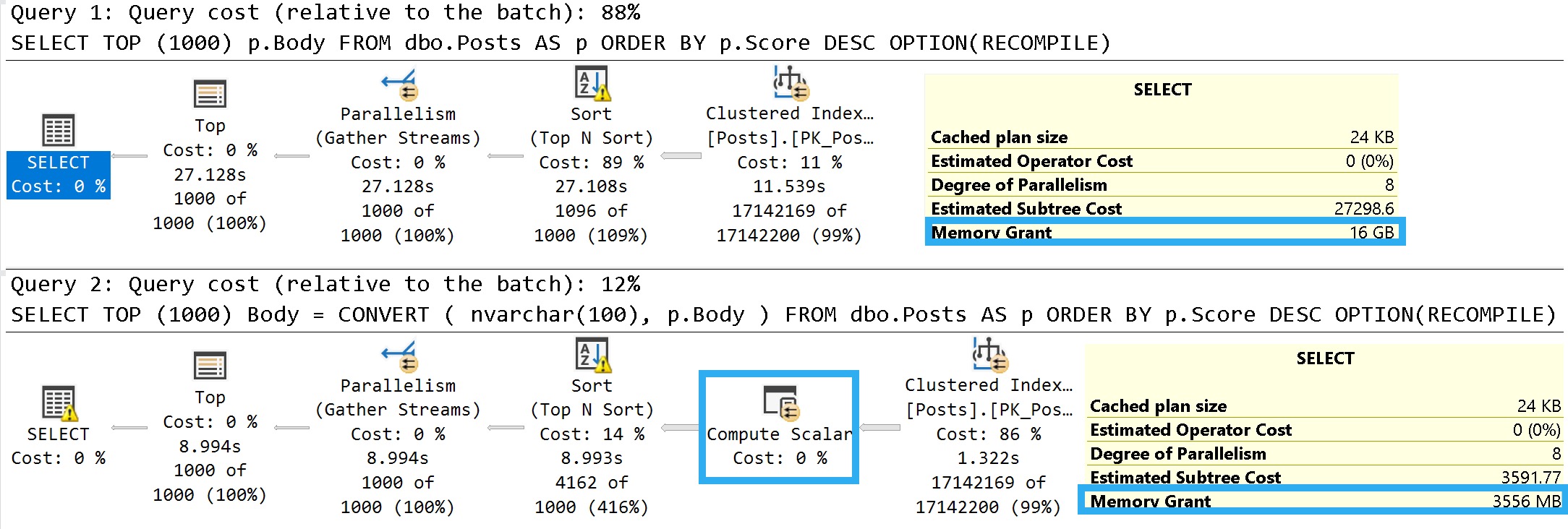
An easy way to illustrate what I mean is to look at the details of these two queries:
SELECT TOP (1000)
p.Body
FROM dbo.Posts AS p
ORDER BY p.Score DESC
OPTION(RECOMPILE);
SELECT TOP (1000)
Body =
CONVERT
(
nvarchar(100),
p.Body
)
FROM dbo.Posts AS p
ORDER BY p.Score DESC
OPTION(RECOMPILE);
Some of this working is dependent on the query plan, so let’s look at those.
Pink Belly Plans
You can ignore the execution times here. The Body column is not a good representation of an oversized column.
It’s defined as nvarchar(max), but (if I’m remembering my Stack lore correctly) is internally limited to 30k characters. Many questions and answers are longer than 100 characters anyway, but on to the plans!
janitor
In the plan where the Body column isn’t converted to a smaller string length, the optimizer asks for a 16GB memory grant, and in the second plan the grant is reduced to ~3.5GB.
This is dependent on the compute scalar occurring prior to the Top N Sort operator, of course. This is where the convert function is applied to the Body column, and why the grant is reduced
If you were to build a view on top of the Posts table with this conversion, you could point queries to the view instead. That would get you the memory grant reduction without the pain of altering the column, or moving the data into a new table with the correct definition.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A client question that I get quite a bit is around why queries in production get a bad query plan that queries in dev, QA, or staging don’t get is typically answered by looking at statistics.
Primarily, it’s because of the cardinality estimates that queries get around ascending keys. It usually gets called the ascending key problem, but the gist is that:
You have a pretty big table
You’re using the legacy cardinality estimator
A whole bunch of rows get inserted, but not enough to trigger an auto stats update
You’re not using compatibility level >= 130 or trace flag 2371
Queries that look for values off an available histogram get a one row estimate using the legacy Cardinality Estimator or a 30% estimate using the default Cardinality Estimator
Which is a recipe for potentially bad query plans.
Reproductive Script
Here’s the full repro script. If you’re using a different Stack Overflow database, you’ll need to adjust the numbers.
USE StackOverflow2013;
/*Figure out the 20% mark for stats updates using legacy compat levels*/
SELECT
c = COUNT_BIG(*),
c20 = CEILING(COUNT_BIG(*) * .20)
FROM dbo.Users AS u;
/*Stick that number of rows into a new table*/
SELECT TOP (493143)
u.*
INTO dbo.Users_Holder
FROM dbo.Users AS u
ORDER BY u.Id DESC;
/*Delete that number of rows from Users*/
WITH
del AS
(
SELECT TOP (493143)
u.*
FROM dbo.Users AS u
ORDER BY u.Id DESC
)
DELETE
FROM del;
/*I'm using this as a shortcut to turn off auto stats updates*/
UPDATE STATISTICS dbo.Users WITH NORECOMPUTE;
/*Put the rows back into the Users Table*/
SET IDENTITY_INSERT dbo.Users ON;
INSERT
dbo.Users
(
Id,
AboutMe,
Age,
CreationDate,
DisplayName,
DownVotes,
EmailHash,
LastAccessDate,
Location,
Reputation,
UpVotes,
Views,
WebsiteUrl,
AccountId
)
SELECT
uh.Id,
uh.AboutMe,
uh.Age,
uh.CreationDate,
uh.DisplayName,
uh.DownVotes,
uh.EmailHash,
uh.LastAccessDate,
uh.Location,
uh.Reputation,
uh.UpVotes,
uh.Views,
uh.WebsiteUrl,
uh.AccountId
FROM dbo.Users_Holder AS uh;
SET IDENTITY_INSERT dbo.Users OFF;
/*Figure out the minimum Id we put into the holder table*/
SELECT
m = MIN(uh.Id)
FROM dbo.Users_Holder AS uh;
/*Compare estimates*/
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id > 2623772
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id > 2623772
OPTION(USE HINT('FORCE_DEFAULT_CARDINALITY_ESTIMATION'));
/*Cleanup*/
UPDATE STATISTICS dbo.Users;
TRUNCATE TABLE dbo.Users_Holder;
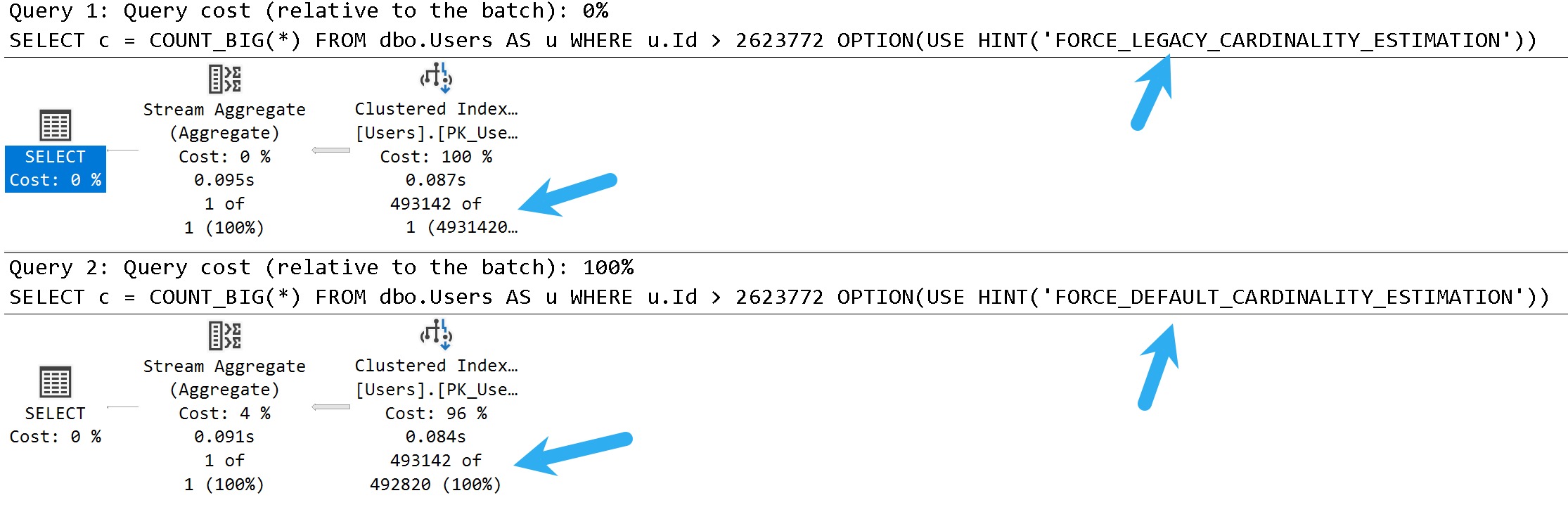
Query Plans
Here are the plans for the stars of our show:
king push
In these query plans, you can see the legacy cardinality estimator gets a one row estimate, and the default cardinality estimator gets a 30% estimate.
There isn’t necessarily a one-is-better-than-the-other answer here, either. There are times when both can cause poor plan choices.
You can think of this scenario as being fairly similar to parameter sniffing, where one plan choice does not fit all executions well.
Checkout
There are a lot of ways that you can go about addressing this.
In some cases, you might be better off using trace flag 2371 to trigger more frequent auto stats updates on larger tables where the ~20% modification counter doesn’t get hit quickly enough. In others, you may want to force one estimator over the other depending on which gets you a better plan for most cases.
Another option is to add hints to the query in question to use the default cardinality estimator (FORCE_DEFAULT_CARDINALITY_ESTIMATION), or to generate quick stats for the index/statistics being used (ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS). Documentation for both of those hints is available here. Along these lines, trace flags 2389, 2390, or 4139 may be useful as well.
Of course, you could also try to address any underlying query or index issues that may additionally contribute to poor plan choices, or just plan differences. A common problem in them is a seek + lookup plan for the one row estimate that doesn’t actually make sense when the actual number of rows and lookup executions are encountered at runtime.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are metrics that I care and don’t care about when I’m looking for queries to tune.
Metrics I don’t care about:
Logical Reads
Costs
If a query does “a lot” of reads or has a high “cost”, I generally don’t care as long as they run quickly. Doing consistent physical reads is a slightly different story, but would probably fall more under server tuning or fixing memory grants.
Metrics I do care about:
CPU (taking parallelism into consideration)
Duration (compared to CPU)
Memory Grants (particularly when they’re not being fully utilized)
Writes (especially if it’s just a select)
Executions (mostly to track down scalar UDFs)
CPU and Duration
These two metrics get lumped together because they need to be compared in order to figure out what’s going on. First, you need to figure out what the minimum runtime of a query is that you want to tune.
In general, as query execution time gets faster, getting it to be much faster gets more difficult.
Bringing a query from 1 second to 100 milliseconds might be a small matter
Bringing that same query from 100 milliseconds to 1 millisecond might take more time than it’s worth
I say that because unless someone is querying SQL Server directly, smaller durations tend to be less detectable to end users. By the time they hit a button, send the request, receive the data, and have the application render it etc. they’re probably not aware of a 99 millisecond difference.
Of course, not everything is end-user centric. Other internal operations, especially any loop processing, might benefit greatly from reductions on the smaller side of things.
If duration and CPU are acceptable, leave it alone
If either is unacceptable, tune the darn thing
If CPU is much higher than duration, you have a parallel plan, and tuning is optional
If duration is much higher than CPU, you have blocking or another contention issue, and the query you’re looking at probably isn’t the problem
If duration and CPU are roughly equivalent, you either have a functional serial plan or a really crappy parallel plan
I give these the highest priority because reducing these is what makes queries faster, and reduces the surface area (execution time) of a query where something crappy might happen, like blocking, or deadlocks, or other resource contention.
Memory Grants
Using these as a tuning metric can have a lot of positive effects, depending on what kind of shape the system is in.
Consider a few scenarios:
PAGEIOLATCH_XX waits are high because large memory grants steal significant buffer pool space
RESOURCE_SEMAPHORE waits are high because queries suck up available memory space and prevent other queries from using it
Queries are getting too low of a memory grant and spilling significantly, which can slow them down and cause tempdb contention under high concurrency
Fixing memory grant issues can take many forms:
Getting better cardinality estimates for better overall grant estimates
Indexing to influence operator choices away from memory consumers
Using more appropriate string lengths to reduce memory grants
Fixing parallel skew issues that leaves some threads with inadequate memory
Rewriting the query to not ask for ordered data
Rewriting the query to ask for ordered data in smaller chunks
Rewriting the query to convert strings to better fitting byte lengths
That’s just some stuff I end up doing off the top of my head. There are probably more, but blog posts are only useful up to a certain length.
Like all other strings.
Writes and Selects
Modification queries are going to do writes. This seems intuitive and not at all shocking. If you have queries that are doing particularly large modifications, you could certainly look into tuning those, but it would be a standard exercise in query or index tuning.
Except that your index tuning adventure would most likely lead you to dropping unused and overlapping indexes to reduce the number of objects that you need to write to than to add an index.
But who knows. Boring anyway. I hear indexes tune themselves in the cloud.
When select queries do a large number of writes, then we’re talking about a much more interesting scenario.
Spills
Spools
Stats updates
Of course, stats updates are likely a pretty small write, but the read portion can certainly halt plan compilation for a good but on big tables.
Spills and Spools are going to be the real target here. If it’s a spill, you may find yourself tracking back to the memory grant section up above.
Spools, though! What interesting little creatures. I wrote a longer post about them here:
It has a bit of a link roundup of other posts on my site and others that talk about them, too.
But since we’re living in this now, let’s try to be present. Here’s the short story on spools that we might try to fix:
The Spools we typically care about are Table or Index
They can be eager or lazy
They’ll show up on the inner side of Nested Loops
SQL Server uses them as a temporary cache for data
They are a good indicator that something is amok with your query or indexes
For eager index spools, the story is pretty simple around creating a better index for SQL Server to use.
For lazy table spools, you have more options:
Give SQL Server unique data to work with
Get the optimizer to not choose nested loops
Use the NO_PERFORMANCE_SPOOL hint to test the query without spools
Of course, there are times where you’re better off with a spool than without. So don’t walk away feeling disheartened if that’s the case.
Executions
These are on the opposite end of the spectrum from most of the queries I go after. If a query runs enough, and fast enough, to truly rack up a high number of executions, there’s probably not a ton of tuning you could do.
Sure, sometimes there’s an index you could add or a better predicate you could write, but I’d consider it more beneficial to get the query to not run so much.
That might result in:
Rewriting functions as inline table valued functions
Handing the queries off to app developers for caching
To learn how I rewrite functions, check out this video
I know, you can’t rewrite every single function like this, but it’s a wonderful thing to do when you can.
Anything Other Than
Again, metrics I don’t ever look at are logical reads or costs.
Doing reads doesn’t necessarily mean that queries are slow, or that there’s anything you can fix
Costs are a meme metric that should be removed from query plans in favor of operator times
Well, okay, maybe not completely removed, but they shouldn’t be front and center anymore.
There are many other more reliable metrics to consider that are also far more interesting.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I used to get so excited about looking in the plan cache, and writing all sorts wacky XML queries to parse plans and dig for goodies.
Then I started to ask some tough questions about it, like:
How many plans are in here?
What’s the oldest one?
How many duplicate plans are there?
Where’s the parameter sniffing details?
Why is optimize for adhoc workloads the worst setting that everyone said is a best practice for eons?
As I wrote queries to look at a lot of these things, stuff got… weird. And disappointing.
What’s In There?
The plan cache has limits for how many plans it’ll keep, and how big of a cache it’ll keep. Even if there’s a lot of plans, there’s no guarantee that they’re older than a few hours.
You may even find that simple parameterization makes things confusing, and that things get cleared out at inopportune times.
One situation I’ve run into well-more than once is the plan cache getting cleared out due to query memory pressure, and then any chance of figuring out which queries were responsible disappears along with it.
Memory is important, someone once said.
On top of that, a lot of SQL Server consumers have way too much faith in bunk metrics, like query and operator costs. Sure, there are plenty of corroborating views to get resource usage metrics, but if all you’ve got is a query plan, all you’ve got is a bunch of nonsense costs to tweedle yourself with.
Sniff Sniff Pass
Another big miss with the plan cache is that it is almost no help whatsoever with parameter sniffing.
Sure, you can sort of figure out based on wide variances in various metrics if a plan sometimes does way more work or runs way longer than other times, but… You still just see the one plan, and its compile values. You don’t see what the plan was, or could be.
Or should be, but that’s a story for another day.
This is where Query Store is awesome, of course! You can see regressions and all that jazz.
But in the plan cache, boy howdy, you get a whole lotta nothing. No Rosie at all.
And this is why I hate the plan cache.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The more I used third party monitoring tools, the more annoyed I get. So much is missing from the details, configurability, and user experience.
I often find myself insisting on also having Query Store enabled. As much as I’d love other improvements, I think it’s also important to have a centralized experience for SQL Server users to track down tricky issues.
There are so many views and metrics out there, it would be nice to have a one stop shop to see important things.
Among those important things are blocking and deadlocks.
Deadlockness
Deadlocks are perhaps the more obvious choice, since they’re already logged to the system health extended event session.
Rather than leave folks with a bazillion scripts and stored procedures to track them down, Query Store should add a view to pull data from there.
If Microsoft is embarrassed by how slow it is to grab all that session data, and they should be, perhaps that’s a reasonable first step to having Query Store live up to its potential.
Most folks out there have no idea where to look for that stuff, and a lot of scripts that purport to get you detail are either wildly outdated, or are a small detail away from turning no results and leaving them frustrated as hell.
I know because I talk to them.
Blockhead
Blocking, by default, is not logged anywhere at all in SQL Server.
If you wanna get that, you have to be ready for it, and turn on the Blocked Process Report:
sp_configure
'show advanced options',
1;
GO
RECONFIGURE;
GO
sp_configure
'blocked process threshold',
10;
GO
RECONFIGURE;
GO
Of course, from there you have to… do more to get the data.
Awful lot of prep work to catch blocking in a database with a pessimistic isolation level on by default, eh?
Left Out
If you want to take this to the next level, it could also grab CPU from the ring buffer, file stats, and a whole lot more. Basically everything other than PLE.
Never look at PLE.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I think it was sometime in the last century that I mentioned I often recommend folks turn on Forced Parameterization in order to deal with poorly formed application queries that send literal rather than parameterized values to SQL Server.
And then just like a magickal that, I recommended it to someone who also has a lot of problems with Local Variables in their stored procedures.
They were curious about if Forced Parameterization would fix that, and the answer is no.
But here’s proofs. We love the proofs.
Especially when they’re over 40.
A Poorly Written Stored Procedure
Here’s this thing. Don’t do this thing. Even the index is pretty dumb, because it’s on a single column.
CREATE INDEX
i
ON dbo.Users
(Reputation)
WITH
(SORT_IN_TEMPDB= ON, DATA_COMPRESSION = PAGE);
GO
CREATE PROCEDURE
dbo.humpback
(
@Reputation int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
/*i mean don't really do this c'mon*/
DECLARE
@ReputationCopy int = ISNULL(@Reputation, 0);
SELECT
u.DisplayName,
u.Reputation,
u.CreationDate,
u.LastAccessDate
FROM dbo.Users AS u
WHERE u.Reputation = @ReputationCopy;
END;
ALTER DATABASE StackOverflow2013 SET PARAMETERIZATION FORCED;
GO
EXEC dbo.humpback
@Reputation = 11;
GO
ALTER DATABASE StackOverflow2013 SET PARAMETERIZATION SIMPLE;
GO
EXEC dbo.humpback
@Reputation = 11;
GO
For now, you’ll have to do a little more work to fix local variable problems.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.