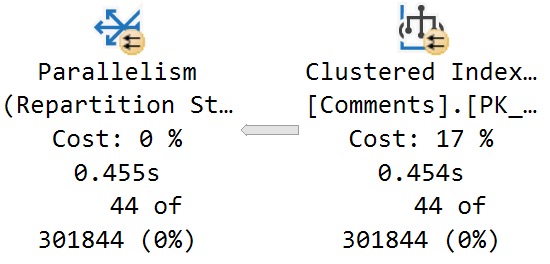
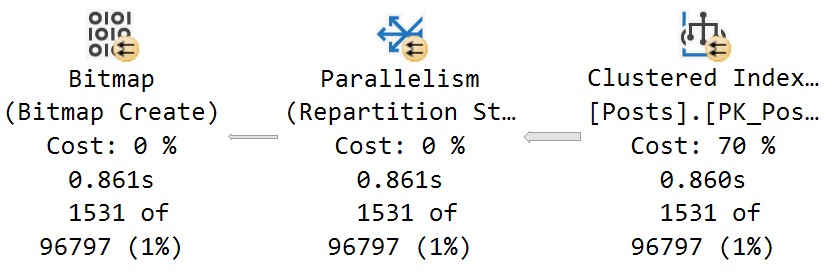
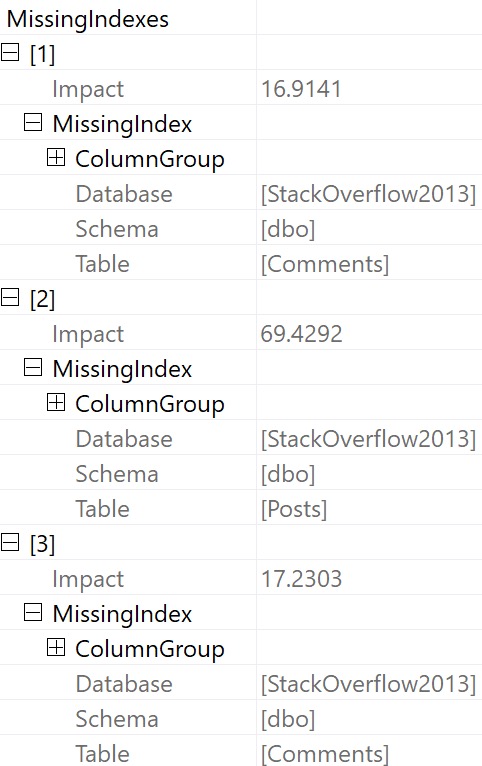
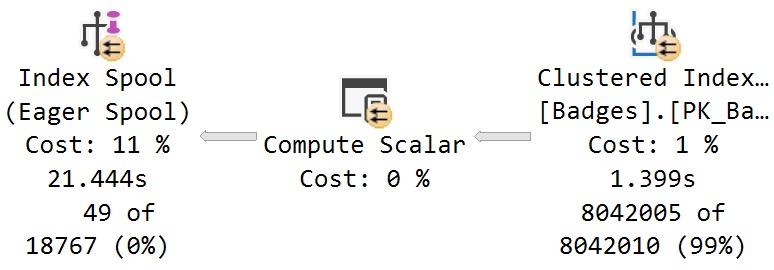
| package_name |
event_name |
description |
|
|
| qds |
automatic_tuning_query_check_ignored |
Fired when APRC decides to not track a query that is marked as ignored |
|
|
| qds |
automatic_tuning_wtest_details |
Fired when APRC performs Welch test based regression detection |
|
|
| qds |
ce_feedback_hints_lookup_failed |
Fired when error occurs during CE Feedback hints lookup. |
|
|
| qds |
query_store_clear_db_oversize_flag |
Fired when QDS is clearing DB oversize flag. |
|
|
| qds |
query_store_clear_message_queues |
Fired when query store clears the message queue |
|
|
| qds |
query_store_generate_showplan_with_replay_script_failure |
Fired when Query Store failed to update a query plan because the generation of showplan (which contains a Replay Script) failed. |
|
|
| qds |
query_store_hints_application_failed |
Fired if application of Query Store hints failed. |
|
|
| qds |
query_store_hints_application_persist_failure_failed |
Fired if last_failure_reason and failure_count in sys.query_store_query_hints failed to update. |
|
|
| qds |
query_store_hints_application_success |
Fired if application of Query Store hints succeeded. |
|
|
| qds |
query_store_hints_lookup_failed |
Fired if there is a failure during the lookup for whether a query has any hints set in Query Store. Query hints, if any, will not be applied. |
|
|
| qds |
query_store_messaging_failures |
Diagnostic information for QDS messaging components. |
|
|
| qds |
query_store_persist_feedback_quick_lock_failures |
This XEvent is fired when we fail to acquire quick shared db lock during feedback persistence. |
|
|
| qds |
query_store_secondary_guid_creation_failure |
|
|
|
| qds |
query_store_update_plan_with_replay_script |
Fired when the existing Showplan in QDS is updated with a Showplan with Replay Script |
|
|
| qds |
query_store_user_plan_removal |
Fired when plan is removed with SP sp_query_store_remove_plan. |
|
|
| qds |
query_store_user_query_removal |
Fired when query is removed with SP sp_query_store_remove_query. |
|
|
| sqlclr |
clr_forced_yield |
SQL CLR quantum punishment ocurred. |
|
|
| sqlos |
cpu_starvation_stats_ring_buffer_recorded |
CPU starvation stats ring buffer recorded |
|
|
| sqlos |
sos_direct_shrink_no_progress |
Fire if Direct Shrink does not make progress within specified timer period |
|
|
| sqlos |
sos_operate_set_target_task_list |
Lock acquire failure when doing insert/delete |
|
|
| SQLSatellite |
job_object_trace |
Fired for launchpad job object trace events. |
|
|
| SQLSatellite |
management_session_creation |
Fired when a new library or language management session is created. |
|
|
| sqlserver |
aad_build_federated_context |
Occurs when we attempt to build federated context. |
|
|
| sqlserver |
aad_signing_key_refresh |
Occurs when we attempt to refresh signing keys from Azure Active Directory, to update the in-memory cache. |
|
|
| sqlserver |
add_file_in_master |
Occurs when the file manager added file metadata in the master database segment. |
|
|
| sqlserver |
add_file_rollback |
Occurs when add file action is rolled back. |
|
|
| sqlserver |
adr_sweep_for_skip_pages_finished |
The ADR sweep for skipped pages in ADR finished. |
|
|
| sqlserver |
adr_sweep_timed_out |
The ADR sweep for skipped pages timed out. |
|
|
| sqlserver |
all_files_created |
Occurs when all database files has already been formatted on disk for an ADD FILE DDL statement. |
|
|
| sqlserver |
allocation_page_update_stats |
Allocation page (PFS/GAM/SGAM) statistics. |
|
|
| sqlserver |
ascending_leading_column_flipped |
The sort type of the leading column flipped from/to ascending? |
|
|
| sqlserver |
async_read_page_count_bucket |
Emit page counts map for rbio async read requests. |
|
|
| sqlserver |
attention |
Indicates that a cancel operation, client-interrupt request, or broken client connection has occurred. Be aware that cancel operations can also occur as the result of implementing data access driver time-outs, aborted. |
|
|
| sqlserver |
auth_fw_cache_lookup_failure |
This event is generated when the xodbc cache firewall lookup fails. |
|
|
| sqlserver |
auth_fw_cache_lookup_success |
This event is generated when the xodbc cache firewall lookup succeeds. |
|
|
| sqlserver |
autostats_update_async_low_priority_status |
This XEvent is fired when auto asynchronous statistics is triggered in low priority mode. |
|
|
| sqlserver |
autostats_update_blocking_readers |
This XEvent is fired to reproduce a blocking scenario when an auto statistics update thread waits to acquire a Sch-M lock on stats metadata object which subsequently blocks readers (select queries on that table for instance). This XEvent is used primarily for unit testing. |
|
|
| sqlserver |
azure_active_directory_service_failure |
Occurs when we encounter a failure in AzureActiveDirectoryService layer, when performing MSODS lookup during Login and Create Login/User workflow. |
|
|
| sqlserver |
backup_between_data_and_log |
Used for signaling the point in a full/diff backup after the data copy is finished but before the log copy has started. |
|
|
| sqlserver |
blob_access_pattern |
Blobs access pattern |
|
|
| sqlserver |
blob_trace_backtrack |
Search blob trace for the problem blob handle lifetime |
|
|
| sqlserver |
btree_retraversal_count |
In every 2 hours interval,stats data of BTree re-traversal count is emitted |
|
|
| sqlserver |
buffer_pool_flush_cache_start |
Fired when Buffer Pool starts flushing dirty buffers. |
|
|
| sqlserver |
buffer_pool_flush_io_throttle |
Fire when Buffer Pool throttles flushing dirty pages. This event is fired very frequently when IO throttling is occurring. |
|
|
| sqlserver |
buffer_pool_flush_io_throttle_status |
Fired when Buffer Pool is flushing dirty pages. This event reports the status of IO throttling. |
|
|
| sqlserver |
buffer_pool_scan_start |
Fired when Buffer Pool scan starts. |
|
|
| sqlserver |
buffer_pool_scan_stats |
Buffer Pool Scan Statistics. |
|
|
| sqlserver |
buffer_pool_scan_task_complete |
Fired when Buffer Pool scan parallel task completes. |
|
|
| sqlserver |
buffer_pool_scan_task_error |
Fired when Buffer Pool scan parallel task encounters an error. |
|
|
| sqlserver |
buffer_pool_scan_task_start |
Fired when Buffer Pool scan parallel task starts. |
|
|
| sqlserver |
cdc_cleanup_job_status |
Change data capture cleanup job status. Returns information every 5 minutes. |
|
|
| sqlserver |
cdc_ddl_session |
CDC DDL Handling Session Information |
|
|
| sqlserver |
cdc_log_throttle |
Occurs when primary log gets full because of CDC/Repl and needs to be throttled. |
|
|
| sqlserver |
cdc_log_throttle_manager |
CDC Log I/O throttling manager events (create, delete, error) |
|
|
| sqlserver |
cdc_scheduler |
CDC Scheduler Information |
|
|
| sqlserver |
certificate_report |
Certificate info. |
|
|
| sqlserver |
column_store_fast_string_equals |
Info about fast string search |
|
|
| sqlserver |
column_store_index_deltastore_add_column |
A columnstore deltastore rowgroup was rewritten from adding a column. |
|
|
| sqlserver |
column_store_index_deltastore_alter_column |
A columnstore deltastore rowgroup was rewritten from altering a column. |
|
|
| sqlserver |
column_store_qualified_rowgroup_stats |
Info about row group elimination and qualification in columnstore scan. |
|
|
| sqlserver |
columnstore_flush_as_deltastore_fido |
Shows column store index build information when remaining rows in the current rowgroup have been flushed into deltastore. |
|
|
| sqlserver |
columnstore_index_additional_memory_fraction |
Shows column store index addtional memory fraction information during columnstore index build. |
|
|
| sqlserver |
columnstore_index_adjust_required_memory |
Shows column store memory information when the required memory is adjusted to zero. |
|
|
| sqlserver |
columnstore_index_bucketization_cleanup_task_fail |
Shows column store index build information when a bucketization failed to clean up a task related objects. |
|
|
| sqlserver |
columnstore_index_bucketization_create_dataset |
Shows column store index build information when a bucketization insertion created a dataset. |
|
|
| sqlserver |
columnstore_index_bucketization_create_task |
Shows column store index build information when a bucketization process is about to finish. |
|
|
| sqlserver |
columnstore_index_bucketization_create_task_from_multiple_cells |
Shows column store index build information when a bucketization process has created one or more tasks from multiple cells. |
|
|
| sqlserver |
columnstore_index_bucketization_drop_worktable |
Shows column store index build information when a bucketization dropped a worktable. |
|
|
| sqlserver |
columnstore_index_bucketization_end_index_build |
Shows column store index build information when a bucketization process is about to create a task. |
|
|
| sqlserver |
columnstore_index_bucketization_enqueue_all_tables |
Shows column store index build information when a bucketization process has enqueued all remaining worktables. |
|
|
| sqlserver |
columnstore_index_bucketization_first_row_received |
Shows column store index build information when a bucketization insertion thread received the first row. |
|
|
| sqlserver |
columnstore_index_bucketization_get_or_create_worktable |
Shows column store index build information when a bucketization insertion created a worktable. |
|
|
| sqlserver |
columnstore_index_bucketization_init_index_build |
Shows column store index build information when a bucketization process is initialized. |
|
|
| sqlserver |
columnstore_index_bucketization_insert_fail |
Shows column store index build information when a bucketization process has failed. |
|
|
| sqlserver |
columnstore_index_bucketization_insert_into_columnstore_fail |
Shows column store index build information when a bucketization insertion into a columnstore segment has failed. |
|
|
| sqlserver |
columnstore_index_bucketization_insert_into_worktable_fail |
Shows column store index build information when a bucketization insertion into a worktable has failed. |
|
|
| sqlserver |
columnstore_index_bucketization_process_task |
Shows column store index build information when a bucketization process task is finished. |
|
|
| sqlserver |
columnstore_index_bucketization_process_task_about_to_flush_last_row |
Shows column store index build information when a bucketization task flushed the last row into columnstore index builder. |
|
|
| sqlserver |
columnstore_index_bucketization_process_task_fail |
Shows column store index build information when a bucketization process task has failed. |
|
|
| sqlserver |
columnstore_index_bucketization_process_task_start |
Shows column store index build information when a bucketization process task is started. |
|
|
| sqlserver |
columnstore_index_bucketization_reached_end_index_build |
Shows column store index build information when a bucketization process is reached to the end of index build, but has not finished its work yet. |
|
|
| sqlserver |
columnstore_index_bucketization_rows_received |
Shows column store index build information when a bucketization insertion thread received rows. |
|
|
| sqlserver |
columnstore_index_bulk_insert_acquire_memory_grant_attempt_timeout |
Shows column store memory information when an attempt of the memory grant request of columnstore bulk insert times out. |
|
|
| sqlserver |
columnstore_index_clear_bulk_insert_flag |
Shows rowset information when the columnstore bulk insert flag is cleared. |
|
|
| sqlserver |
columnstore_index_convert_bulk_insert_to_trickle_insert |
Shows column store memory information when the memory grant request of columnstore bulk insert times out. |
|
|
| sqlserver |
columnstore_object_manager_read_retry |
Retry read from azure blobk blob on sbs read failure. |
|
|
| sqlserver |
columnstore_tuple_mover_exclusion_lock_timeout |
The tuple mover timed out trying to acquire a lock to compress a row group. |
|
|
| sqlserver |
columnstore_tuple_mover_worker_stealing |
Columnstore tuple mover worker stealing. |
|
|
| sqlserver |
compute_readable_secondary_wait_for_redo_for_debugging |
When a query gets a page from the future, it waits for redo to catchup. Emitted without predicates |
|
|
| sqlserver |
compute_secondary_permanent_fault |
|
|
|
| sqlserver |
concurrent_gam_update_stats |
Concurrent GAM Update stats. |
|
|
| sqlserver |
connection_attempt_failure_system_error |
Connection attempt metrics |
|
|
| sqlserver |
connection_attempt_failure_user_error |
Connection attempt user error metrics |
|
|
| sqlserver |
connection_attempt_success |
Connection attempt success metrics |
|
|
| sqlserver |
cpu_vectorization_levels |
Event containing details of CPU vectorization level(s). |
|
|
| sqlserver |
create_acr_cache_store |
When an Access Check Result cache store is created. |
|
|
| sqlserver |
create_file_tracing |
Tracing during the different steps of FileCreation. |
|
|
| sqlserver |
csv_column_statistics |
Aggregate details of processing a column for one file. |
|
|
| sqlserver |
csv_decompression_statistics |
Decompression time and memory utilized if the input file is compressed. |
|
|
| sqlserver |
csv_input_file |
Details of a CSV input file processed by OpenRowset |
|
|
| sqlserver |
csv_rejected_rows |
Aggregate details for a error type of rejected rows. |
|
|
| sqlserver |
csv_row_statistics |
Aggregate details of processing rows for one file. |
|
|
| sqlserver |
csv_shallow_parse |
Aggregate details for shallow parsing logic used in calculating file splits. |
|
|
| sqlserver |
customer_connection_failure |
Connection failure metrics |
|
|
| sqlserver |
customer_connection_failure_firewall_error |
Connection blocked by firewall |
|
|
| sqlserver |
customer_connection_failure_user_error |
Connections failed due to user error |
|
|
| sqlserver |
customer_connection_success |
Connection successful metrics |
|
|
| sqlserver |
dac_login_information |
Occurs when an internal DAC session is established/disconnected with sqlserver |
|
|
| sqlserver |
data_export_profile |
Reports aggregated stats about data exported to an external file. Distinct event per each file and each processing thread. |
|
|
| sqlserver |
data_retention_cleanup_completed |
Occurs when cleanup process of table with data retention policy ends. |
|
|
| sqlserver |
data_retention_cleanup_exception |
Occurs cleanup process of table with retention policy fails. |
|
|
| sqlserver |
data_retention_cleanup_started |
Occurs when cleanup process of table with data retention policy starts. |
|
|
| sqlserver |
data_retention_cleanup_task_exception |
Occurs when then background (parent) task for data retention based cleanup fails due to an exception. |
|
|
| sqlserver |
data_retention_task_completed |
Occurs when background task for cleanup of tables with retention policy ends. |
|
|
| sqlserver |
data_retention_task_exception |
Occurs when background task for cleanup of tables with retention policy fails outside of retention cleanup process specific to table. |
|
|
| sqlserver |
data_retention_task_started |
Occurs when background task for cleanup of tables with retention policy starts. |
|
|
| sqlserver |
data_virtualization_failed_query |
Fired when OPENROWSET or query against external table or external file format fails during parsing. |
|
|
| sqlserver |
data_virtualization_query |
Fired on compile for every query targeting external data sources. |
|
|
| sqlserver |
database_file_growing |
Occurs when any of the data or log files for a database is about to grow. |
|
|
| sqlserver |
database_recovery_complete |
Occurs when database recovery has completed. |
|
|
| sqlserver |
database_xml_deadlock_report_mdm |
Emit a metric when a deadlock report for a victim is produced. |
|
|
| sqlserver |
db_fw_cache_expire_begin |
This event is generated when the task that cleans the DB firewall cache begins. |
|
|
| sqlserver |
db_fw_cache_expire_end |
This event is generated when the task that cleans the DB firewall cache ends. |
|
|
| sqlserver |
db_fw_cache_lookup_failure |
This event is generated when the DB firewall lookup fails. |
|
|
| sqlserver |
db_fw_cache_lookup_success |
This event is generated when the DB firewall lookup success. |
|
|
| sqlserver |
db_fw_cache_update_begin |
This event is generated when the task that updates the DB firewall cache begins. |
|
|
| sqlserver |
db_fw_cache_update_end |
This event is generated when the task that updates the DB firewall cache ends. |
|
|
| sqlserver |
deadlock_callstack |
Print callstack of thread within deadlock graph. |
|
|
| sqlserver |
deferred_au_deallocation_to_next_run |
Dropping of allocation unti marked for deferred drop is delayed to the next run. |
|
|
| sqlserver |
delta_migration_failure |
Delta Migration Failure XEvents |
|
|
| sqlserver |
delta_migration_information |
Delta Migration Informational XEvents |
|
|
| sqlserver |
delta_migration_task_end |
Delta Migration Task End XEvents |
|
|
| sqlserver |
delta_migration_task_start |
Delta Migration Task Start XEvents |
|
|
| sqlserver |
dop_feedback_eligible_query |
Reports when a query plan becomes eligible for dop feedback |
|
|
| sqlserver |
dop_feedback_provided |
Reports DOP feedback provided data for a query |
|
|
| sqlserver |
dop_feedback_reverted |
This reports when a DOP feedback is reverted |
|
|
| sqlserver |
dop_feedback_validation |
Reports when the validation occurs for the query runtime stats against baseline or previous feedback stats |
|
|
| sqlserver |
drop_file_committed |
Occurs when drop file action is committed. |
|
|
| sqlserver |
drop_file_prepared |
Occurs when the file is prepared to be dropped. |
|
|
| sqlserver |
drop_file_rollback |
Occurs when drop file action is rolled back. |
|
|
| sqlserver |
dw_backup_app_lock_end |
DW Backup App Lock End XEvents |
|
|
| sqlserver |
dw_backup_app_lock_start |
DW Backup App Lock Begin XEvents |
|
|
| sqlserver |
dw_large_text_store |
DW large text store for fragmented text blobs. |
|
|
| sqlserver |
ests_request_attempt |
Occurs when an ESTS or ESTS-R request is submitted in order to acquire a token for AKV or Storage operations. |
|
|
| sqlserver |
exec_plpgsql |
Shows PLPGSQL statements sent to PostgreSQL server during Exec External Language statement |
|
|
| sqlserver |
ext_table_extr_operation |
External Table Extractor event. Should encapsulate resolving file and schema (and possible initialization). |
|
|
| sqlserver |
external_policy_pulltask_finished |
XEvent for policy pull finish |
|
|
| sqlserver |
external_policy_pulltask_retries |
XEvent for policy pull retries diagnostics |
|
|
| sqlserver |
external_policy_pulltask_started |
XEvent for policy pull start |
|
|
| sqlserver |
external_rest_endpoint_error_winhttp_calls |
Fired when a winhttp API call fails without stopping the execution |
|
|
| sqlserver |
external_rest_endpoint_summary |
Fired for each execution of sp_invoke_external_rest_endpoint. |
|
|
| sqlserver |
external_runtime_execution_stats |
Publishes consolidated stats collected during external endpoint invocation |
|
|
| sqlserver |
external_table_stats_creation |
Fires after computing external table stats. |
|
|
| sqlserver |
extractor_scan_memory_grant |
Summary of an Exteranl Extractor operation memory grant. |
|
|
| sqlserver |
extractor_scan_summary |
Summary of an Exteranl Extractor operation. |
|
|
| sqlserver |
failed_compilation |
Collect the compilation information for errored out or failed compilations. |
|
|
| sqlserver |
failure_injection_during_backup_device_restoring |
Used for testing restore hang if an exception is thrown on one backup stream but other streams are marked as completed |
|
|
| sqlserver |
fedauth_ddl |
Occurs when someone executes CREATE USER/LOGIN FROM Windows; ALTER USER/LOGIN WindowsPrincipal WITH NAME; in SAWAv2 and its not a Backslash login/user. |
|
|
| sqlserver |
fedauth_execute_as |
Execute as DDL events for AD Auth user. |
|
|
| sqlserver |
fedauth_ticket_service_cache_timer_activity |
Logged during the routine cleanup of cache containing federated contexts. |
|
|
| sqlserver |
fedauth_ticket_service_failure |
Occurs when we encounter a failure in FedAuthTicketService layer, when authenticating the fedauth ticket/token or when doing group expansion. |
|
|
| sqlserver |
fedauth_ticket_service_success |
Logged during the success of federated authentication, including group expansion if applicable. |
|
|
| sqlserver |
fedauth_webtoken |
Logs some important claim information found in the token. |
|
|
| sqlserver |
fedauth_webtoken_failure |
Occurs when we encounter a failure in FedAuthTicketService layer, when authenticating the fedauth ticket/token or when doing group expansion. |
|
|
| sqlserver |
ffv_obtained_validation_bitmap |
Foreign file validator obtained a copy of the validation bitmap as part of establishing a new snapshot pair. |
|
|
| sqlserver |
fido_clone_update_filter_ctx_on_dir_change |
FIDO clone trace during scan |
|
|
| sqlserver |
fido_fcs_md_read_ahead_perf_metric |
FIDO Fcs metadata read ahead perf metric. |
|
|
| sqlserver |
fido_glm_rowset_cleanup |
FIDO GLM ROwset cleanup |
|
|
| sqlserver |
fido_glm_rowset_operation |
FIDO GLM Rowset operation. |
|
|
| sqlserver |
fido_glm_rowset_serialization_error |
FIDO Metadata Rowset update error. |
|
|
| sqlserver |
fido_lock_manager_message |
FIDO LM log trace. |
|
|
| sqlserver |
fido_multi_step_ddl_operation |
FIDO DDL step for multi-step DDL operation. |
|
|
| sqlserver |
fido_rm_transaction_abort |
FIDO RM abort trace. |
|
|
| sqlserver |
fido_rm_transaction_begin |
FIDO RM begin trace. |
|
|
| sqlserver |
fido_rm_transaction_commit |
FIDO RM commit trace. |
|
|
| sqlserver |
fido_rowgroup_lineage |
Fido xevent to establish rowgroup lineage. |
|
|
| sqlserver |
fido_scanner_end_database |
Fido scanner end database scan. |
|
|
| sqlserver |
fido_scanner_percent_complete |
Fido scanner percent completed. |
|
|
| sqlserver |
fido_scanner_start_database |
Fido scanner start database scan. |
|
|
| sqlserver |
fido_scanner_trace_print |
Fido scanner debug trace. |
|
|
| sqlserver |
fido_temp_db_events |
FIDO Temp DB Trace. |
|
|
| sqlserver |
fido_temp_table_mapping |
FIDO temp table name mapping |
|
|
| sqlserver |
fido_tm_transaction_abort |
FIDO TM abort trace. |
|
|
| sqlserver |
fido_tm_transaction_begin |
FIDO TM begin trace. |
|
|
| sqlserver |
fido_tm_transaction_commit |
FIDO TM commit trace. |
|
|
| sqlserver |
fido_transaction |
FIDO transaction trace. |
|
|
| sqlserver |
fido_transaction_message |
FIDO TM log trace. |
|
|
| sqlserver |
file_added_in_database |
Occurs when a database file is added into the database segment. |
|
|
| sqlserver |
find_and_kill_tm_blocking_table_drop |
Find and kill the background tuple mover task if it blocks the drop. |
|
|
| sqlserver |
foreign_log_apply_suspended |
Indicates that the foreign log apply thread is suspended with a trace flag. |
|
|
| sqlserver |
foreign_redo_hash |
|
|
|
| sqlserver |
foreign_redo_old_bsn_corruption |
|
|
|
| sqlserver |
foreign_redo_rbpex_page_dirtied |
Fired when a page from covering RBPEX is to be dirtied during foreign redo. |
|
|
| sqlserver |
fulltext_crawl_log |
Reports fulltext crawl log. |
|
|
| sqlserver |
global_query_extractor_begin |
Global Query extractor execution start. |
|
|
| sqlserver |
global_query_extractor_cancel |
Global Query extractor execution canceled. |
|
|
| sqlserver |
global_query_extractor_end |
Global Query extractor execution completed successfully. |
|
|
| sqlserver |
global_query_extractor_fail |
Global Query extractor execution failed with error. |
|
|
| sqlserver |
hadr_chimera_send_request_to_MS_long_retry |
Alert for long retries when sending notification request to control ring |
|
|
| sqlserver |
hadr_db_manager_qds_msg |
QDS messages sent between replicas. |
|
|
| sqlserver |
hadr_hybrid_subscription_auth_failure |
Log ucs subscription authentication failure for hybrid link. |
|
|
| sqlserver |
hadr_hybrid_subscription_auth_long_retry |
Log ucs subscription authentication retry info for hybrid link. |
|
|
| sqlserver |
hadr_hybrid_subscription_auth_success |
Log ucs subscription authentication success for hybrid link. |
|
|
| sqlserver |
hadr_transport_dump_extended_recovery_forks_message |
Use this event to help trace HADR extended recovery forks messages. |
|
|
| sqlserver |
hadr_undo_of_redo_pages_processing_stats |
Pages processing stats |
|
|
| sqlserver |
hadr_undo_of_redo_parallel_page_requesting_first_missing_page |
First missing page id in parallel page request buffer. |
|
|
| sqlserver |
hadr_undo_of_redo_parallel_page_requesting_notification |
Requesting page in parallel for Undo of Redo enabled. |
|
|
| sqlserver |
hardware_error_rbpex_invalidate_page |
Tracks invalidating rbpex page after detecting a hardware error on the page. |
|
|
| sqlserver |
heap_access_pattern |
Emit statistics related to heap access patterns. |
|
|
| sqlserver |
hotpagetracker_bucket_aggregation_ended |
Indicates that aggregating hit counts into the snapshot bucket at given position in the bucket list ended. |
|
|
| sqlserver |
hotpagetracker_bucket_aggregation_started |
Indicates that aggregating hit counts into the snapshot bucket at given position in the bucket list started. |
|
|
| sqlserver |
hotpagetracker_page_list_receive_failed |
Indicates that the new primary compute has NOT received the list of hot pages it requested from a page server. |
|
|
| sqlserver |
hotpagetracker_page_list_receive_succeeded |
Indicates that the new primary compute has received the list of hot pages it requested from a page server. |
|
|
| sqlserver |
hotpagetracker_pageseed_candidate |
A page that the new primary compute will seed into its RBPEX for a given file. |
|
|
| sqlserver |
hotpagetracker_pageseed_failed |
Indicates that the new primary compute has failed to queue all the hot pages to seed onto its RBPEX for a given file. |
|
|
| sqlserver |
hotpagetracker_pageseed_queued |
Indicates that the new primary compute has queued all the hot pages to seed onto its RBPEX for a given file. |
|
|
| sqlserver |
hyperscale_no_pushdown |
QP pushdown not available. |
|
|
| sqlserver |
hyperscale_pushdown_aggregated_stats |
Aggregated stats for a single execution of a single QP pushdown operator. |
|
|
| sqlserver |
hyperscale_pushdown_completed |
QP pushdown queue completed. |
|
|
| sqlserver |
hyperscale_pushdown_memory_change |
QP pushdown memory reservation change. |
|
|
| sqlserver |
hyperscale_pushdown_request_completed |
QP pushdown request completed. |
|
|
| sqlserver |
hyperscale_pushdown_request_starting |
QP pushdown request starting. |
|
|
| sqlserver |
hyperscale_pushdown_resource_pool_failure |
Failures related to obtaining resource pool for pushdown queries |
|
|
| sqlserver |
hyperscale_pushdown_skipped |
QP pushdown skipped at runtime. |
|
|
| sqlserver |
hyperscale_pushdown_starting |
QP pushdown queue created. |
|
|
| sqlserver |
hyperscale_pushdown_stats |
QP pushdown statistics that are periodically emitted. |
|
|
| sqlserver |
iam_page_range_cache_stats |
IAM Page range cache stats |
|
|
| sqlserver |
increment_paused_write_ios_count |
Increments the number of write IOs paused. |
|
|
| sqlserver |
index_corruption_detected |
Reports names,id of related database when index corruption is detected |
|
|
| sqlserver |
index_stats_inconsistency_event |
Indicate we did some repair logic for the index stats cache |
|
|
| sqlserver |
kerberos_to_jwt_service_failure |
Occurs when we encounter error in Kerberos ticket to JSON Web token conversion through ESTS AAD endpoint. |
|
|
| sqlserver |
large_non_adr_transactions |
The number of records and/or bytes of log for a non-ADR transaction exceeds the current threshold. |
|
|
| sqlserver |
ledger_digest_upload_failed |
Uploading a digest of the database ledger failed. |
|
|
| sqlserver |
ledger_digest_upload_failed_mdm |
Emit a metric when a ledger digest fails to be uploaded. |
|
|
| sqlserver |
ledger_digest_upload_success |
Uploading a digest of the database ledger succeeded. |
|
|
| sqlserver |
ledger_digest_upload_success_mdm |
Emit a metric when a ledger digest is successfully uploaded. |
|
|
| sqlserver |
ledger_generate_digest |
Ledger digest generated |
|
|
| sqlserver |
ledger_settings |
Ledger settings |
|
|
| sqlserver |
ledger_table_verification_completed |
Ledger table verification operation completed. |
|
|
| sqlserver |
ledger_table_verification_started |
Ledger table verification operation started. |
|
|
| sqlserver |
ledger_transaction_count |
Ledger transaction |
|
|
| sqlserver |
ledger_verification_completed |
Ledger verification operation completed. |
|
|
| sqlserver |
ledger_verification_started |
Ledger verification operation started. |
|
|
| sqlserver |
ledger_view_query_count |
Ledger view query |
|
|
| sqlserver |
lock_manager_init |
Stats during init of lock manager |
|
|
| sqlserver |
locking_qp_stats |
Emit QP statistics related to locking. |
|
|
| sqlserver |
locking_stats |
Emit statistics related to locking. |
|
|
| sqlserver |
log_block_header_failover_info |
Print failover info stored in log block header during LC flush |
|
|
| sqlserver |
log_lease_skip_same_vlf |
Indicates that the request to the log leasing service for the same vlf is skipped |
|
|
| sqlserver |
log_pool_cache_miss_aggregation |
Aggregated outout of log pool miss. |
|
|
| sqlserver |
log_production_stats_mdm |
Aggregated statistics about log production, emitted periodically. |
|
|
| sqlserver |
log_redo_stats |
|
|
|
| sqlserver |
long_compilation_progress |
Collect the compilation progress information for long-running compilations. |
|
|
| sqlserver |
management_service_operation_failed |
Management Service operation failed. |
|
|
| sqlserver |
management_service_operation_started |
Management service operation started. |
|
|
| sqlserver |
management_service_operation_succeeded |
Management service operation succeeded. |
|
|
| sqlserver |
maxdop_feedback_received |
|
|
|
| sqlserver |
memory_grant_feedback_percentile_grant |
Occurs at intervals when percentile grant is enabled |
|
|
| sqlserver |
memory_grant_feedback_persistence_invalid |
Occurs when persisted memory grant feedback can not be used due to inconsistency with current plan. |
|
|
| sqlserver |
memory_grant_feedback_persistence_update |
Occurs when memory grant feedback is persisted to QDS. |
|
|
| sqlserver |
metadata_change |
Tracking metadata change which may affect query performance. |
|
|
| sqlserver |
modify_file_name |
Occurs when the file manager started to modify a database file name. |
|
|
| sqlserver |
modify_file_operation |
Occurs when the file manager modified the property of a database file. |
|
|
| sqlserver |
native_shuffle_nullability_mismatch |
Reports a NULL value in a native shuffle QTable column declared with NOT NULL in the schema. |
|
|
| sqlserver |
oiblob_cleanup_begin_batch |
Occurs when cleanup for a single batch has started for online index build with LOBs. |
|
|
| sqlserver |
oiblob_cleanup_end_batch |
Occurs when cleanup for a single batch has finished for online index build with LOBs. |
|
|
| sqlserver |
oledb_provider_initialized |
Occurs when SQL Server initializes an OLEDB provider for a distributed query or remote stored procedure. Use this event to monitor OLEDB provider initialization. This event will be triggered once when a particular provider is initialized. It is also used for reporting type of mapping used for linked servers. |
|
|
| sqlserver |
online_index_ddl_tx_info |
Log record- and transaction-related info about the non-CTR ONLINE_INDEX_DDL transaction. |
|
|
| sqlserver |
openrowset_bulk_file_resolvement |
Occurs when updating resolved files within openrowset bulk statement. |
|
|
| sqlserver |
openrowset_bulk_schema_inference |
Occurs during schema inference in openrowset bulk statement. |
|
|
| sqlserver |
openrowset_cardinality_query |
Fires after executing internal sampled cardinality estimation query. |
|
|
| sqlserver |
openrowset_stats_cleanup |
Fires at the start and after stats table cleanup finishes. |
|
|
| sqlserver |
openrowset_stats_cleanup_all |
Fires at the start and after stats table truncation finishes. |
|
|
| sqlserver |
openrowset_stats_creation |
Fires after computing openrowset stats. |
|
|
| sqlserver |
openrowset_stats_loading |
Fires after loading openrowset stats. |
|
|
| sqlserver |
openrowset_stats_row_reading_failed |
Fires when reading of openrowset stats/cardinality row from the openrowset stats table fails. |
|
|
| sqlserver |
openrowset_stats_stale_detection |
Fires after algorithm for stale stats detection finishes. |
|
|
| sqlserver |
openrowset_table_level_stats |
Fires after computing openrowset or external table stats on table level. |
|
|
| sqlserver |
opt_replay_delete_ors_allocated_memory |
Fired when the memory allocated for replay script (ORS) is successfully deleted. |
|
|
| sqlserver |
opt_replay_exception_info |
Collect exception info about Optimization Replay’s failure. |
|
|
| sqlserver |
override_max_supported_db_version_to_1 |
Used for mock downgrade max supported db version to 1 |
|
|
| sqlserver |
page_compression_cache_init_complete |
Occurs after page compression cache is initialized during decompression |
|
|
| sqlserver |
page_covering_rbpex_repair |
Tracks the repair of pages in covering RBPEX |
|
|
| sqlserver |
page_encryption_prewrite_complete |
Occurs after page has been compressed in-memory before being flushed |
|
|
| sqlserver |
parameter_sensitive_plan_optimization |
This event is fired when a query uses Parameter Sensitive Plan (PSP) Optimization feature. |
|
|
| sqlserver |
parameter_sensitive_plan_optimization_skipped_reason |
Occurs when the parameter sensitive plan feature is skipped. Use this event to monitor the reason why parameter sensitive plan optimization is skipped. |
|
|
| sqlserver |
parameter_sensitive_plan_testing |
Fired when parameter sensitive plan is tested. |
|
|
| sqlserver |
partition_elimination_mapping |
Fires when pruned data source is added to the list of reduced sources. |
|
|
| sqlserver |
partition_elimination_routine |
Fires when partition elimination routine gets called. |
|
|
| sqlserver |
pesto_rename_sbs_blob_fail |
Failed to update the sbs blob id with new GUID during the Pesto consoliate rowgroup copy blob |
|
|
| sqlserver |
pfs_file_share_stats |
PFS file share stats collected periodically from GetShareStats api |
|
|
| sqlserver |
pfs_observed_transition_to_secondary |
Emitted when observed DB replica role transition during evaluation period for PFS dynamic scaling |
|
|
| sqlserver |
pfs_rest_action |
PFS REST API call action. |
|
|
| sqlserver |
pfs_scaling_signal |
Output signal for PFS Dynamic Scaling |
|
|
| sqlserver |
polaris_background_task_exception |
Unexpected exceptions during execution of Polaris background task. |
|
|
| sqlserver |
polaris_billing_data_scanned |
Billing report – data size read through external extractors. Distinct event per each file and each processing thread. |
|
|
| sqlserver |
polaris_billing_data_scanned_csv |
Billing report – data size read through native CSV reader. Distinct event per each file. |
|
|
| sqlserver |
polaris_billing_data_written |
Billing report – Reports data written. |
|
|
| sqlserver |
polaris_billing_distributed_queries_executed |
Fires when VDW distributed computation was executed. |
|
|
| sqlserver |
polaris_billing_estimated_data_scanned |
Billing report – Estimated data scanned during query compilation phase. |
|
|
| sqlserver |
polaris_billing_exception |
Unexpected exceptions during data_export or distributed_move operations. |
|
|
| sqlserver |
polaris_billing_exception_managed_data |
Unexpected billing exception. |
|
|
| sqlserver |
polaris_billing_native_shuffle_data_moved |
Billing report – Reports data moved by native shuffle. |
|
|
| sqlserver |
polaris_billing_verification_distributed_queries_executed |
Fires when VDW distributed computation was executed. Should be used only for billing verification. |
|
|
| sqlserver |
polaris_budget_limit_exception |
Unexpected exceptions during SQL On-Demand budget limit related operations. |
|
|
| sqlserver |
polaris_configuration_background_task |
Configuration state changes for background tasks. |
|
|
| sqlserver |
polaris_configuration_budget_limit_change |
Configuration changes for SQL On-Demand budget limit. |
|
|
| sqlserver |
polaris_configuration_budget_limit_snapshot |
Daily configuration snapshot for SQL On-Demand budget limit. |
|
|
| sqlserver |
polaris_created_in_memory_resource_group |
Fired when Polaris background tasks resource group is initialized. |
|
|
| sqlserver |
polaris_current_state_of_data_processed |
Reports status about internal query that is calculating current state of data processed in SQL On Demand. |
|
|
| sqlserver |
polaris_error_classification_failed |
Is fired when ErrorClassificationOverrideRules setting is invalid. |
|
|
| sqlserver |
polaris_exception_query_not_billed |
Unexpected exceptions during billing related system operations. |
|
|
| sqlserver |
polaris_executed_requests_history |
|
|
|
| sqlserver |
polaris_executed_requests_history_cleanup |
Reports status about retention cleanup on master.sys.polaris_executed_requests_history and master.sys.polaris_executed_requests_text tables. |
|
|
| sqlserver |
polaris_executed_requests_retention_period |
Reports retention period used for master.sys.polaris_executed_requests_history and master.sys.polaris_executed_requests_text tables. |
|
|
| sqlserver |
polaris_failed_to_find_resource_group |
Fired when Polaris background tasks resource group is not initialized. |
|
|
| sqlserver |
polaris_internal_metrics_distributed_query_history_tables |
Fires after write to distributed query history tables fail. |
|
|
| sqlserver |
polaris_internal_tsql_query_status |
Reports status about Polaris internal T-SQL query. |
|
|
| sqlserver |
polaris_metrics_connections |
Fires after login to Polaris frontend is finished. |
|
|
| sqlserver |
polaris_metrics_data_processed |
Fires after data is processed. |
|
|
| sqlserver |
polaris_metrics_login_rh |
Fires Resource Health signal after login to Polaris frontend is finished. |
|
|
| sqlserver |
polaris_metrics_queries |
Fires after distributed query result is returned. |
|
|
| sqlserver |
polaris_metrics_query_rh |
Fires Resource Health signal after distributed query on Polaris finishes. |
|
|
| sqlserver |
polaris_rejected_rows_aggregations |
Reports status of rejected rows aggregation processing |
|
|
| sqlserver |
polaris_rejected_rows_exception |
Unexpected exceptions during rejected rows processing. |
|
|
| sqlserver |
polaris_rejected_rows_exception_details |
Details of overwritten query response exception |
|
|
| sqlserver |
polaris_unexpected_switch_value |
Is fired when unexpected switch value is encountered. |
|
|
| sqlserver |
polaris_write_distributed_query_history_exception |
Unexpected exceptions during data ingestion into polaris history tables |
|
|
| sqlserver |
predict_error |
PREDICT error |
|
|
| sqlserver |
predict_onnx_log |
ONNX log message |
|
|
| sqlserver |
private_vdw_client_batch_submitted |
Fires when query to SQL FE is submitted and log to Pii table. |
|
|
| sqlserver |
private_vdw_sql_statement_compiled |
Fires when a sql statement in SQL FE is compiled and log to Pii table. |
|
|
| sqlserver |
private_vdw_sql_statement_starting |
Fires when a sql statement is started in SQL FE and log to Pii table. |
|
|
| sqlserver |
query_abort |
Indicates that a cancel operation, client-interrupt request, or broken client connection was received, triggering abort. |
|
|
| sqlserver |
query_antipattern |
Occurs when a a query antipattern is present and can potentially affect performance. |
|
|
| sqlserver |
query_ce_feedback_telemetry |
Reports query feedback information |
|
|
| sqlserver |
query_feedback_analysis |
Reports query feedback analysis details |
|
|
| sqlserver |
query_feedback_validation |
Reports query feedback pre validation data |
|
|
| sqlserver |
query_optimizer_nullable_scalar_agg_iv_update |
Occurs when scalar indexed view with nullable aggregates is being created or updated. |
|
|
| sqlserver |
query_optimizer_optimize_insert |
Occurs when the query optimizer checks an optimization of insert is possible. |
|
|
| sqlserver |
query_post_execution_stats |
Occurs after a SQL statement is executed. This event contains stats on query execution and uses lightweight profiling infrastructure but does not have showplan xml. This event is fired only when Query Store is enabled and Query Store is tracking the query. |
|
|
| sqlserver |
query_store_hadron_transport_failures |
When QDS cannot process a message correctly this XEvent is emitted with diagnostic information. |
|
|
| sqlserver |
query_with_parameter_sensitivity |
This event is fired when a query is discovered to have parameter sensitivity. This telemetry will help us in identifying queries that |
|
are parameter sensitive and how skewed the columns involved in the query are. This is for internal analysis only. |
| sqlserver |
rbpex_compute_zone_hotness |
|
|
|
| sqlserver |
rbpex_deferring_remote_io |
RBPEX deferred remote I/O due to pending file growth. |
|
|
| sqlserver |
rbpex_eviction_run_profile |
|
|
|
| sqlserver |
rbpex_force_copy_pages_failure |
Event to force copy pages failure during RBPEX seeding. |
|
|
| sqlserver |
rbpex_grow_fail_reporting_max_size |
RBPEX grow has been failing continuously and now we are reporting max RBPEX file size as part of IDSU. |
|
|
| sqlserver |
rbpex_incremental_grow |
Tracks rbpex grow when utilization exceeds threshold. |
|
|
| sqlserver |
rbpex_is_file_growth_supported |
Occurs when RBPEX/WB checks if file growth can be deferred |
|
|
| sqlserver |
rbpex_parallel_seeding_timing |
Rbpex parallel seeding timing info. |
|
|
| sqlserver |
rbpex_pause_exclusive_phase |
Rbpex pause segment functionality test, exclusive phase wait. |
|
|
| sqlserver |
rbpex_peer_seed |
Records RBPEX peer seed activity. |
|
|
| sqlserver |
rbpex_physical_grow |
Rbpex physical growth succeeded |
|
|
| sqlserver |
rbpex_physical_shrink |
Rbpex Physical shrink not allowed to proceed |
|
|
| sqlserver |
rbpex_seed_thread_start |
Event to report start of seed thread. |
|
|
| sqlserver |
rbpex_seeding_catchup_retry |
Fired before attempting to retry segment catchup operation from blob during rbpex seeding. |
|
|
| sqlserver |
rbpex_seeding_segment_copy_retry |
Fired before attempting to retry segment copy operation from snapshot during rbpex seeding. |
|
|
| sqlserver |
rbpex_seeding_snapshot_created |
Fired when a snapshot is created for page server seeding. |
|
|
| sqlserver |
rbpex_seg_seed_copy_page |
Event to report dirty pages being copied during seeding. |
|
|
| sqlserver |
rbpex_shrinkmgr_grow |
Records RBPEX growth activity. |
|
|
| sqlserver |
rbpex_shrinkmgr_shrink |
Rbpex shrink info. |
|
|
| sqlserver |
rbpex_shrinkmgr_shrink_assert_error |
Rbpex shrink assertions errors |
|
|
| sqlserver |
rbpex_shrinkmgr_shrink_started |
|
|
|
| sqlserver |
reclaim_dropped_column_space_begin |
Occurs when reclaim space for dropped LOB columns has started. |
|
|
| sqlserver |
reclaim_dropped_column_space_end |
Occurs when reclaim space for dropped LOB columns has finished. |
|
|
| sqlserver |
recovery_catch_checkpoint |
Dirty pages will be written to advance the oldest page LSN and catch up with the current LSN. This event is only applicable to databases where indirect checkpoint is enabled. |
|
|
| sqlserver |
recovery_force_flush_checkpoint |
Dirty pages will be written to advance the oldest page LSN and catch up with the target log distance. This event is only applicable to databases where indirect checkpoint is enabled. |
|
|
| sqlserver |
recovery_indirect_checkpoint_end |
Checkpoint has ended. This event is only applicable to databases where indirect checkpoint is enabled. |
|
|
| sqlserver |
recovery_simple_log_truncate |
Dirty pages will be written to help log truncation of the simple-recovery database. This event is only applicable to databases where indirect checkpoint is enabled. |
|
|
| sqlserver |
remove_remote_file_redo_operation_completed |
RemoveFileFromRemoteReplicas Operation Completed |
|
|
| sqlserver |
remove_remote_file_redo_operation_failed |
RemoveFileFromRemoteReplicas Operation Failed |
|
|
| sqlserver |
remove_remote_file_redo_operation_started |
RemoveFileFromRemoteReplicas Operation Started |
|
|
| sqlserver |
repl_error |
This event will be fired from replication code when an error occurs. |
|
|
| sqlserver |
repl_logscan_session |
This event captures log scan operations telemetry through Replication and Change Data Capture (CDC) phases 1 through 7.Returns session transactions as they are processed. |
|
|
| sqlserver |
repl_metadata_change |
This event will be fired from replication code on changes related to replication metadata. |
|
|
| sqlserver |
repldone_session |
ReplDone Information |
|
|
| sqlserver |
required_memory_grant_too_big |
Keep the related data when the requested memory is greater than the available memory (right before throwing an exception) |
|
|
| sqlserver |
resource_governor_classifier_changed |
Occurs when Resource Governor classifier function is changed. |
|
|
| sqlserver |
resource_governor_reconfigure_classifier_details |
Shows classifier data before and after rg reconfigure. |
|
|
| sqlserver |
resource_governor_resource_pool_definition_changed |
Occurs when resource pool definition changes. |
|
|
| sqlserver |
resource_governor_workload_group_definition_changed |
Occurs when workload group definition changes. |
|
|
| sqlserver |
restore_rollfoward_complete |
RestoreRedoMachine::Rollforward function telemetry details. |
|
|
| sqlserver |
resumable_index_auto_abort |
Occurs when the resumable index has been paused for longer than the auto abort threshold. |
|
|
| sqlserver |
rowgroup_consolidation_append_blob |
Append columnstore data to existing rowgroup blob |
|
|
| sqlserver |
rowgroup_consolidation_copy_blob |
Copy the existing Roco file to another blob, update columnstore metadata and cache entries with new blob id |
|
|
| sqlserver |
rowgroup_consolidation_create_and_write_rowgroup_blob |
Flush a consolidated rowgroup blob |
|
|
| sqlserver |
rowgroup_consolidation_flush_rowgroup_blob_fail |
Attempted to flush a chunk of columnstore rowgroup data to block blob and failed. |
|
|
| sqlserver |
rpc_completed |
Occurs when a remote procedure call has completed. |
|
|
| sqlserver |
security_cache_recreate_login_token |
Recreate a login token and cache it(for existing sessions) after the security token caches have been invalidated. |
|
|
| sqlserver |
security_cache_ring_buffer |
Security Cache ring buffer telemetry. |
|
|
| sqlserver |
security_context_token_cleanup |
When a security context token is deleted. |
|
|
| sqlserver |
send_segment_io_data |
send segment access information |
|
|
| sqlserver |
send_segment_io_data_v2 |
# of IOs on a segment (simulated). |
|
|
| sqlserver |
send_segment_io_data_v2_heartbeat |
Whether segment IOs are being tracked (simulated). |
|
|
| sqlserver |
session_fedauth_failure |
Occurs when a session is attempting to set a fed auth token in an unsupported scenario. |
|
|
| sqlserver |
set_partial_log_backup_checkpoint_lsn_to_null |
Used for setting the partialLogBackupCkptLsn to NullLSN |
|
|
| sqlserver |
shallow_scan_in_view_enabled |
Indicates that shallow metadata checks are enabled early during view binding, for earlier failure detection. |
|
|
| sqlserver |
socket_dup_event |
This event is for Socket Duplication steps at SQL or Xlog side. |
|
|
| sqlserver |
sp_cloud_update_sys_databases_post_termination_completed |
Spec procedure sp_cloud_update_sys_databases_post_termination completed (with or without error). |
|
|
| sqlserver |
sp_statement_completed |
Occurs when a statement inside a stored procedure has completed. |
|
|
| sqlserver |
sp_statement_starting |
Occurs when a statement inside a stored procedure has started. |
|
|
| sqlserver |
spexec_batch_compilation_serialization |
This event will be emitted when the spexec batch compilation serialization occurs |
|
|
| sqlserver |
spills_to_tempdb |
Spills to tempdb, which were caused by any query. Only fires off when spills exceeds (predefined threshold * MaxTempdbDbMaxSizeinMB) |
|
|
| sqlserver |
sql_statement_completed |
Occurs when a Transact-SQL statement has completed. |
|
|
| sqlserver |
sql_syms_publishing |
Fires during metadata publishing to SyMS. |
|
|
| sqlserver |
sql_syms_publishing_exception |
Fires when metadata publishing to SyMS hits exception. |
|
|
| sqlserver |
sql_syms_publishing_http_request |
Fires on metadata publishing HTTP requests to SyMS. |
|
|
| sqlserver |
sr_tx_count |
XEvent that indicates a Serializable Transaction info |
|
|
| sqlserver |
srb_backup_sync_message |
Backup Sync messages sent during backup on secondary replica. |
|
|
| sqlserver |
srb_clear_diff_map_succeeded |
Backup Info message sent from primary to secondary to signal that diff map was cleared and provide a new checkpoint LSN. |
|
|
| sqlserver |
srb_commit_diff_backup |
Backup Info message sent from secondary to primary to signal that diff backup finished and that lock should be released on primary. |
|
|
| sqlserver |
srb_commit_full_backup |
Backup Info message sent from secondary to primary to signal that full backup finished and to provide neccessary information. |
|
|
| sqlserver |
srb_database_diff_backup_start_ack |
Backup Info message sent from primary to secondary to acknowledge diff backup request. |
|
|
| sqlserver |
srb_database_full_backup_start_ack |
Backup Info message sent from primary to secondary to acknowledge full backup request. |
|
|
| sqlserver |
srb_force_checkpoint_succeeded |
Backup Info message sent from primary to secondary to signal that checkpoint was executed and provide a new checkpoint LSN. |
|
|
| sqlserver |
srb_log_backup_info |
Backup Info messages sent during log backup on secondary replica. |
|
|
| sqlserver |
stale_user_tx_page_cleanup_element_removal |
Telemetry regarding how many stale elements were removed from the user transaction page cleanup hash table by version cleaner. |
|
|
| sqlserver |
startup_phase_telemetry |
Startup phase telemetry details . |
|
|
| sqlserver |
storage_engine_performance_counters |
Performance counter data produced by StoragePerfCountersRecord function |
|
|
| sqlserver |
summarized_oom_snapshot |
Out-of-memory (OOM) summary snapshot |
|
|
| sqlserver |
suppress_errors |
Alter statement execution |
|
|
| sqlserver |
synapse_link_addfilesnapshotendentry |
Called after a data export file is added to snapshot_end manifest entry |
|
|
| sqlserver |
synapse_link_buffering_row_data |
Synapse Link Buffering Row Data |
|
|
| sqlserver |
synapse_link_capture_throttling |
Synapse Link Capture Cycles Throttling |
|
|
| sqlserver |
synapse_link_db_enable |
Synapse Link enable events |
|
|
| sqlserver |
synapse_link_end_data_snapshot |
Called in LandingZoneParquetExporter at the end of successful data snapshot functionality |
|
|
| sqlserver |
synapse_link_error |
Error events from Synapse Link components |
|
|
| sqlserver |
synapse_link_info |
Synapse Link info |
|
|
| sqlserver |
synapse_link_library |
Synapse Link Call Back Events |
|
|
| sqlserver |
synapse_link_perf |
Synapse Link performance |
|
|
| sqlserver |
synapse_link_scheduler |
Synapse Link Scheduler Information |
|
|
| sqlserver |
synapse_link_start_data_snapshot |
Called in LandingZoneParquetExporter at the beginning of data snapshot functionality |
|
|
| sqlserver |
synapse_link_totalsnapshotcount |
Called when all files have been added a snapshot end entry |
|
|
| sqlserver |
synapse_link_trace |
Synapse Link trace |
|
|
| sqlserver |
synapse_sql_pool_metrics_login |
Fires after login to Synapse SQL Pool frontend completes. |
|
|
| sqlserver |
synapse_sql_pool_metrics_query |
Fires after Synapse SQL Pool query finishes. |
|
|
| sqlserver |
tail_log_cache_buffer_refcounter_change |
Occurs along with a tail log cache buffer’s reference counter being incremented or decremented. |
|
|
| sqlserver |
tail_log_cache_miss |
Occurs when a log consumer attempts to lookup a block from the tail log cache but fails to find it. |
|
|
| sqlserver |
toad_cell_tuning_metrics |
Toad cell tuning metrics event. |
|
|
| sqlserver |
toad_delete_bitmap_tuning_metrics |
Toad delete bitmap tuning metrics event. |
|
|
| sqlserver |
toad_delta_force_tuning_metrics |
Toad delta force tuning metrics event. |
|
|
| sqlserver |
toad_discovery |
Toad work discovery event. |
|
|
| sqlserver |
toad_exception |
Exception channel for the background toad tasks. |
|
|
| sqlserver |
toad_memory_pressure_notification |
Toad memory pressure notification event. |
|
|
| sqlserver |
toad_memory_semaphore_request |
Toad memory semaphore request event. |
|
|
| sqlserver |
toad_occi_tuning_metrics |
Toad OCCI tuning metrics event. |
|
|
| sqlserver |
toad_star_cell_tuning_metrics |
Toad star cell tuning metrics event. |
|
|
| sqlserver |
toad_tuning_zone_circuit_breaker |
Toad tuning zone circuit breaker event. |
|
|
| sqlserver |
toad_work_execution |
Toad work execution event. |
|
|
| sqlserver |
tsql_feature_usage_tracking |
Track usage of t-sql features in queries for the database |
|
|
| sqlserver |
user_token_cache_hit |
Successfully retrieved a user token from the cache. |
|
|
| sqlserver |
user_token_cache_miss |
When unable to retrieve a user token from the cache. |
|
|
| sqlserver |
user_token_cleanup |
When a user token is deleted. |
|
|
| sqlserver |
user_tx_page_cleanup_progress |
Emit various data about user transaction page cleanup progress. |
|
|
| sqlserver |
user_tx_page_cleanup_stats |
Emit statistics related to user transaction page cleanup hash table. |
|
|
| sqlserver |
vdw_annotations |
Collect annotations from queries. |
|
|
| sqlserver |
vdw_backend_cancel_query_feedback |
Fired by the VDW backend when query feedback submission is canceled. |
|
|
| sqlserver |
vdw_backend_prepare_query_feedback |
Fired by the VDW backend when preparing query feedback submission. |
|
|
| sqlserver |
vdw_backend_query_feedback_rpc |
Fired by the VDW backend to report query feedback status. |
|
|
| sqlserver |
vdw_backend_submit_query_feedback |
Fired by the VDW backend when query feedback submission occures. |
|
|
| sqlserver |
vdw_cancel_query_completion |
Fired by the VDW SQL FE when query completed notification submission is canceled. |
|
|
| sqlserver |
vdw_cetas_drop_ext_table_metadata |
Fires if the DML part of a CETAS fails in pre-Gen3 Polaris. |
|
|
| sqlserver |
vdw_client_batch_cancelled |
Fires when query to SQL FE is cancelled. |
|
|
| sqlserver |
vdw_client_batch_completed |
Fires when query to SQL FE is completed. |
|
|
| sqlserver |
vdw_client_batch_submitted |
Fires when query to SQL FE is submitted. |
|
|
| sqlserver |
vdw_distributed_computation_error |
Fires when returning error or warning reported by code related to VDW distributed computation. |
|
|
| sqlserver |
vdw_distributed_computation_rpc |
Fires when RPC for VDW distributed computation was requested. |
|
|
| sqlserver |
vdw_distributed_query_cleanup_exception |
Unexpected exception during cleanup of VDW distributed operator. |
|
|
| sqlserver |
vdw_distributed_query_metrics |
Fired by the VDW backend to report collected metrics when going out of sp_executesql_metrics scope. |
|
|
| sqlserver |
vdw_file_format_parser_version_usage |
Fired by the VDW frontend during resolve operation of parser version for provided format. |
|
|
| sqlserver |
vdw_file_level_sampling |
Fired by the VDW backend instance for OPENROWSET(BULK) queries that use TABLESAMPLE clause. |
|
|
| sqlserver |
vdw_logical_file_splits |
Emits information related to logical file splits. |
|
|
| sqlserver |
vdw_logical_file_splits_memo_generation |
Emits information related to logical file splits after memo generation. |
|
|
| sqlserver |
vdw_prepare_query_completion |
Fired by the VDW SQL FE when preparing query completed notification submission. |
|
|
| sqlserver |
vdw_query_completion_rpc |
Fired by the VDW SQL FE to notify ES FE that the query is completed. |
|
|
| sqlserver |
vdw_sp_drop_storage_location |
Fired by the VDW frontend from stored procedure sp_drop_storage_location. |
|
|
| sqlserver |
vdw_sql_statement_compiled |
Fires when a sql statement in SQL FE is compiled. |
|
|
| sqlserver |
vdw_sql_statement_completed |
Fires when a sql statement is completed in SQL FE. |
|
|
| sqlserver |
vdw_sql_statement_fido_transaction |
SQL FE statement and fido transaction trace. |
|
|
| sqlserver |
vdw_sql_statement_starting |
Fires when a sql statement is started in SQL FE. |
|
|
| sqlserver |
vdw_statement_execution |
Fires when VDW query execution starts or completed. |
|
|
| sqlserver |
vdw_submit_query_completion |
Fired by the VDW SQL FE when query completed notification submission occures. |
|
|
| sqlserver |
vdw_wildcard_expansion |
Fired by the VDW frontend when wildcard expansion was requested. |
|
|
| sqlserver |
vdw_wildcard_list_directory_stats |
Fired by the VDW frontend when wildcard expansion was requested. Contains information about each list directory call in WCE. |
|
|
| sqlserver |
version_cleaner_worker_stealing |
Version cleaner worker stealing. |
|
|
| sqlserver |
vldb_geodr_applied_throttling |
|
|
|
| sqlserver |
vldb_geodr_throttling_stat |
|
|
|
| sqlserver |
vm_msi_access_token_retrieval |
Request access token for Azure virutal machine MSI. |
|
|
| sqlserver |
volume_entity_stats |
latency histogram for volume entity. |
|
|
| sqlserver |
volume_traffic_policer_stats |
Reports stats on conforming and non-conforming IOs in terms of IOPS and Bandwidth governances |
|
|
| sqlserver |
wait_for_redo_lsn_to_catchup_pagestats |
In every 5 minutes interval,stats data of RedoPageType and RedoLocation is emitted |
|
|
| sqlserver |
wait_for_redo_lsn_to_catchup_stats |
In every 5 minutes interval,stats data of waitforlsn is emitted |
|
|
| sqlserver |
wb_checkpoint_failed_ios |
Logs failed ios during WB checkpoint. |
|
|
| sqlserver |
wb_checkpoint_metadata |
Traces foreign log state for write behind checkpoint progress. |
|
|
| sqlserver |
wb_checkpoint_progress |
Monitors progress of write behind checkpoint. |
|
|
| sqlserver |
wb_checkpoint_report_file_size |
This xevent is fired when rbpex write behind checkpoint handle physical file growth. |
|
|
| sqlserver |
wb_checkpoint_skip_file_growth |
This xevent is fired when rbpex write behind checkpoint abort deferred physical file growth. |
|
|
| sqlserver |
wb_recovery_progress |
Write behind recovery stats. |
|
|
| sqlserver |
wb_throttle_info |
Monitors info determining write behind throttling. |
|
|
| sqlserver |
webtoken_generator_failure |
Occurs when we encounter a failure during JWT creation with JSONWebTokenGenerator class. |
|
|
| sqlserver |
wildcard_expansion |
Fired by the SQL frontend when wildcard expansion was requested. |
|
|
| sqlserver |
worker_migration_stats |
Shows the number of worker migrations for a particular task. |
|
|
| sqlserver |
xact_outcome_list_cleanup_completed |
XEvent used to indicate that outcome list cleanup (via specproc) has completed. |
|
|
| sqlserver |
xact_outcome_list_cleanup_performed |
XEvent used to indicate that outcome list cleanup was performed on a database. |
|
|
| sqlserver |
xact_outcome_list_cleanup_starting |
XEvent used to indicate that outcome list cleanup (via specproc) is starting. |
|
|
| sqlserver |
xact_outcome_status |
Periodically fired XEvent to indicate current count of xact outcomes in the outcome list. |
|
|
| sqlserver |
xfile_storage_file_operation_metrics |
Storage file operation metrics. |
|
|
| sqlserver |
xfile_stream_reader_operation_metrics |
Stream reader operation metrics. |
|
|
| sqlserver |
xio_lease_action |
Lease request to Windows Azure Storage. |
|
|
| sqlserver |
xio_lease_action_sensitive |
Lease request to Windows Azure Storage. Contains PII data. |
|
|
| sqlserver |
xio_read_complete_sensitive |
Read complete from Windows Azure Storage response. Sensitive data. |
|
|
| sqlserver |
xio_request_reissue_finished_first |
Event fired when request which was reissued finishes before original request. |
|
|
| sqlserver |
xio_request_reissue_read_stats |
Contains information about data read with reissuing of long requests. |
|
|
| sqlserver |
xio_request_retry_finished_first |
Request that was part of parallel retry due to long request duration time finished first. |
|
|
| sqlserver |
xio_request_retry_finished_first_sensitive |
Request that was part of parallel retry due to long request duration time finished first. Contains PII data. |
|
|
| sqlserver |
xml_compression_telemetry |
Xml Compression telemetry collected per query |
|
|
| sqlserver |
xodbc_cache_get_federated_user_info_cache_bypass |
Occurs when a federated user cache lookup request bypasses the cache and executes a DB query. |
|
|
| sqlserver |
xodbc_cache_get_federated_user_info_failure |
Occurs when a remote authentication request to logical master failed to query for federated user info. |
|
|
| sqlserver |
xodbc_cache_update_federated_user_info_cache_entry |
Occurs when a federated user, has a name that matches object ID, and the name is updated with the correct value during login. |
|
|
| sqlserver |
xstore_aad_token_failure |
Occurs when we encounter a failure in XStoreAADTokenCache layer, when performing refresh to the AAD token |
|
|
| sqlserver |
xstore_create_physical_file |
Creating physical XStore file has been attempted with the options below. |
|
|
| sqlserver |
xstore_create_physical_file_sensitive |
Creating physical XStore file has been attempted with the options below. Contains sensitive data |
|
|
| sqlserver |
xstore_io_throttling_storage_account_removed |
XStore I/O throttling handler has removed storage account. |
|
|
| sqlserver |
xtp_db_page_allocation_state_change |
Indicates that the state of page allocations for the database is changed, from allowed to disallowed or vice versa. |
|
|
| sqlserver |
xtp_open_existing_database |
Indicates the XTP open existing database progress. |
|
|
| ucs |
ucs_connection_stats |
UCS transport connection periodic statistics |
|
|
| ucs |
ucs_task_count |
UCS task manager task count number |
|
|
| ucs |
ucs_transmitter_block_send_transport_not_ready |
UCS transmitter block send if transport not in ready state |
|
|
| ucs |
ucs_transmitter_destination_init |
UCS transmitter destination initiation |
|
|
| ucs |
ucs_transmitter_notify_destination_status_change_event |
UCS transmitter destination notifed of stream status change |
|
|
| ucs |
ucs_transmitter_send_backoff_to_be_added |
UCS transmitter service failed send enough times that a backoff will be added |
|
|
| ucs |
ucs_transmitter_send_stats |
UCS transmitter service stats on send for each index |
|
|
| ucs |
ucs_transmitter_skip_transport_reconnection_check |
UCS transmitter destination skipping check for transport reconnects |
|
|
| ucs |
ucs_transmitter_skip_transport_stream_reconnection |
UCS transmitter destination skipping transport reconnect due to recheck |
|
|
| ucs |
ucs_transmitter_transport_reconnect |
UCS transmitter destination submitted a transport stream reconnect request due to the transport stream being disconnected |
|
|
| ucs |
ucs_transmitter_transport_reconnect_all_check |
UCS transmitter destination check to see if we need to reconnect all transport streams due to ip/port or dns names of connection targets being different |
|
|
| XeSqlFido |
fido_catalog_get_buckets |
FIDO Physical Catalog Get Buckets. |
|
|
| XeSqlFido |
fido_catalog_get_cache_version |
FIDO Physical Catalog Cache Get. |
|
|
| XeSqlFido |
fido_catalog_sync |
FIDO Physical Catalog Sync Event. |
|
|
| XeSqlFido |
fido_catalog_update_cache_version |
FIDO Physical Catalog Cache Update. |
|
|
| XeSqlFido |
fido_catalog_update_version |
FIDO Physical Catalog Update Server version. |
|
|
| XeSqlFido |
fido_catalog_version |
FIDO Physical Catalog Get Server version. |
|
|
| XeSqlFido |
fido_clone_inherited_directory_info |
FIDO clone inherited directory info. |
|
|
| XeSqlFido |
fido_clone_reference_info |
FIDO clone reference info. |
|
|
| XeSqlFido |
fido_fork_entries |
FIDO fork entries |
|
|
| XeSqlFido |
fido_garbage_collection_drop_blob_info |
FIDO Garbage Collection dropped blob info |
|
|
| XeSqlFido |
fido_garbage_collection_task |
FIDO Garbage Collection task |
|
|
| XeSqlFido |
fido_garbage_collection_task_end |
FIDO Garbage Collection Task End XEvents |
|
|
| XeSqlFido |
fido_garbage_collection_task_failure |
FIDO Garbage Collection task failed |
|
|
| XeSqlFido |
fido_garbage_collection_task_start |
FIDO Garbage Collection Task Start XEvents |
|
|
| XeSqlFido |
fido_glm_alter_txn_operation |
FIDO GLM Alter Txn operation. |
|
|
| XeSqlFido |
fido_glm_backup |
FIDO GLM Server Backup. |
|
|
| XeSqlFido |
fido_glm_client_sync |
FIDO GLM Client Sync. |
|
|
| XeSqlFido |
fido_glm_execute_ddl_cached |
FIDO GLM Execute DDL from Cache. |
|
|
| XeSqlFido |
fido_glm_glog_truncate |
FIDO GLog truncation. |
|
|
| XeSqlFido |
fido_glm_pit_db_create |
FIDO PIT DB Create. |
|
|
| XeSqlFido |
fido_glm_pit_db_create_failed |
FIDO GLM PIT DB create failed. |
|
|
| XeSqlFido |
fido_glm_pit_db_drop |
FIDO PIT DB destroyed. |
|
|
| XeSqlFido |
fido_glm_pit_db_drop_fail |
FIDO PIT DB drop failed. |
|
|
| XeSqlFido |
fido_glm_restore |
FIDO GLM Client Restore. |
|
|
| XeSqlFido |
fido_glm_send_ucs_request |
FIDO GLM Send UCS request. |
|
|
| XeSqlFido |
fido_glm_send_ucs_response |
FIDO GLM Send UCS response. |
|
|
| XeSqlFido |
fido_indexstore_stats |
FIDO index store stats message. |
|
|
| XeSqlFido |
fido_lock_manager_trace |
FIDO LM message. |
|
|
| XeSqlFido |
fido_log_trace |
FIDO log trace. |
|
|
| XeSqlFido |
fido_log_trace_sensitive |
FIDO PII log trace. |
|
|
| XeSqlFido |
fido_metadata_cleanup |
FIDO GLMS cleanup |
|
|
| XeSqlFido |
fido_perf_metric |
FIDO perf metric. |
|
|
| XeSqlFido |
fido_rowgroup_visibility_info |
FIDO Is Rowgroup visible. |
|
|
| XeSqlFido |
fido_rowset_blob_directory |
FIDO rowset blob directory. |
|
|
| XeSqlFido |
fido_rsc_version_tracking_task |
FIDO RSC Version Tracking Task |
|
|
| XeSqlFido |
fido_rsc_version_tracking_task_end |
FIDO RSC Version Tracking Task End XEvents |
|
|
| XeSqlFido |
fido_rsc_version_tracking_task_failure |
FIDO RSC Version Tracking Task failed |
|
|
| XeSqlFido |
fido_rsc_version_tracking_task_start |
FIDO RSC Version Tracking Task Start XEvents |
|
|
| XeSqlFido |
fido_sequence_info |
FIDO sequence message |
|
|
| XeSqlFido |
fido_spaceused_info |
FIDO spaceused message |
|
|
| XeSqlFido |
fido_t_sql_exception |
FIDO T-SQL execution failed. |
|
|
| XeSqlFido |
fido_transport_message_trace |
FIDO transport message traces |
|
|
| XtpEngine |
xtp_shutdown_close_hk_ckpt_ctrl |
Indicates the XTP checkpoint uninitialize progress. |
|
|
| XtpEngine |
xtp_shutdown_free_hk_internal_database |
Indicates the XTP shutdown progress. |
|
|
| XtpRuntime |
xtp_create_database |
Indicates the XTP create or open database progress. |
|
|