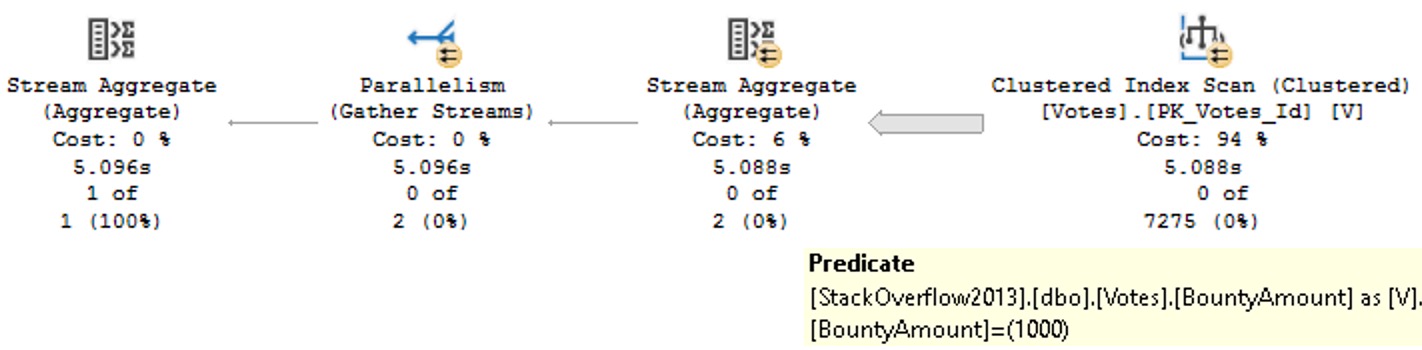
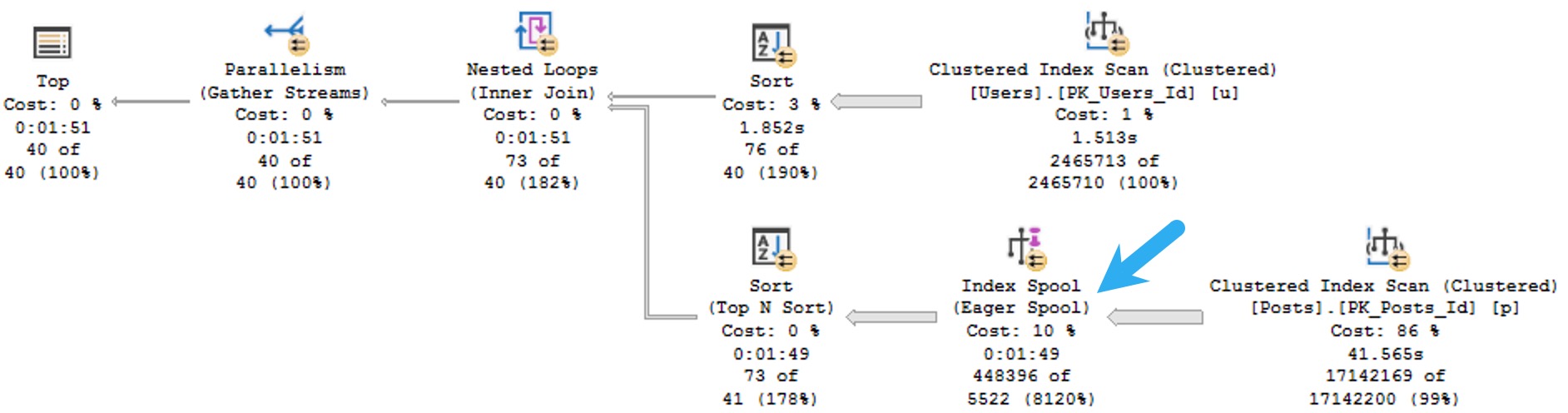
Whew. That’s not even all of it. I should get out more.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Execution plans have come a long way over the years, gradually adding more and more details as computing power becomes less of a hurdle to collecting metrics.
The thing is, it’s not always obvious where to look or dig deeper into a query plan to figure out where problems are.
Right now, there are some warnings:
At the root operator for a few different things
For memory consuming operators when they spill
But there are some other things in query plans that should be loud and clear, because they’re not going to be obvious to folks just getting started out reading query plans.
Non-SARGable Predicates:
These can cause a lot of issues:
Unnecessary scans
Poor cardinality estimates
It’s primarily caused by:
function(column) = something
column + column = something
column + value = something
value + column = something
column = @something or @something IS NULL
column like ‘%something’
column = case when …
value = case when column…
Mismatching data types (implicit conversion)
The thing is, it’s hard to see where this stuff happens in a plan, unless the plan is very small, or you’re looking directly at the query text, which is often truncated when pulled from a query plan. It would be nice if we got a warning of some sort on operators where this happened.
Predicates That Result In Scans
If you write a where clause, but don’t have an index with a key that matches that where clause, sometimes you’ll get a missing index request and sometimes you won’t. It’s a bit of a gamble of course.
For large tables, this can be painful, burn a lot of CPU, and result in a parallel plan where you could get by without one if you had a better index in place.
bigscan4u
Of course, not every scan has a predicate: think joins without a where clause, or where only one table has a predicate against it. You don’t have much choice but to scan an index.
Eager Index Spools
Sometimes SQL Server wants an index so badly that it creates one on its own for you. When this happens on a large enough table, you can spend an awful lot of time waiting for it.
You know like when you put something in the microwave and you’re standing there staring at the timer and even though you set it for two minutes it seems to hang out at 1:30 forever? That’s what an Eager Index Spool is like. A Hungry Man Dinner that you microwave for an hour but still comes out with ice around the edges of your Salisbury Steak.
community
Okay, I stretched that one a bit. But here’s the thing: If SQL Server is gonna spend all that time creating a temporary index for you, it should tell you. Maybe a missing index request, maybe a warning on the spool itself. Just… anything that would help alert more casual execution plan observers to the fact that an index might not be the worst idea, here.
Why Indexes Weren’t Used
I know you. You create indexes all the time, then for some strange reason your queries don’t use them, or stop using them.
When SQL Server optimizes a query, part of the flow chart is a pit stop called index matching. At this point, SQL Server looks at available indexes and then chooses to use or not use them based on various pieces of feedback.
Sometimes it’s obvious why an index wasn’t used, like if it only covers a portion of the query, or if the key columns weren’t in the best order. Other times, it’s really unclear.
It would be nice if we had reasons for that available, even if it’s only in actual plans.
Louder Warnings For Deeper Problems
Right now, SQL Server buries some information that can be really important to why a query didn’t perform well:
When estimated and actual rows or executions are way off
When something forces a query to run serially
When operators execute more than once (including rebinds and rewinds)
When rows are badly skewed across parallel threads
The thing is, like a lot of these other items on this list, it takes real digging to figure out if any of them apply to you, and if they’re why your query slowed down. They just need some basic visual indicators to draw attention to them at the right times.
Different Per-Operator Details
When you look at each individual operator in an actual execution plan, you get sort of a confusing story:
Estimated cost
Wall clock time
Actual rows
Estimated rows
Percent of actual to estimated rows
I’d throw out some of that, and show:
CPU time
Wall clock time
Actual Rows
Actual Executions
Percent of actual to estimated
It would also be nice to have per-operator wait stats at this juncture, since we’d need to know why there’s a discrepancy between CPU and wall clock time, e.g. because of blocking or waiting on some other resource.
While we’re talking about all this, it might be helpful to consider the direction plans show their work. Right to left for data and left to right for logic are… fine. I guess. But up and down might make more sense. A lot of folks I know have a tough time understanding when things happen in horizontal execution plans, where vertical plans would be far more clear.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Note the series of single quotes and + operators (though the same would happen if you used the CONCAT function), and that square brackets alone won’t save you.
The most obvious way is to use a stored procedure.
CREATE OR ALTER PROCEDURE
dbo.Obvious
(
@ParameterOne int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
END;
There are millions of upsides to stored procedures, but they can get out of hand quickly.
Also, the longer they get, the harder it can become to troubleshoot individual portions for performance or logical issues.
There are other kinds of functions in SQL Server, but these are far and away the least-full of performance surprises.
CREATE OR ALTER FUNCTION
dbo.TheOnlyGoodKindOfFunction
(
@ParameterOne int
)
RETURNS table
AS
RETURN
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
GO
Both scalar and multi-statement types of functions can cause lots of issues, and should generally be avoided when possible.
DECLARE
@sql nvarchar(MAX) = N'',
@ParameterOne int;
SELECT
@sql += N'
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
';
EXEC sys.sp_executesql
@sql,
N'@ParameterOne int',
@ParameterOne;
This kind of dynamic SQL is just as safe and reusable as stored procedures, but far less flexible. It’s not that you can’t cram a bunch of statements and routines into it, it’s just not advisable to get overly complicated in here.
Note that even though we declared @ParameterOne as a local variable, we pass it to the dynamic SQL block as a parameter, which makes it behave correctly. This is also true if we were to pass it to another stored procedure.
Forced parameterization is a great setting. It’s unfortunate that everything thinks they want to turn on optimize for adhoc workloads, which is a pretty useless setting.
You can turn it on like so:
ALTER DATABASE [YourDatabase] SET PARAMETERIZATION FORCED;
Forced parameterization will take queries with literal values and replace them with parameters to promote plan reuse. It does have some limitations, but it’s usually a quick fix to constant-compiling and plan cache flushing from unparameterized queries.
SQL Server may attempt simple parameterization in some cases, but this is not a guaranteed or reliable way to get the majority of the queries in your workload parameterized.
In general, the brunt of the work falls on you to properly parameterize things. Parameters are lovely things, which can even be output and shared between code blocks. Right now, views don’t accept parameters as part of their definitions, so they won’t help you here.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I admit that sp_prepare is an odd bird, and thankfully one that isn’t used a ton. I still run into applications that are unfortunate enough to have been written by people who hate bloggers and continue to use it, though, so here goes.
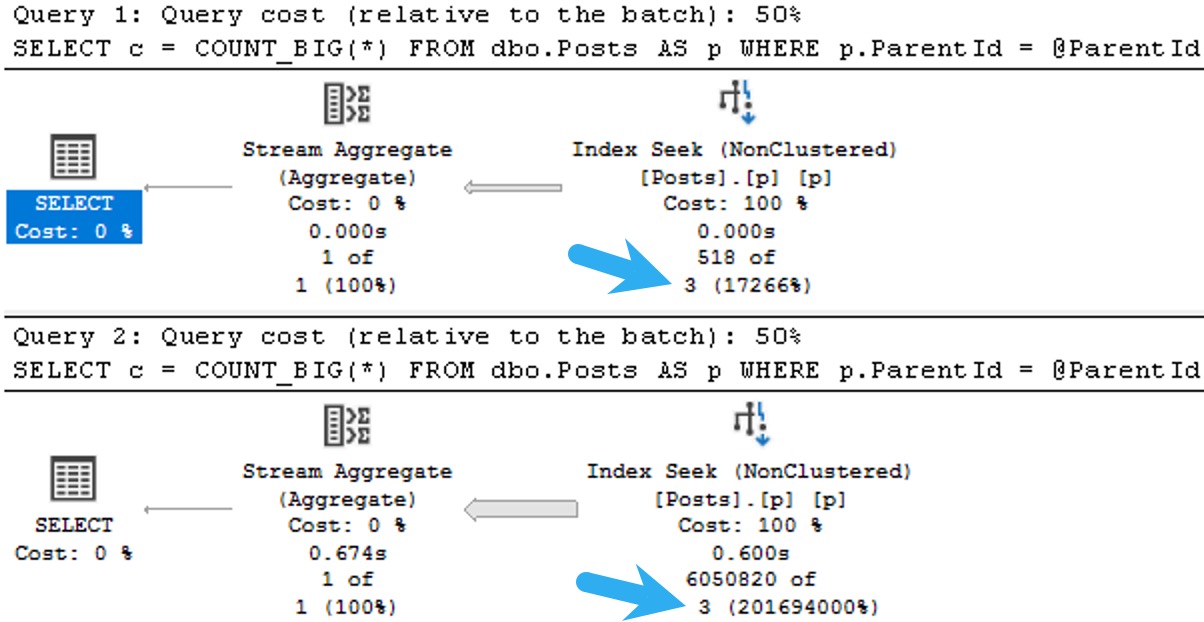
When you use sp_prepare, parameterized queries behave differently from normal: the parameters don’t get histogram cardinality estimates, they get density vector cardinality estimates.
Here’s a quick demo to show you that in action:
CREATE INDEX
p
ON dbo.Posts
(ParentId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
DECLARE
@handle int =
NULL,
@parameters nvarchar(MAX) =
N'@ParentId int',
@sql nvarchar(MAX) =
N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId;
';
EXEC sys.sp_prepare
@handle OUTPUT,
@parameters,
@sql;
EXEC sys.sp_execute
@handle,
184618;
EXEC sys.sp_execute
@handle,
0;
EXEC sys.sp_unprepare
@handle;
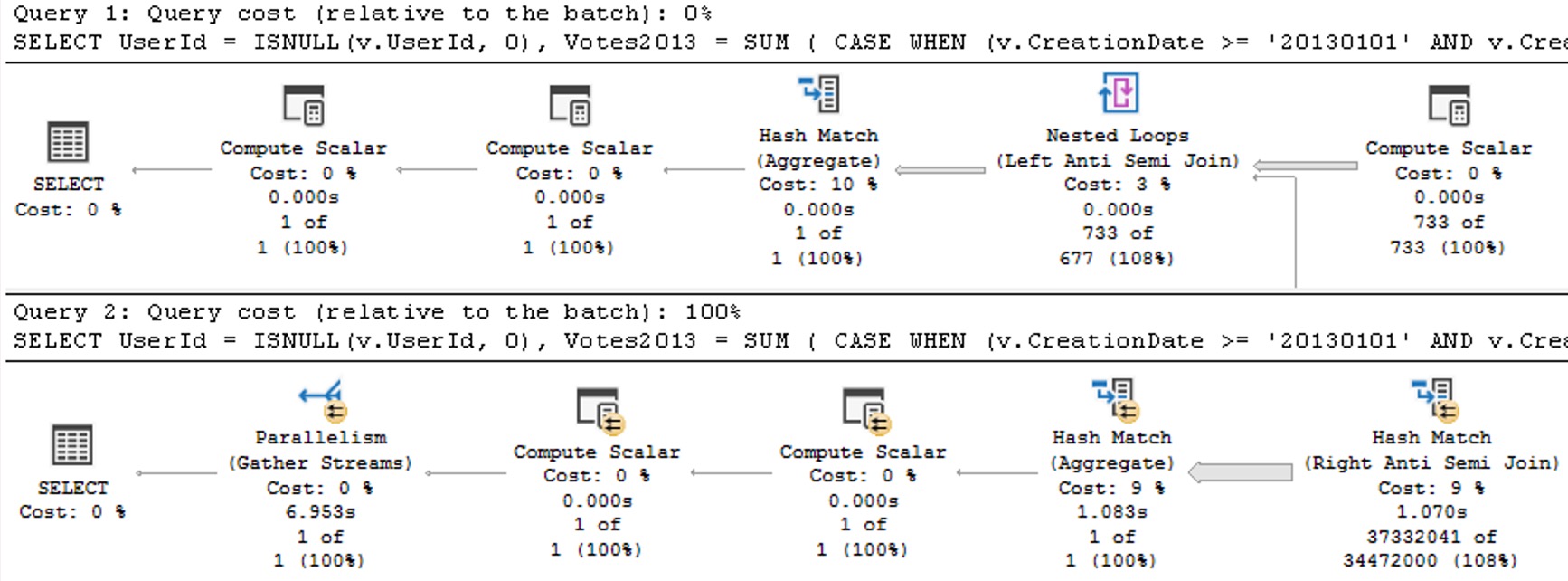
OldPlan
The plans for the two executions have the same poor cardinality estimate. In this case, since we have an ideal index and there’s no real complexity, there’s no performance issue.
But you can probably guess (at least for the second query) how being off by 201,694,000% might cause issues in queries that ask a bit more of the optimizer.
The point here is that both queries get the same incorrect estimate of 3 rows. If you add a recompile hint, or execute the same code using sp_executesql, the first query will get a histogram cardinality estimate, and the second query will reuse it.
one up
Given the historical behavior of sp_prepare, I was a little surprised that the Parameter Sensitive Plan (PSP) optimization available in SQL Server 2022 kicked in.
NewDifferent
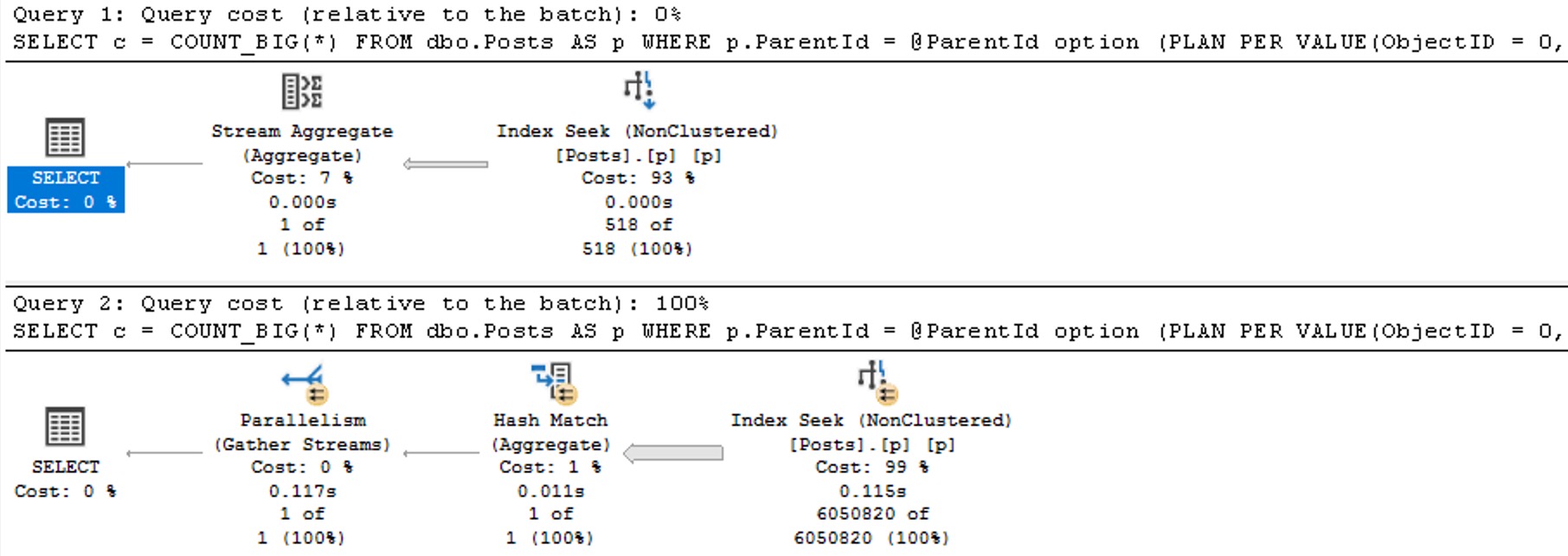
If we change the database compatibility level to 160, the plans change a bit.
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 160;
Now we see two different plans without a recompilation, as well as the plan per value option text at the end of the queries, indicating the PSP optimization kicked in.
two up
The differences here are fairly obvious, but…
Each plan gets accurate cardinality
The second plan goes parallel to make processing ~6 million rows faster
Different aggregates more suited to the amount of data in play are chosen (the hash match aggregate is eligible for batch mode)
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
This is a short post that I wanted to write on the heels of doing a bunch of work in sp_QuickieStore.
Many times, pulling data out of odd structures like XML or JSON can lead to difficulty in correctly typing each output element. I run into this commonly with query plan XML, of course. You may run into it elsewhere.
The main issue is that I often need to compare what comes out of those odd data structures to data stored more properly in other system views. For example:
Query Hash: Binary 8
Query Plan Hash: Binary 8
SQL Handle: Varbinary 64
Plan Handle: Varbinary 64
There’s some shenanigans you can use around big ints, but I’ve run into a lot of bugs with that. I don’t want to talk about it.
Nutty
As an example, this won’t match:
SELECT
c =
CASE
WHEN '0x1AB614B461F4D769' = 0x1AB614B461F4D769
THEN 1
ELSE 0
END;
The string does not implicitly convert to the binary 8 value. The same is true when you use varbinary values.
You might think that just converting the string to binary 8 would be enough, but no! This will still return a zero.
SELECT
c =
CASE
WHEN CONVERT(binary(8), '0x1AB614B461F4D769') = 0x1AB614B461F4D769
THEN 1
ELSE 0
END;
SELECT
no =
CONVERT(binary(8), '0x1AB614B461F4D769'),
yes = CONVERT(binary(8), '0x1AB614B461F4D769', 1);
no yes
0x3078314142363134 0x1AB614B461F4D769
The same is true with varbinary, too:
SELECT
no =
CONVERT(varbinary(64), '0x0900F46AC89E66DF744C8A0AD4FD3D3306B90000000000000000000000000000000000000000000000000000'),
yes = CONVERT(varbinary(64), '0x0900F46AC89E66DF744C8A0AD4FD3D3306B90000000000000000000000000000000000000000000000000000', 1);
no
0x30783039303046343641433839453636444637343443384130414434464433443333303642393030303030303030303030303030303030303030303030303030
yes
0x0900F46AC89E66DF744C8A0AD4FD3D3306B90000000000000000000000000000000000000000000000000000
The real answer here is to not rely on conversions, implicit or otherwise, when comparing data.
But, if you ever find yourself having to deal with some wonky binary data, this is one way to get yourself out of a scrape.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Imagine you have a rather complicated query that you want to abstract into a simple query for your less-than-with-it end users.
A view is probably a pretty good way of doing that, since you can shrink your preposterously-constructed tour through every table in the schema down to a simple select-from-one-object.
The problem is that now everyone expects it to perform well throughout all time, under any circumstances, come what may. It’s sort of like how your parents expect dinner to be $20 and tips to be 20% regardless of where they go or what they order.
Lobster? $5.
Steak? $5.
Bottle of wine? $5.
Any dessert you can imagine? $5.
Tip? Gosh, mister, another $5?
I sincerely apologize to anyone who continues to live in, or who moved to Europe to avoid tipping.
If you’d like some roommates, I have some parents you’d get along with.
Viewfinder
Creating a view in SQL Server doesn’t do anything special for you, outside of not making people remember your [reference to joke above] query.
You can put all manner of garbage in your view, make it reference another half dozen views full of garbage, and expect sparkling clean query performance every time.
Guess what happens?
Reality.
When you use views, the only value is abstraction. You still need to be concerned with how the query is written, and if the query has decent indexes to support it. In other words, you can’t just write a view and expect the optimizer to do anything special with it.
SQL Server doesn’t cache results, it only caches raw data. If you want the results of a view to be saved, you need to index it.
Take these two dummy queries, one against a created view, and the other an ad hoc query identical to what’s in the view:
CREATE OR ALTER VIEW
dbo.just_a_query
WITH SCHEMABINDING
AS
SELECT
p.OwnerUserId,
TotalScore =
ISNULL
(
SUM(p.Score),
0
),
TotalPosts =
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE
v.PostId = p.Id
)
GROUP BY
p.OwnerUserId;
GO
SELECT
p.OwnerUserId,
TotalScore =
ISNULL
(
SUM(p.Score),
0
),
TotalPosts =
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE
v.PostId = p.Id
)
AND
p.OwnerUserId = 22656
GROUP BY
p.OwnerUserId;
GO
SELECT
jaq.*
FROM dbo.just_a_query AS jaq
WHERE
jaq.OwnerUserId = 22656;
GO
The plans are identical, and identically bad. Why? Because I didn’t try very hard, and there’s no good indexes for them.
Remember when I said that’s important?
avenues lined with trees
Keep in mind this is a query with some batch mode involved, so it could be a lot worse. But both instances complete within a second or so of each other.
The horrible thing is that indexed views are so strict in SQL Server that we can’t even create one on the view in question. That really sucks. We get this error.
CREATE UNIQUE CLUSTERED INDEX
cuqadoodledoo
ON dbo.not_just_a_query
(
OwnerUserId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
Msg 10127, Level 16, State 1, Line 95
Cannot create index on view “StackOverflow2013.dbo.not_just_a_query” because it contains one or more subqueries.
Consider changing the view to use only joins instead of subqueries. Alternatively, consider not indexing this view.
Alternatively, go screw yourself. Allowing joins but not exists is somewhat baffling, since they’re quite different in that joins allow for multiple matches but exists does not. We’d have to do a lot of fancy grouping footwork to get equivalent results with a join, since distinct isn’t allowed in an indexed view in SQL Server either.
We could also pull the exists out of the view, add the Id column to the select list, group by that and OwnerUserId, index both of them, and… yeah nah.
I have no idea who’s in charge of indexed views in the product at this point, but a sufficiently lubricated republic would likely come calling with tar and feathers in the face of this injustice.
This is basic query syntax. It’s not like uh… min, max, sum, avg, except, intersect, union, union all, cross apply, outer apply, outer joins, or um, hey, is it too late for me to change careers?
The Pain In Pain Falls Painly On The Pain
You may have ended up here looking to learn all the minute differences between views and indexed views in SQL Server.
You may be disappointed in reading this post, but I can assure you that you’re not nearly as disappointed in this post as I am with indexed views in SQL Server.
They’re like one of those articles about flying cars where you read the headline and you’re like “woah, I’m living in the future”, but then three paragraphs in you find out the cars don’t really fly or drive and they might actually just be igloos that are only big enough for an Italian Greyhound or a paper plane that the author’s kid glued wheels to.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
When you’re trying to figure out how to store string data, it often seems easiest to just choose an extra long — even MAX — data type to avoid future truncation errors.
Even if you’re storing strings with a known, absolute length, developers may choose to not enforce that in the application, either via a drop down menu or other form of validation.
And so to avoid errors when users try to put their oh-so-important data in their oh-so-expensive database, we get columns added to tables that can fit a galaxy of data in them, when we only need to store an ashtray worth of data.
While getting data into those columns is relatively easy — most application inserts are single rows — getting data out of those columns can be quite painful, whether it’s searching or just presenting in the select portion of a query.
Let’s look at a couple simple examples of how that happens.
Search Engine
Let’s take a query like this one:
SELECT TOP (20)
p.Id,
p.Title,
p.Body
FROM dbo.Posts AS p
WHERE p.Body LIKE N'SQL Server%';
The Body column in the Posts table is nvarchar and MAX, but the same thing would happen with a varchar column.
If you need a simple way to remember how to pronounce those data types, just remember to Pahk yah (n)vahcah in Hahvahd Yahd.
Moving on – while much has been written about leading wildcard searches (that start with a % sign), we don’t do that here. Also, in general, using charindex or patindex instead of leading wildcard like searching won’t buy you all that much (if anything at all).
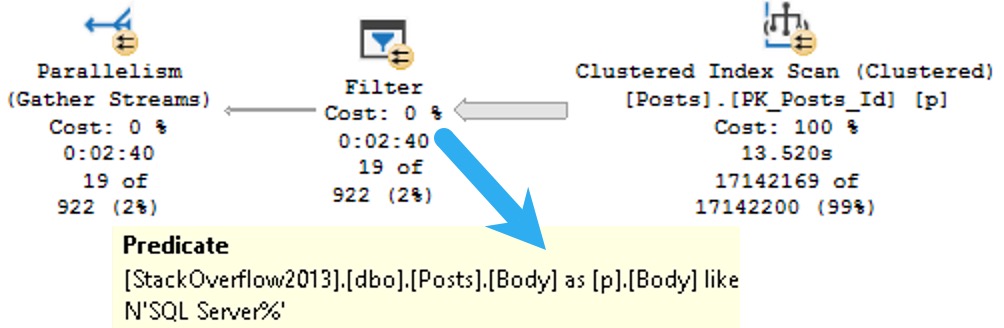
Anyway, since you can’t put a MAX datatype in the key of an index, part of the problem with them is that there’s no way to efficiently organize the data for searching. Included columns don’t do that, and so we end up with a query plan that looks some-such like this:
ouch in effect
We spend ~13.5 seconds scanning the clustered index on the Posts table, then about two minutes and twenty seven seconds (minus the original 13.5) applying the predicate looking for posts that start with SQL Server.
That’s a pretty long time to track down and return 19 rows.
Let’s change the query a little bit and look at how else big string columns can cause problems.
Memory Bank
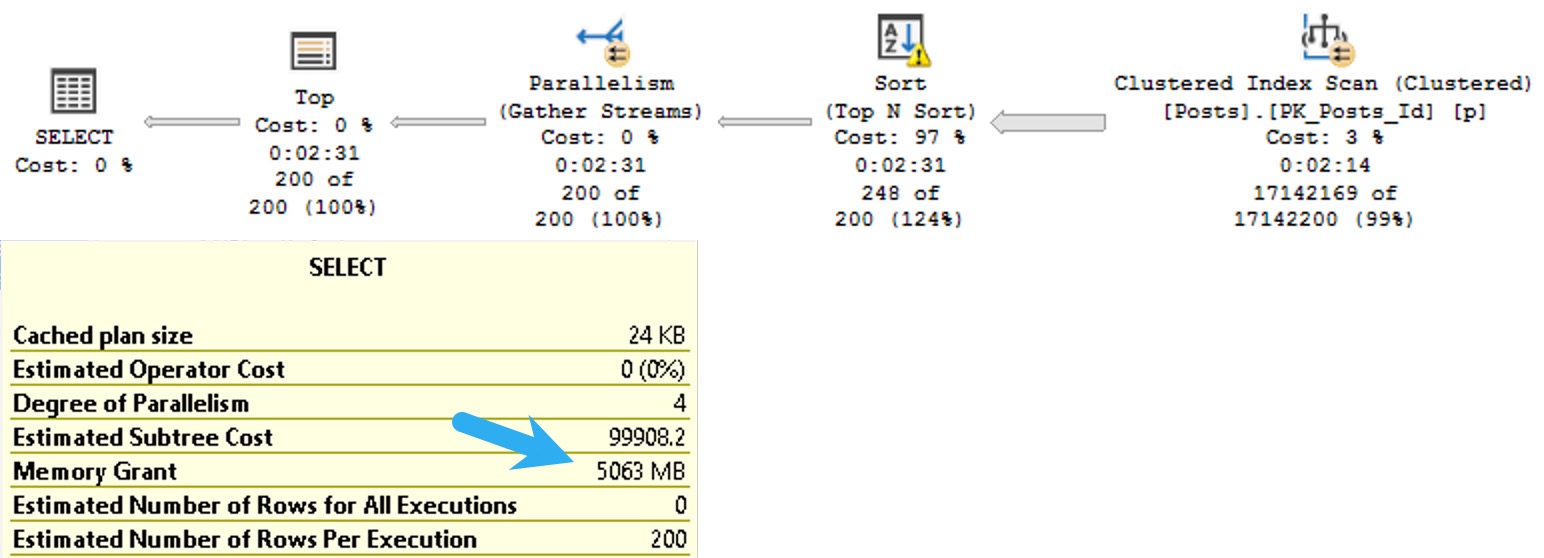
Rather than search on the Body column, let’s select some values from it ordered by the Score column.
Since Score isn’t indexed, it’s not sorted in the database. That means SQL Server needs to ask for memory to put the data we’re selecting in the order we’re asking for.
SELECT TOP (200)
p.Body
FROM dbo.Posts AS p
ORDER BY p.Score DESC;
The plan for this query asks for a 5GB memory grant:
quietly
I know what you’re thinking: the Body column probably has some pretty big data in it, and you’re right. In this case, it’s the right data type to use.
The bad news is that SQL Server will makes the same memory grant estimation based on the size of the data we need to sort whether or not it’s a good choice.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
With every release of SQL Server, Microsoft adds in a bunch of tadpole features. It’s up to those tadpoles to survive long enough to turn into beautiful uh… Frogs Toads.
The way they do that is by having enough paying customers use them — usually prodded by #MVPBuzz chasers — to get continued support and development.
All of this is subject to internal whims (like Microsoft rebranding, renaming, or rebasing a feature, take Mirroring >> Availability Groups), and external customer fancies (Tableau vs PowerBI, etc).
I feel bad for folks who latch onto these things with any sort of seriousness, like Big Data Clusters, or any of the dozens of other features that died before they could bump their butts on a log.
One marvels at the sheer number of “you better get on board” style session titles that have been molded around features where absolutely no one got on board.
Even Kubernetes (which I know isn’t a SQL Server feature) is sort of like K-Pop: Apparently millions of people like it, but I’ve never met a single person who actually uses it.
Maybe it’s more like a bot net. K-Bot? Not sure, here. I’m bad at creative writing.
They Don’t Like You Anyway
Microsoft has this weird perceived popularity issue. Perhaps it’s the diminishing self-esteem that comes with age, with SQL Server turning 30-something and all. Microsoft keeps trying to make SQL Server appeal to swaths of people who will never like it, because it’s not the shiny new thing on the block.
They won’t love you like I do.
Adding in every passing fad to the product to try to stay young and hip does a great disservice to the product as a whole, which has many addressable flaws. Microsoft dedicates countless development cycles to goofy memes that will wither on the vine shortly after the first version.
Imagine if cars still came with cassette players, but not ones that can do anything cool like play both sides without flipping the tape over, or being able to fast forward or rewind to the start or end of a track.
You’d basically have Spatial Data And The Graph Nodes in your car trying to play Garage Days Re-Re-Revisited.
Duets
I do wish the Microsoft bean counters would dance with who they brung a bit more. You know, people who need a relational database with as few bugs and preventable performance issues as possible, with useful development features, and a coherent toolset?
Clearing the minefield of pitfalls that developers fall int0 (hello, MERGE!) would allow less effort to be spent on chasing down oddball problems and more time spent developing quality features.
It’s sort of like if I had a keyboard that fixed all my typos immediately, I’d have more time to write quality blog posts that don’t need several editorial passes.
Maybe someday.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Several weeks back, I blogged about a missed opportunity with the new parameter sensitive plan feature. At the time, I thought that there was indeed sufficient skewness available to trigger the additional plan variants, and apparently some nice folks at Microsoft agreed.
I’m not gonna go into a lot of depth here, because I’m writing this while traveling, but we get the (mostly) desired outcome of two different plans being generated. Each plan is more suitable to the amount of data that the query has to process.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
SELECT * FROM #SampleTempTable WHERE id IS DISTINCT FROM 17;
I went looking for other docs examples from vendors who have had the syntax around for 10+ years, and there wasn’t anything all that much more interesting.
Mostly case expressions and whatnot.
Big deal.
Alignment
First, if I try to run either of these queries, I’ll get an error after about 6 seconds.
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
);
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS NOT DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
);
Why does it take 6 seconds to get an error? Because a few parts of the query plan have to do some work, and then finally:
Msg 512, Level 16, State 1, Line 1
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
Sort of like how sometimes you try to SUM a column and after a while you get an error about arithmetic overflow.
This is a bit annoying, because that means we need a way to return a single value to evaluate.
So Yeah…
We can’t even rewrite the queries like this to get around the error, but I do want to show you the plans.
This is why we have to wait several seconds to get an error (unless you change it to IS DISTINCT FROM ALL/ANY):
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
WHERE v.UserId = c.UserId
);
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
WHERE c.UserId IS NOT DISTINCT FROM
(
SELECT
v.UserId
FROM dbo.Votes AS v
WHERE v.UserId = c.UserId
);
Adding a where clause inside the subquery doesn’t help.
But these query plans are total motherchucking disasters, anyway. We’ll get into indexing later, but right now they both have the same shape and operators, though slightly different semantics to deal with is/is not distinct.
is not cool
Both plans run single threaded, and using Nested Loops as the physical join type, which stinks because we’re putting together two pretty big tables.
Not to mention that Eager Index Spool. What a filth.
Adding Indexes
We need these indexes to make things go any faster. Before we do anything else, let’s create these so we’re not just sitting around thumb-twiddling.
CREATE INDEX
c
ON dbo.Comments
(UserId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
CREATE INDEX
v
ON dbo.Votes
(UserId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
Thinking About It
Okay, so writing the query like we did up there isn’t going to get us anything. Perhaps my expectations are a bit too exotic.
Let’s try something a bit more austere:
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON c.UserId IS DISTINCT FROM v.UserId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON c.UserId IS NOT DISTINCT FROM v.UserId;
The first thing to be aware of here is that the IS DISTINCT FROM is an inequality predicate, so you’re stuck with Nested Loops as the physical join type:
nightmare
I ran out of care-juice waiting for this to finish, so all you’re getting is an estimated plan. The lack of an equality predicate here means you don’t have Hash or Merge join as an option.
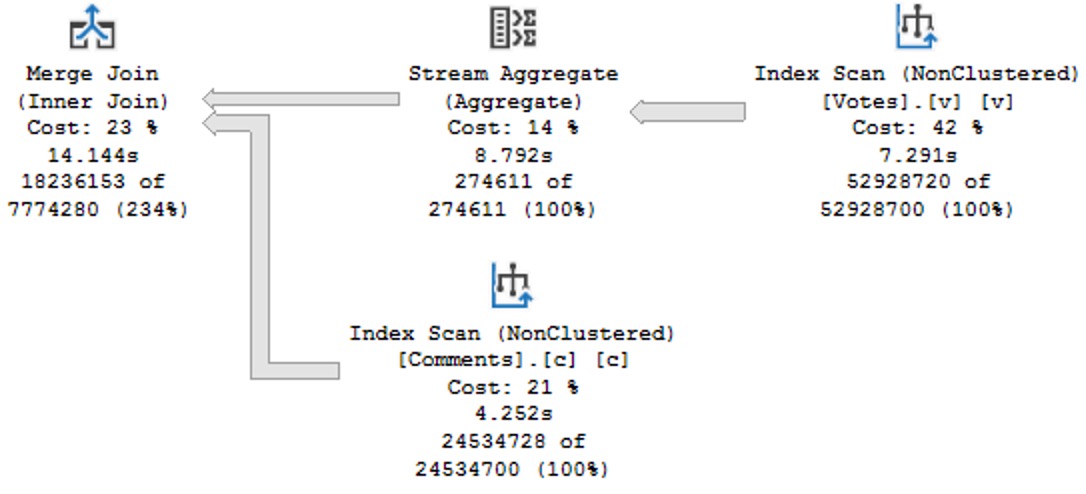
Following up on bad ideas, the IS NOT DISTINCT FROM is an equality predicate, but the plan chosen is a serial Merge Join variety, which drags on 14 seconds too long:
change up
Drop An Index
If we simulate not having any useful indexes on one table or the other by hinting the clustered index, the performance outlook does not improve.
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c WITH(INDEX = 1)
JOIN dbo.Votes AS v
ON c.UserId IS NOT DISTINCT FROM v.UserId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Comments AS c
JOIN dbo.Votes AS v WITH (INDEX = 1)
ON c.UserId IS NOT DISTINCT FROM v.UserId;
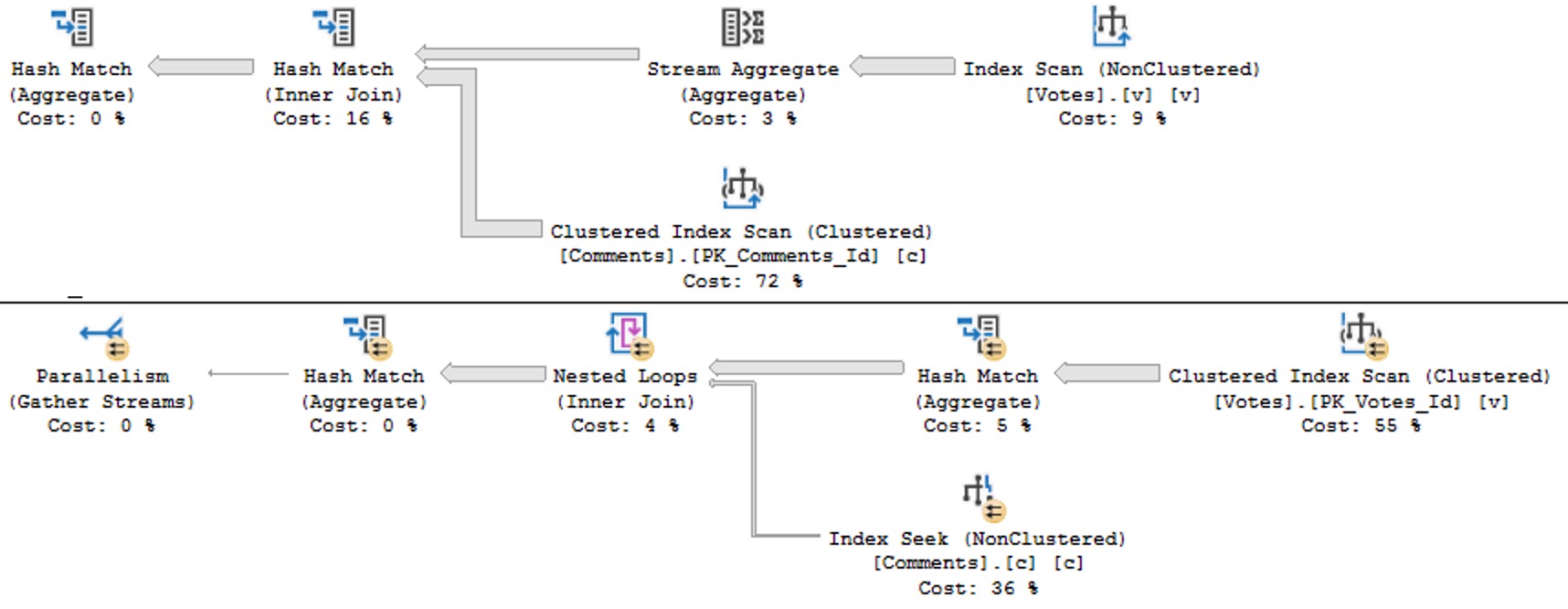
No useful parts of the first query happen in Batch Mode, but the second query is rescued by two hash aggregates happening in batch mode.
ouching
An odd point to make on a blog focused on SQL Server performance tuning is that sometimes not having a useful index gets you a better plan.
Anyway, I’m going back to my vacation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.