Columnstore compression is complicated, and in some cases, surprising.
The Setup
The source data for the CCI has enough rows to fit six perfect rowgroups. The ID column is just sequential integers from 1 to 6291456. The ID2 column is the ID column modulo 20001. Code to load the data into a temp table:
DROP TABLE IF EXISTS #STG_DATA; CREATE TABLE #STG_DATA ( ID BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID) ); INSERT INTO #STG_DATA WITH (TABLOCK) SELECT t.RN, t.RN % 20001 FROM ( SELECT TOP (6 * 1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) t;
Here’s the table definition for the target CCI:
DROP TABLE IF EXISTS dbo.TARGET_CCI; CREATE TABLE dbo.TARGET_CCI ( ID2 BIGINT NOT NULL, ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE );
The reversal of column order is important for the demo below.
Changing MAXDOP
First let’s load the ID2 column the temp table into the CCI. The order of data can matter for compression so I have a superfluous TOP expression to force SQL Server to read the data in clustered key order.
INSERT INTO dbo.TARGET_CCI WITH (TABLOCK) SELECT TOP (9876543210) ID2, 0 FROM #STG_DATA ORDER BY ID OPTION (MAXDOP 1);
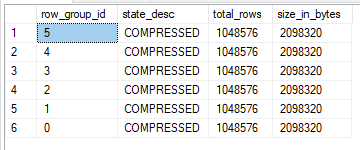
The insert query takes 2765 ms of CPU time and 2771 ms of elapsed time on my machine. According to sys.dm_db_column_store_row_group_physical_stats each rowgroup has a size of 2098320 bytes:
Now let’s move on to a parallel insert query with MAXDOP 2. The purpose of the second column in the CCI is to make the insert go parallel on my machine. It’s possible that you’ll need to use trace flag 8649 or some other trick to get a parallel insert. Here’s the code that I ran:
TRUNCATE TABLE dbo.TARGET_CCI; INSERT INTO dbo.TARGET_CCI WITH (TABLOCK) SELECT TOP (9876543210) ID2, 0 FROM #STG_DATA ORDER BY ID OPTION (MAXDOP 2);
The insert query now takes 3594 ms of CPU time and 2112 ms of elapsed time on my machine. The size of each rowgroup did not change. It’s still 2098320 bytes. Even though this is a parallel query there’s no element of randomness in this case. In the query plan we can see that the source table was scanned in a serial zone and round robin distribution is to used to distribute exactly half of the rows to each parallel thread.

This seems like a reasonable plan given that TOP forces a serial zone and we need to preserve order. It’s possible to rewrite the query to encourage a parallel scan of the source table, but that would introduce an order-preserving gather streams operator.
I’m not satisfied with the runtime yet, so I’m going to bump up MAXDOP to 3:
TRUNCATE TABLE dbo.TARGET_CCI; INSERT INTO dbo.TARGET_CCI WITH (TABLOCK) SELECT TOP (9876543210) ID2, 0 FROM #STG_DATA ORDER BY ID OPTION (MAXDOP 3);
The insert query now takes 114172 ms of CPU time and 39208 ms of elapsed time to execute. However, each rowgroup now is just 54496 bytes.
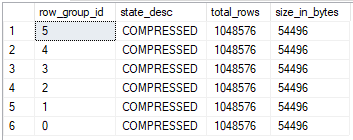
The INSERT took significantly longer than before, but we have 38X better compression compared to the table after the MAXDOP 2 query. What happened?
Revealing the Magic Trick
An interesting pattern for compressed data sizes appears when working with repeated integers for a single rowgroup. The query that I tested with was roughly of the following format:
INSERT INTO dbo.CCI SELECT t.RN % @MOD_NUM FROM ( SELECT TOP (@ROWS_INSERTED) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) t;
Below is a contour plot that shows how the compressed size for a single rowgroup varies as the number of rows and the modulus value changes:
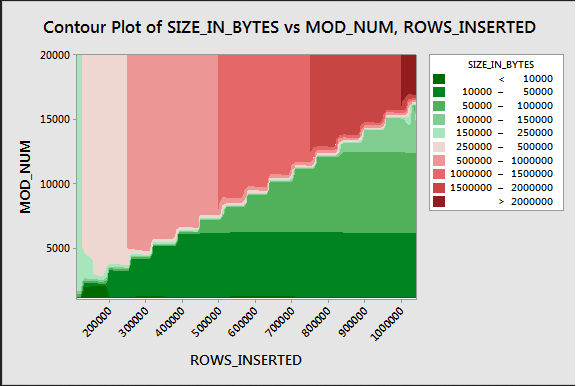
Values that are repeated 64 or more times seem to be compressed much better than other values. This pattern definitely doesn’t always hold as you add more columns to the table which is why I made the ID2 column the first column in the target CCI. Why is this pattern relevant to the previous example?
Consider the MAXDOP 1 insert query. With a full rowgroup of 1048576 rows a value will be repeated at most 1048576/20001 = 53 times in each rowgroup. It doesn’t cross the threshold of 64 so we end up with a compressed size of 2098320 bytes.
Now consider the MAXDOP 2 insert query. The ordered data from the scan is distributed using round robin distribution on two threads. For the first 20001 rows from the scan, thread 0 gets all even values and thread 1 gets all odd values. For the next 20001 rows, thread 0 gets all odd values and thread 1 gets all even values. This occurs because 20001 isn’t divisible by 2. For all six compressed rowgroups we end up with the same data distribution as we had when doing MAXDOP 1 inserts. It makes sense that the compressed size remained at 2098320 bytes.
Now consider the MAXDOP 3 insert query. The query still uses round robin distribution but there are now three threads. 20001 is divisible by 3 so thread 0 only ends up with 6667 unique values from 0, 3, … to 19999. Thread 1 also ends up with 6667 unique values from 1, 4, … to 20000. Thread 2 follows a similar pattern. Each compressed rowgroup only has 6667 unique values instead of 20001. Each value shows up at least 157 times in the rowgroup, so all of the data qualifies for much better compression.
Final Thoughts
This has absolutely no practical value. Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.