I loaded one trillion rows into a nonpartitioned table just to see what would happen. Spoiler: bad things happen.
Hardware and Table Plan
I did all of my testing on my home desktop which has an i5-4670 CPU (quad core), 5 GB of RAM for SQL Server, and a Samsung SSD 850 EVO 1 TB. Obviously not ideal to do testing like this but it was enough to get the job done. In order to fit a trillion rows into a table I had to use a CCI. Rowstore tables simply don’t offer good enough compression. For example, consider a page compressed heap with nothing but NULL values. One million rows takes up 10888 KB of disk space:
DROP TABLE IF EXISTS dbo.TEST_HEAP; CREATE TABLE dbo.TEST_HEAP ( ID BIGINT ) WITH (DATA_COMPRESSION = PAGE); INSERT INTO dbo.TEST_HEAP WITH (TABLOCK) SELECT TOP (1000000) NULL FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); EXEC sp_spaceused 'TEST_HEAP';
Therefore, such a table with a trillion rows would require around 10 TB of disk space. That won’t fit on a 1 TB HDD, but the better compression of CCIs gives us some options. Ultimately I decided on building completely full rowgroups of 1048576 rows with each rowgroup only storing a single value. Estimating space for the final table is difficult, but we can hopefully get an upper bound using the following code:
DROP TABLE IF EXISTS dbo.TRIAL_BALLOON; CREATE TABLE dbo.TRIAL_BALLOON ( ID BIGINT, INDEX CCI_TRIAL_BALLOON CLUSTERED COLUMNSTORE ) INSERT INTO dbo.TRIAL_BALLOON WITH (TABLOCK) SELECT TOP (10 * 1048576) NULL FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 OPTION (MAXDOP 1); EXEC sp_spaceused 'TRIAL_BALLOON';
The table has 776 KB reserved space and 104 KB space for data. In the worst case we might expect the final table to require 75 GB space on disk.
Serial Population Strategy
My strategy for populating the table was to run the same code in four different SQL Server sessions. Each session grabs the next ID from a sequence and does a MAXDOP 1 insert of 1048576 rows into the CCI. With only four concurrent sessions I didn’t expect to run into any locking issues such as the mysterious ROWGROUP_FLUSH wait event. The sequence definition is about as simple as it gets:
DROP SEQUENCE IF EXISTS dbo.CCI_Sequence; CREATE SEQUENCE dbo.CCI_Sequence AS BIGINT START WITH 1 INCREMENT BY 1 NO CACHE;
Here’s the code that I used to add rowgroups to the table:
ALTER SERVER CONFIGURATION SET PROCESS AFFINITY CPU=0; DECLARE @i BIGINT SET NOCOUNT ON; IF EXISTS (SELECT 1 FROM ##stop_table) BEGIN SET @i = 9999999999999; END ELSE BEGIN SELECT @i = NEXT VALUE FOR dbo.CCI_Sequence; END; WHILE @i <= 953674 BEGIN WITH NUM (n) AS ( SELECT n FROM ( VALUES (@i),(@i),(@i),(@i),(@i),(@i),(@i),(@i) ,(@i),(@i),(@i),(@i),(@i),(@i),(@i),(@i) ,(@i),(@i),(@i),(@i),(@i),(@i),(@i),(@i) ,(@i),(@i),(@i),(@i),(@i),(@i),(@i),(@i) ) v(n) ) INSERT INTO dbo.BIG_DATA SELECT n1.n FROM NUM n1 CROSS JOIN NUM n2 CROSS JOIN NUM n3 CROSS JOIN NUM n4 OPTION (MAXDOP 1); IF EXISTS (SELECT 1 FROM ##stop_table) BEGIN SET @i = 9999999999999; END ELSE BEGIN SELECT @i = NEXT VALUE FOR dbo.CCI_Sequence; END; END;
The affinity stuff was to get the work spread out evenly over my four schedulers. Each session was assigned to a different CPU from 0-3. It was also important to run the following in a new session after all four sessions started working:
ALTER SERVER CONFIGURATION SET PROCESS AFFINITY CPU=AUTO;
It wasn’t clear to me why that was needed to get good throughput. Perhaps part of the work of building a compressed rowgroup is offloaded to a system process?
The references to the ##stop_table temp table are just a way to pause the work as needed without skipping numbers in the sequence. I think that the code to generate 1048576 rows is fairly optimized. I did try to optimize it since this code was going to be run over 950000 times, but I still suspect that there was a better way to do it that I missed.
The jobs finished after about 2 days of running on 4 CPUs. That’s a rate of around 86 million rows per core per minute which I was pretty happy with. After the sessions finished I needed to do one final, very nervous, insert into the table:
INSERT INTO dbo.BIG_DATA SELECT TOP (331776) 953675 FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1);
Running sp_spaceused has never felt so satisfying:
![]()
Under a GB for one trillion rows. Not bad.
Parallel Population Strategy
Taking advantage of natural parallelism within SQL Server may also be a viable method to populate a trillion row table (especially on an actual server), but I didn’t test it fully. In order to get perfect rowgroups, you need round robin parallelism with a driving table that’s a multiple of the query’s MAXDOP. For example, here’s a suitable plan:

The Constant Scan contains exactly four rows because I’m running MAXDOP 4. The source CCI has exactly 1048576 rows. The parallel insert happens without a repartition streams so we end up with exactly 1048576 rows on each thread and in each compressed rowgroup. Below is one way to generate such a plan:
DROP TABLE IF EXISTS dbo.SOURCE_CCI; CREATE TABLE dbo.SOURCE_CCI ( ID BIGINT, INDEX CCI_SOURCE_CCI CLUSTERED COLUMNSTORE ); INSERT INTO dbo.SOURCE_CCI WITH (TABLOCK) SELECT TOP (1048576) 0 FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); DROP TABLE IF EXISTS dbo.TRIAL_BALLOON; CREATE TABLE dbo.TRIAL_BALLOON ( ID BIGINT, INDEX CCI_TRIAL_BALLOON CLUSTERED COLUMNSTORE ); INSERT INTO dbo.TRIAL_BALLOON WITH (TABLOCK) SELECT driver.n FROM ( SELECT TOP (4) v.n FROM ( VALUES (1),(2),(3),(4) ) v(n) ) driver INNER JOIN dbo.SOURCE_CCI sc ON sc.ID < driver.n OPTION (MAXDOP 4, NO_PERFORMANCE_SPOOL);
With nothing else running on my machine I estimate that this method would take about 2 days to complete. The problem is that if one core is busy with something else, such as watching terrible Youtube videos, then the entire insert could be slowed down.
Updating Stats
To do anything interesting on a table we want statistics. Gathering statistics for extremely compressed data can be challenging in SQL Server. That is because the target sampled rate is based on the total size of the table as opposed to the number of rows in the table. Consider an 8 billion row table built in the same way as the one trillion row table above. SQL Server generates the following query to gather sampled stats against the table:
SELECT StatMan([SC0]) FROM ( SELECT TOP 100 PERCENT [ID] AS [SC0] FROM [dbo].[BIG_DATA] WITH (READUNCOMMITTED) ORDER BY [SC0] ) AS _MS_UPDSTATS_TBL OPTION (MAXDOP 1)
You may notice the lack of TABLESAMPLE as well as the MAXDOP 1 hint. To gather sampled stats SQL Server will get all eight billion rows from the table, sort them, and build the statistics object using the eight billion rows. On my machine, this took almost 3 hours to complete and tempdb grew to 85 GB.
There is a trick to get more reasonable sampled stats. All that’s needed is to increase the table size while keeping the same data. Soft deletion of compressed rowgroups is a good way to accomplish this. First find a data distribution that doesn’t compress well in CCIs. Here’s one example:
SELECT 9999999 + SUM(RN) OVER (ORDER BY RN) FROM ( SELECT TOP (1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) t OPTION (MAXDOP 1);
Each rowgroup has a size of 8392 KB, so adding 100 rowgroups will add 839200 KB to the table. Deleting all of the newly added rows can take a little while and will log quite a bit to the transaction log, but the table size won’t change. Gathering sampled stats after the insert and delete took just a few seconds. The sample size was about 1% of the table. After a REORG the fully deleted rowgroups will be marked as TOMBSTONE and cleaned up by a background process.
For the one trillion row table I decided to roll the dice and go for sampled stats without any tricks. I gave tempdb a maximum size of 280 GB in order to not completely fill my hard drive. The stats update took 3 hours and 44 minutes. Surprisingly, the stat update grew tempdb to its maximum size but it didn’t fail. Perhaps I got very lucky. Here is the hard earned stats object:
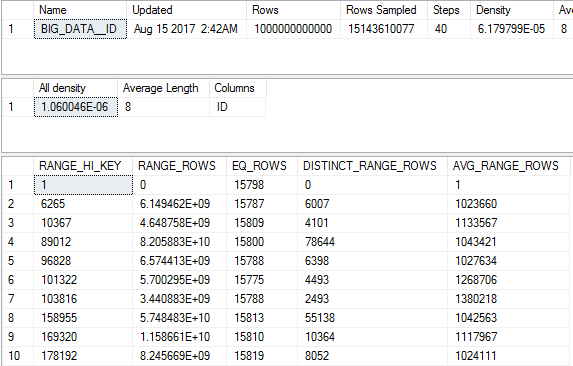
Expected Query Performance
I expected reasonably fast query performance for queries designed to take advantage of rowgroup elimination. After all, the table was built in a way such that every compressed rowgroup only has a single value. I can get a count of rowgroups along with some other metadata in 20 seconds using the DMVs:
SELECT COUNT(*), MIN(css.min_data_id), MAX(css.max_data_id)
FROM sys.objects o
INNER JOIN sys.columns c ON o.object_id = c.object_id
INNER JOIN sys.partitions p ON o.object_id = p.object_id
INNER JOIN sys.column_store_segments css
ON p.hobt_id = css.hobt_id
AND css.column_id = c.column_id
WHERE o.name = 'BIG_DATA'
AND c.name = 'ID';
Getting the relevant segment_ids for a particular filter finishes in under a second:
SELECT segment_id
FROM sys.objects o
INNER JOIN sys.columns c ON o.object_id = c.object_id
INNER JOIN sys.partitions p ON o.object_id = p.object_id
INNER JOIN sys.column_store_segments css
ON p.hobt_id = css.hobt_id
AND css.column_id = c.column_id
WHERE o.name = 'BIG_DATA'
AND c.name = 'ID'
AND 500000 BETWEEN css.min_data_id AND css.max_data_id;
I’m dealing with DMVs so I would expect SQL Server to be able to do rowgroup elimination in a much more efficient way than the above queries. Therefore, 30 seconds seemed like a reasonable upper bound for the following query:
SELECT COUNT(*) FROM dbo.BIG_DATA WHERE ID = 500000;
The query takes over 15 minutes to complete despite reading only a single segment:
Table ‘BIG_DATA’. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 6, lob physical reads 1, lob read-ahead reads 0.
Table ‘BIG_DATA’. Segment reads 1, segment skipped 953674.SQL Server Execution Times:
CPU time = 905328 ms, elapsed time = 917478 ms.
The Evil Wait Event
The query had a max wait time of 915628 ms for QUERY_TASK_ENQUEUE_MUTEX. This is suspiciously close to the elapsed time of 917478 ms. Unfortunately this is a very unpopular wait event in the industry. The wait event library has almost no information about it as well.
I call this the evil wait event because while it’s happening queries cannot be canceled through SSMS and many unrelated queries won’t even run. Most of the time no useful work can be done on the instance. I can’t read Russian so I’m not sure what the wait event is about. After I restarted SQL Server the wait event no longer appeared as consistently, but query performance did not improve as far as I could tell.
Other Queries
I ran a few other tests queries as well, although I was limited in what I could do by the evil wait event. The following query is the only one that I found that wasn’t affected:
SELECT TOP 1 ID FROM dbo.BIG_DATA;
For reasons I don’t understand the query still took a long time:
Table ‘BIG_DATA’. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 6, lob physical reads 1, lob read-ahead reads 0.
Table ‘BIG_DATA’. Segment reads 1, segment skipped 0.SQL Server Execution Times:
CPU time = 791625 ms, elapsed time = 811202 ms.
Counting the rows in the table took almost half an hour:
SELECT COUNT_BIG(*) FROM dbo.BIG_DATA;
Statistics output:
Table ‘BIG_DATA’. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 5722050, lob physical reads 819345, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 3734515 ms, elapsed time = 1635348 ms.
A query to sum every ID in the table took over 40 minutes:
SELECT SUM(ID) FROM dbo.BIG_DATA;
Statistics output:
SQL Server Execution Times:
CPU time = 4810422 ms, elapsed time = 2433689 ms.
As expected performance gets worse without aggregate pushdown. Picking a simple query that’s not supported:
SELECT MAX(ID / 1) FROM dbo.BIG_DATA;
This query took over an hour:
SQL Server Execution Times:
CPU time = 10218343 ms, elapsed time = 3755976 ms.
Queries against some of the CCIs DMVs don’t do very well either. A simple count took almost ten minutes:
SELECT COUNT(*)
FROM sys.dm_db_column_store_row_group_physical_stats
where OBJECT_ID = OBJECT_ID('BIG_DATA');
All of the work appears to be in the COLUMNSTORE_ROW_GROUPS table-valued function but I didn’t dig any more into it.
If you’re interested in how a query performs let me know in the comments. I will try anything that’s somewhat reasonable.
Final Thoughts
Now I can add working with trillion row tables to my resume. The compression for the one trillion row table was very impressive but everything else was decidedly less impressive. The very long QUERY_TASK_ENQUEUE_MUTEX wait times for nearly all queries were especially disappointing. I plan to do more testing at a later date with a partitioned table to see if that helps at all.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.