Adjoining
When writing queries, sometimes you have the pleasure of being able to pass a literal value, parameter, or scalar expression as a predicate.
With a suitable index in place, any one of them can seek appropriately to the row(s) you care about.
But what about when you need to compare the contents of one column to another?
It gets a little bit more complicated.
All About Algorithms
Take this query to start with, joining Users to Posts.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id;
The OwnerUserId column doesn’t have an index on it, but the Id column on Users it the primary key and the clustered index.
But the type of join that’s chosen is Hash, and since there’s no where clause, there’s no predicate to apply to either table for filtering.
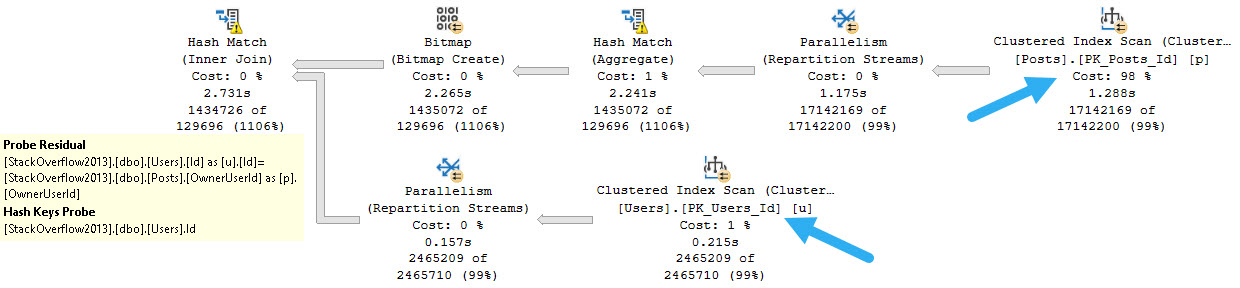
This is complicated slightly by the Bitmap, which is created on the OwnerUserId column from the Posts table and applied to the Id column from the Users table as an early filter.
However, it’s a useless Bitmap, and Bitmaps don’t really seek anyway.
The same pattern can generally be observed with Merge Joins. Where things are a bit different is with Nested Loops.
Shoop Da Loop
If we use a query hint, we can see what would happen with a Nested Loops Join.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
OPTION(LOOP JOIN);
The plan looks like this now, with a Seek on the Users table.
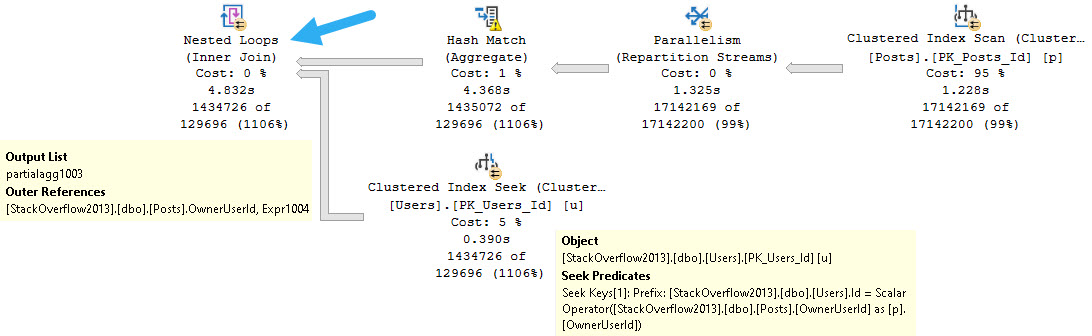
The reason is that this flavor of Nested Loops, known as Apply Nested Loops, takes each row from the outer input and uses it as a scalar operator on the inner input.
An example of Regular Joe Nested Loops™ looks like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation =
(
SELECT
MIN(p.Score)
FROM dbo.Posts AS p
);
Where the predicate is applied at the Nested Loops operator:
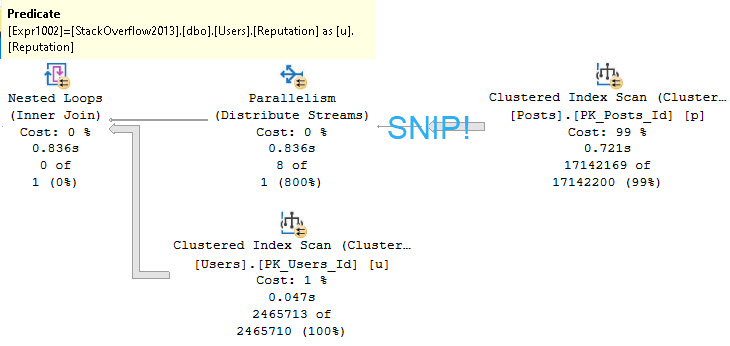
Like most things, indexing is key, but there are limits.
Innermost
Let’s create this index:
CREATE INDEX ud ON dbo.Users(UpVotes, DownVotes);
And run this query:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.UpVotes = u.DownVotes;
The resulting query plan looks like this:
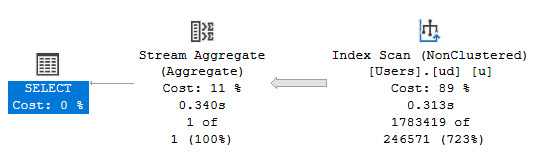
But what other choice is there? If we want a seek, we need a particular thing or things to seek to.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.UpVotes = u.DownVotes
AND u.UpVotes = 1;
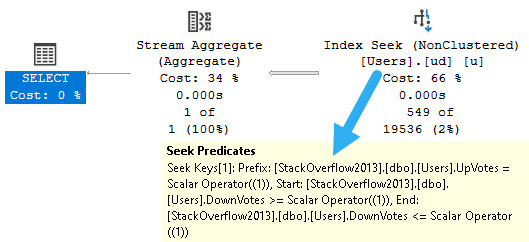
We seek to everyone with an UpVote of 1, and then somewhat awkwardly search the DownVotes column for values >= 1 and <= 1.
But again, these are specific values we can search for.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
That involves more complexity to the query optimizer: in few ms it should be able to help producing a “good estimated” query.
That is because the prior requirement: spend less time as mach as you can, because the client is waiting for results.
Interesting idea… what about a post execution re-optimization occurring when there is less work to do (or a separate process having this job)?