You Fine And All
You can read a lot about how indexes might improve queries.
But there are certain query mechanics that indexes don’t solve for, and you can not only get stuck with an index that isn’t really helping, but all the same query problems you were looking to solve.
Understanding how indexes and queries interact together is a fundamental part of query tuning.
In this post, we’re going to look at some query patterns that indexes don’t do much to fix.
Part Of The Problem
Indexes don’t care about your queries. They care about storing data in order.
There are very definite ways that you can encourage queries to use them efficiently, and probably even more definite ways for you to discourage them from using them efficiently.
Even with syntax that seems completely transparent, you can get into trouble.
Take the simple example of two date columns: there’s nothing in your index that tracks how two dates in a row relate to each other.
Nothing tracks how many years, months, weeks, days, hours, minutes, seconds, milliseconds, or whatever magical new unit Extended Events has to make itself less usable.
Heck, it doesn’t even track if one is greater or less than another.
Soggy Flautas
Ah, heck, let’s stick with Stack Overflow. Let’s even create an index.
CREATE INDEX whatever ON dbo.Posts(CreationDate, ClosedDate);
Now let’s look at these super important queries.
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate < p.ClosedDate;
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate > p.ClosedDate;
How much work will the optimizer think it has to do, here? How many rows will it estimate? How will it treat different queries, well, differently? If you said “it won’t”, you’re a smart cookie. Aside from the “Actual rows”, each plan has the same attributes across.
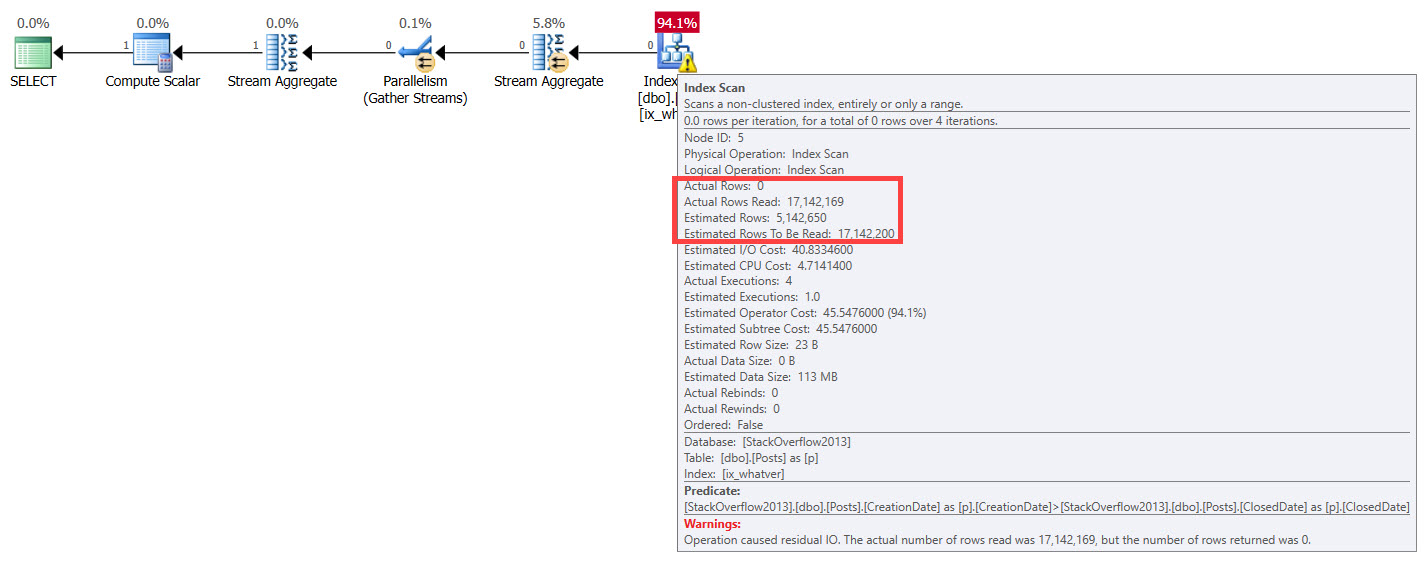
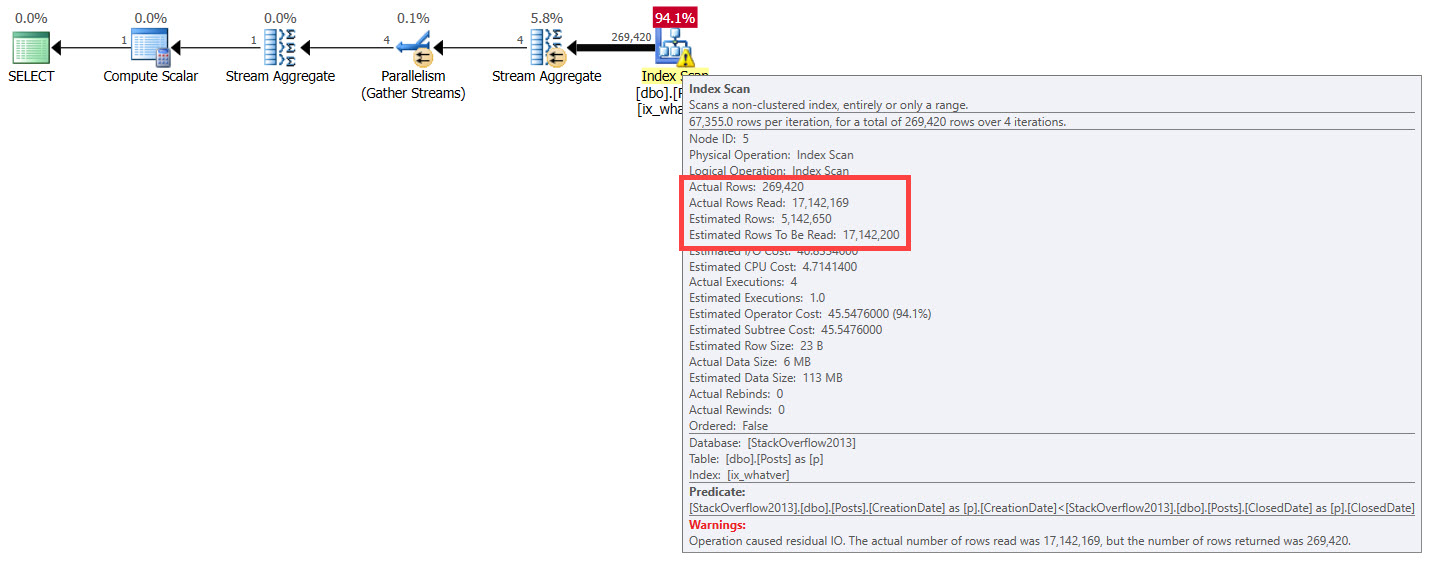
Treachery
Neither of these query plans is terrible on its own.
The problem is really in larger plans, where bad decisions like these have their way with other parts of a query plan.
Nasty little lurkers they are, because you expect things to get better when creating indexes and writing SARGable predicates.
Yet for both queries, SQL Server does the same thing, based on the same guesses on the perceived number of rows at play. It’s one of those quirky things — if it’s a data point we care about, then it’s one we should express somehow.
A computed column might work here:
ALTER TABLE dbo.Posts
ADD created_less_closed AS
CONVERT(BIT, CASE WHEN CreationDate < ClosedDate
THEN 1
WHEN CreationDate > ClosedDate
THEN 0
END)
CREATE INDEX apathy
ON dbo.Posts (created_less_closed);
Which means we’d have to change our queries a bit, since expression matching has a hard time reasoning this one out:
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE 1 = CONVERT(BIT, CASE WHEN CreationDate < ClosedDate
THEN 1
WHEN CreationDate > ClosedDate
THEN 0
END)
AND 1 = (SELECT 1);
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE 0 = CONVERT(BIT, CASE WHEN CreationDate < ClosedDate
THEN 1
WHEN CreationDate > ClosedDate
THEN 0
END)
AND 1 = (SELECT 1);
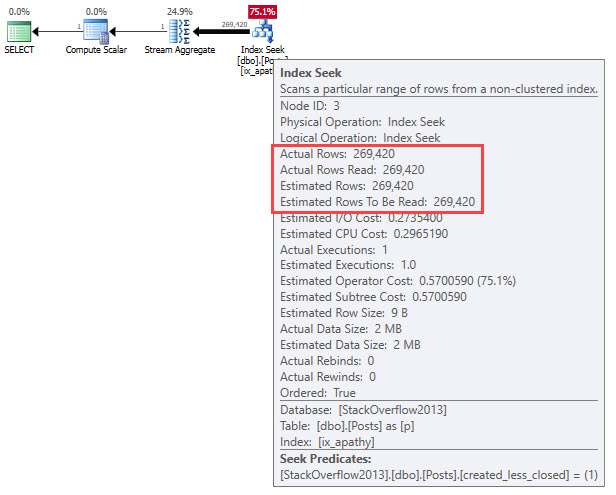
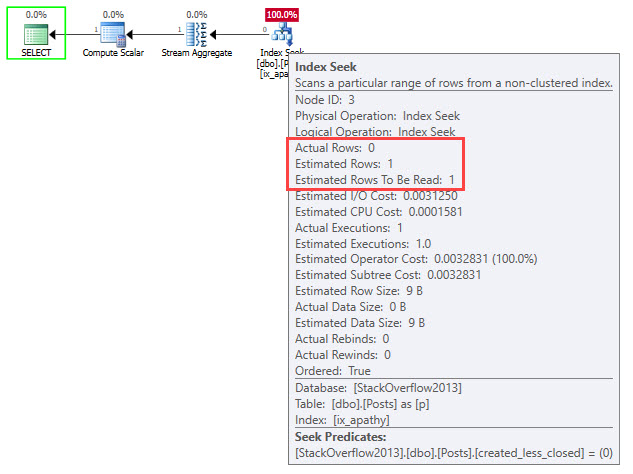
What Would Be Better?
Practically speaking, it isn’t the job of an index (or statistic) to track things like this. We need to have data that represents things that are important to users.
Though neither of these plans is terrible in isolation, bad guesses like these flow all through query plans and can lead to other bad decisions and oddities.
It’s one of those terrible lurkers just waiting to turn an otherwise good query into that thing you regard with absolute loathing every time it shows up in [your favorite monitoring tool].
Knowing this, we can start to design our data to better reflect data points we care about. A likely hero here is a computed column to return some value based on which is greater, or a DATEDIFF of the two columns.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Interesting post, Erik. When I was reading it, I also thought of using a computed column with an index. I then wondered if an appropriate check constraint would do something similar:
CONSTRAINT CK_the_dates CHECK (CreationDate ClosedDate. Unfortunately, I couldn’t come up with a way to make the check constraint “short circuit” the query execution and bypass the table/index scan.
Yeah, you could put some more logic in a udf, but then you’ll make everything horrible by putting a udf in your table.
Great post Erik!
Am I correct that you’re using the ” AND 1 = (SELECT 1);” for forcing a FULL optimization level? I remember to a post writen by you but can’t find it…
Hi Lori!
Yep, exactly right. I’ve mentioned it in passing in a bunch of posts, but never written specifically about it.
Thanks!
There was a nice section on it included in this post from Erik back in 2017: https://www.brentozar.com/archive/2017/06/query-plans-trivial-optimization-vs-simple-parameterization/