Nein Nein Nein
Just like you can’t fix a broken bone with good vibes, you can’t fix parameter sniffing with idiocy. More on that later, though.
Like many other things we’ve discussed thus far, local variables are a convenience to you that have behavior many people are still shocked by.
You, my dear and constant reader, may not be shocked, but the nice people who pay me money to fix things seem quite astounded by what happens when you invoke local variables.
So I find myself in a difficult position: do I dredge up more red meat for the millions of die-hard SQL Server performance nuts who come here for the strange and outlandish, or produce evergreen content for people who pay my substantial bar tabs.
Coin, tossed.
Corn, popped.
Greenery
Local variables present an attractive proposition for many reasons. For instance, you can:
- Set a constant date/time variable
- Assign values from complex subqueries to a single variable
- Increment values in a loop to batch modifications
And here’s the thing: I’m with you on the need and convenience for all those things. It’s just how you usually end up using them that I disagree with.
Many developers are under the impression that parameter sniffing is a bad thing; it is not. If it were, modern database systems would have thrown the whole idea out ages ago.
Constantly generating execution plans is not a good use of your CPU’s brain power. The real problem is parameter sensitivity.
I’m going to say this as emphatically as I can for those of you who call local variables and using optimize for unknown as a best practice:
Local variables use an estimate derived from the total rows in the table multiplied by the assumed uniqueness of a column’s data. More often than not, that is a very small number.
If you have the kind of incredibly skewed data that is sensitive to parameters being sniffed, and plans being generated based on those initial estimates, it is highly unlikely that plans derived from fuzzy math will be suitable for general execution.
There may be exceptions to this, of course.
Every database is subject to many local factors that make arrangements outside the norm being sensible.
Drudgery
What you need to do as a developer is test these assumptions of yours. I spend a lot of my time fixing performance problems arising developers not testing assumptions.
A common feedback loop occurs when testing code against very small data sets that don’t expose the types of performance problems that arise from larger ones, or testing against data sets that may be similar in terms of volume, but not in terms of distribution.
I am being charitable here, though. Most code is only tested for result correctness. That’s a fine starting point.
After all, most developers are paid to develop, and are not performance tuning experts. It would be nice if performance tuning were part of the development process, but… If you’re testing against wack data, it’s impossible.
Timelines are short, demands are substantial, and expectations are based mostly around time to deliver.
Software development against databases is rarely done by developers who are knowledgable about databases, and more often than not by developers who are fluent in the stack used for the application.
Everything that happens between front and back may as well be taking place in Narnia or Oz or On A Planet Far, Far Away.
This section ended up being way more philosophical than I had intended, but it’s Côte-Rôtie season.
Let’s move on!
Assumptive
When you want to test whether or not something you’re working on performs best, you need to understand which options are available to you.
There are many ways to pet a dog when working with SQL Server. Never assume the way you’re doing it is the best and always the best.
One assumption you should absolutely never make is that the way you see everyone around you doing something is the best way to do something.
That’s how NOLOCK turned into an epidemic. And table variables. And Common Table Expressions. And Scalar UDFs. And Multi-Statement UDFs. And sticking ISNULL in every join and where clause.
And, of course, local variables.
One way to test your assumptions about things is to create a temporary stored procedure and test things in different ways.
CREATE OR ALTER PROCEDURE
#p
(
@ParentId integer
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@ParentIdInner integer = @ParentId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE ParentId = 0;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE ParentId = @ParentId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE ParentId = @ParentIdInner;
END;
GO
CREATE INDEX
p ON
dbo.Posts
(ParentId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
EXEC dbo.#p
@ParentId = 0;
We’re using:
- A literal value
- An actual parameter
- A declared variable
With an example this simple, the local variable won’t:
- Slow things down
- Change the query plan
- Prevent a seek
But it will throw cardinality estimation in the toilet and flush twice.
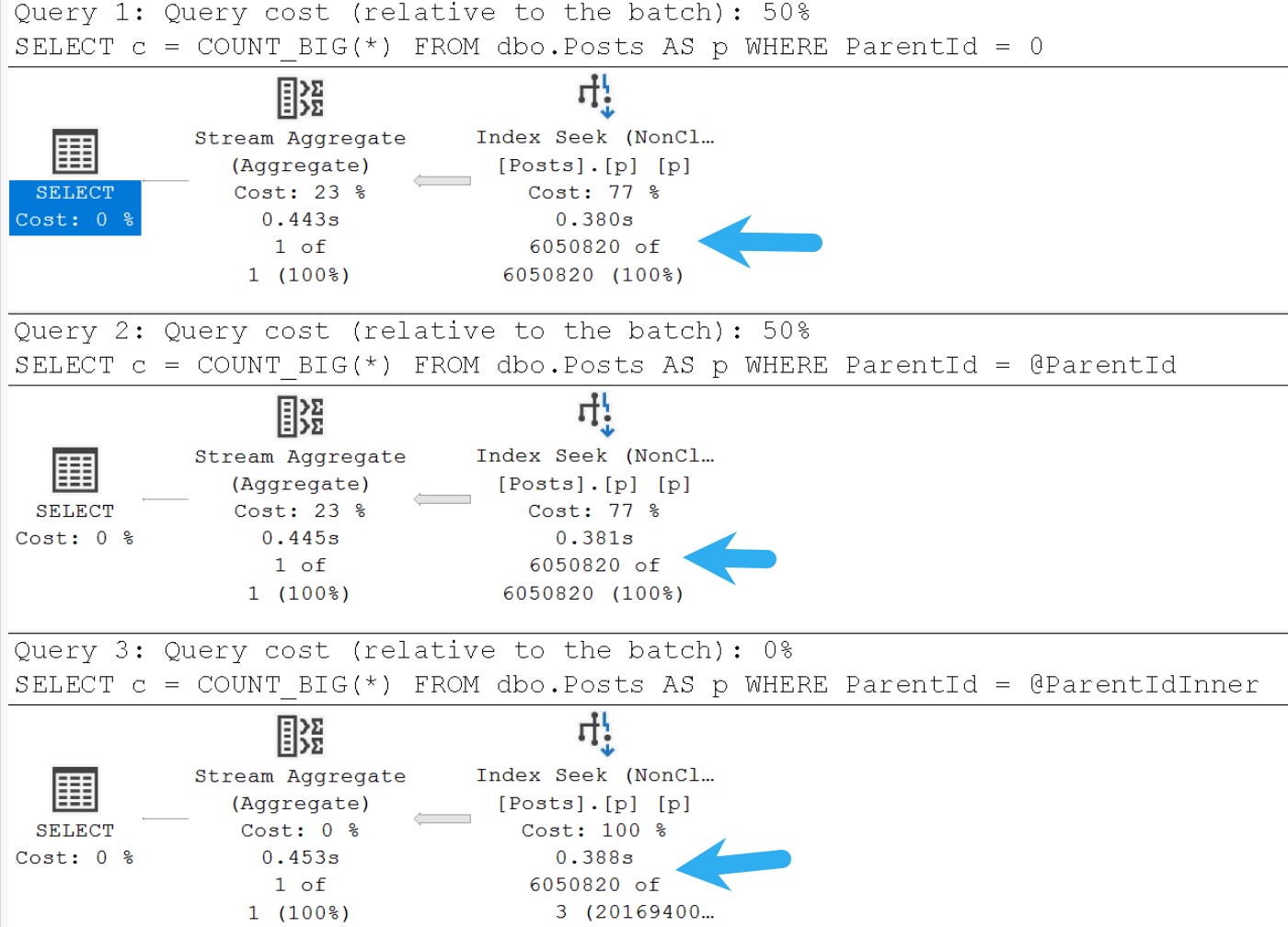
These are the kinds of things you need to test and look at when you’re figuring out the best way to pet SQL Server and call it a very good dog.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
One thought on “The Art Of The SQL Server Stored Procedure: Local Variables”
Comments are closed.