I didn’t have a chance to write this post yesterday, because I was in the midst of closing the ticket.
Here’s a short synopsis from the client emergency:
Third party vendor
Merge statement compiled in a DLL file
Called frequently
Uses a Table-Valued Parameter
Merges into one small table…
Which has an indexed foreign key to a huge table
Constantly deadlocking with other calls to the same merge query
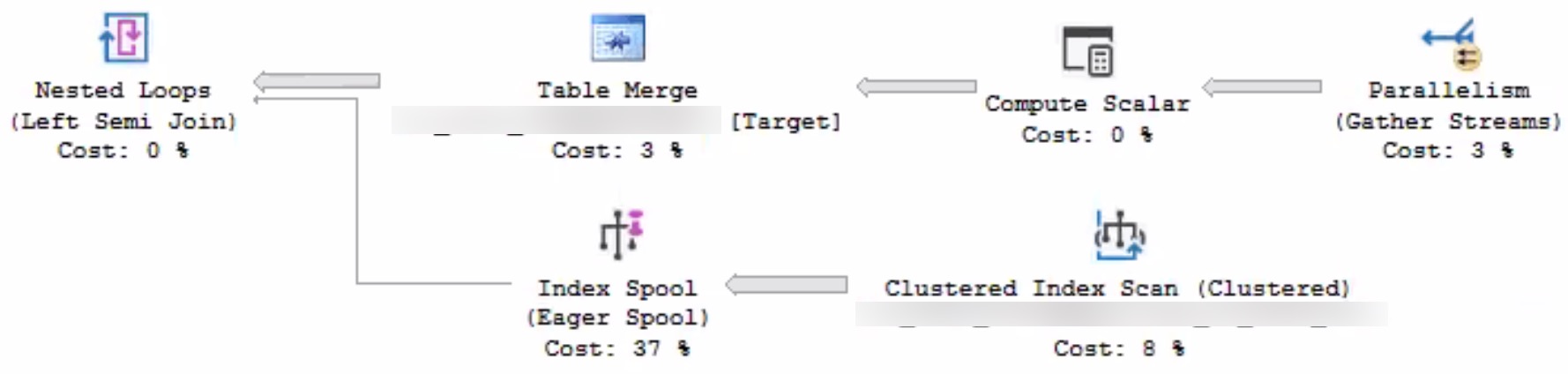
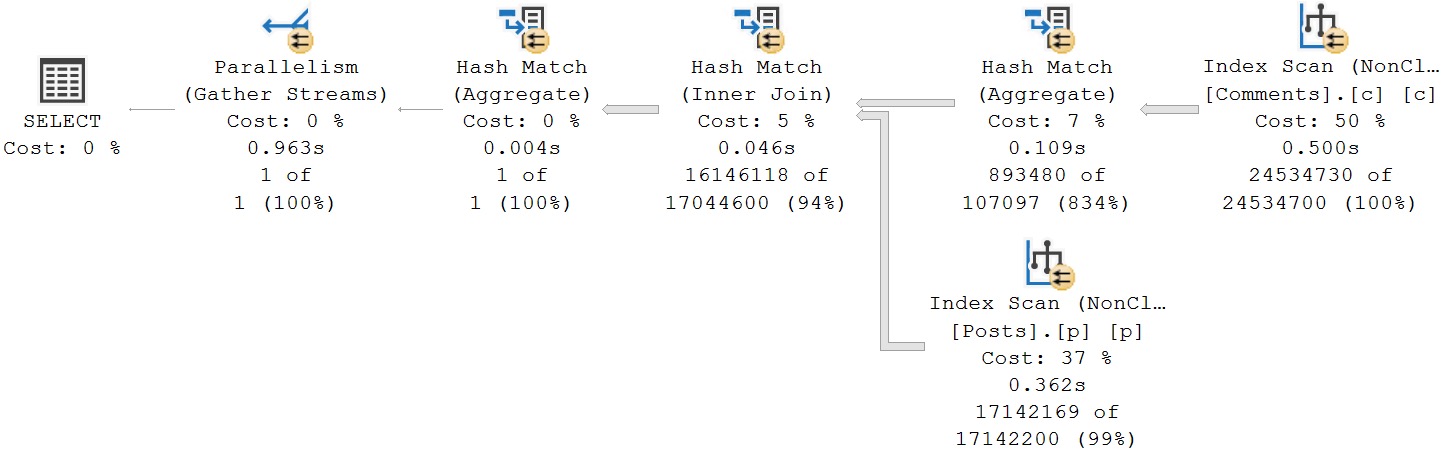
To evaluate the foreign key, SQL Server was choosing this execution plan:
suck
I hate the optimizer, some days. I really do.
Whatever year it’s stuck in is an unfortunate one.
Eager Index Spools Suck
Why in the name of Babe the blue-balled Ox would SQL Server’s advanced, intelligent, hyper-awesome, $7k a core query optimizer choose to build an index spool here, on 7 million rows?
Here are some things we tried to get rid of it:
Add a clustered index to the target table
Add a single-column index on the already-indexed clustered index key
Add primary keys to the Table Types
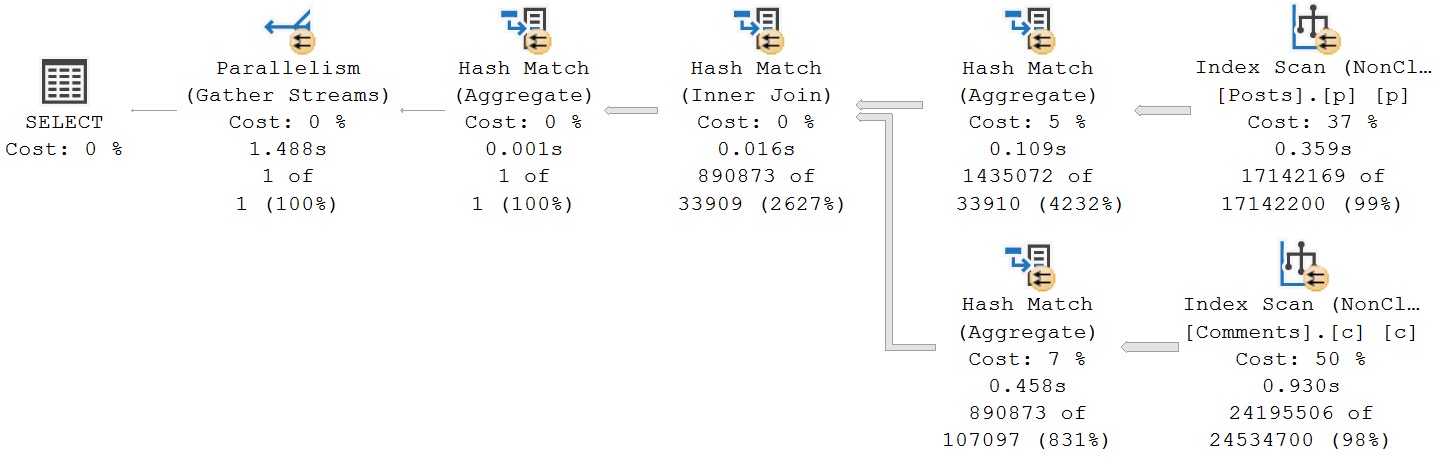
If I had access to the merge statement, I would have torn it to shreds separate insert, update, and delete statements.
But would that have helped with SQL Server’s dumb execution plan choice in evaluating the foreign key? Would a FORCESEEK hint even be followed into this portion of the execution plan?
RCSI wouldn’t help here, because foreign key evaluation is done under Read Committed Locking isolation.
I don’t know. We can’t just recompile DLLs. All I know is that building the eager index spool is slowing this query down just enough to cause it to deadlock.
So, I took a page out of the Ugly Pragmatism handbook. I disabled the foreign key, and set up a job to look for rogue rows periodically.
Under non-Merge circumstances, I may have written a trigger to replace the foreign key. In that very moment, I had some doubts about writing a trigger quickly that would have worked correctly with:
All of Merge’s weirdness
Under concurrency
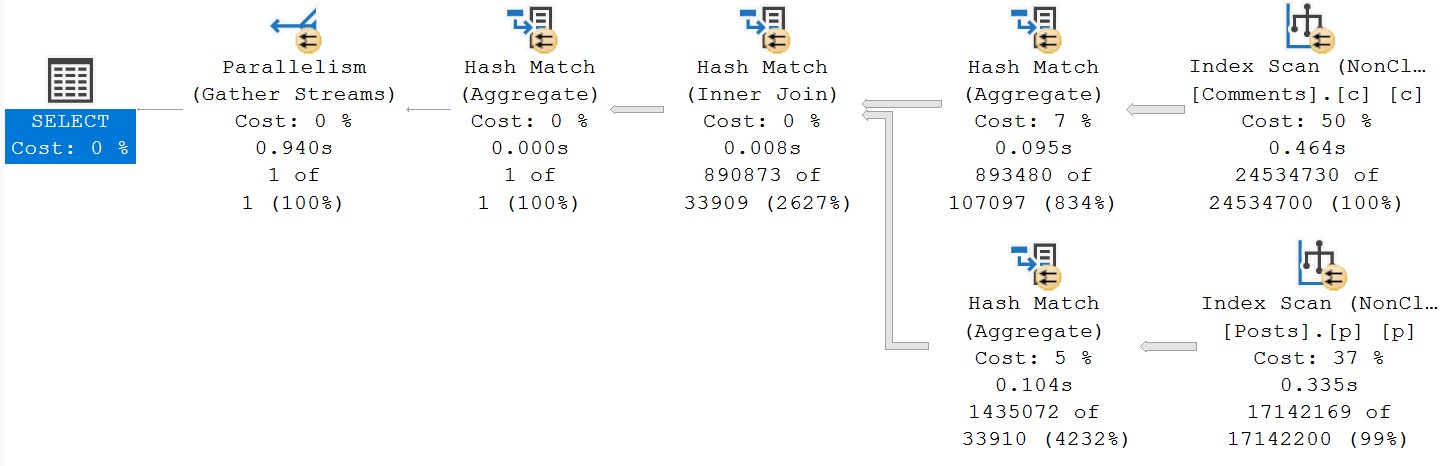
In reality, the foreign key wasn’t contributing much. The application only ever allows users to put rows in the parent table, and additional information only gets added to the child table by a system process after the original “document” is processed.
So, goodbye foreign key, goodbye eager index spool, goodbye deadlocks.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Of all the cardinality estimation processes that SQL Server has to do, the two that I sympathize the most with are joins and aggregations.
It would be nice if the presence of a foreign key did absolutely anything at all whatsoever to improve join estimation, but that’s just another example of a partial birth feature in SQL Server.
The compatibility level thing can be a real deal-breaker for a lot of people, though I think a safer path forward is to use the legacy cardinality estimator in conjunction with higher compatibility levels, like so:
ALTER DATABASE SCOPED CONFIGURATION
SET LEGACY_CARDINALITY_ESTIMATION = ON;
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 160;
At any rate, Cardinality Estimation feedback, at least in its initial implementation, does not work do anything for aggregations.
Team Spirit
One thing I’m always grateful for is the circle of smart folks I can share my demos, problems, ideas, and material with for sanity checking.
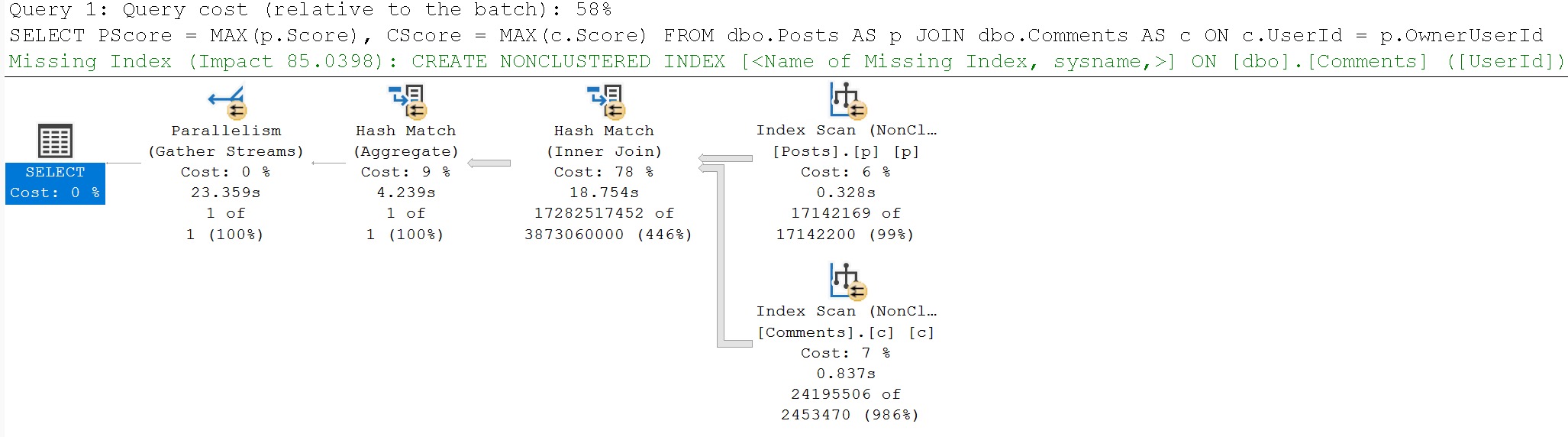
While I was talking about the HT waits, this demo query came up, where SQL Server just makes the dumbest possible choice, via Paul White (b|t):
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON c.UserId = p.OwnerUserId;
GO
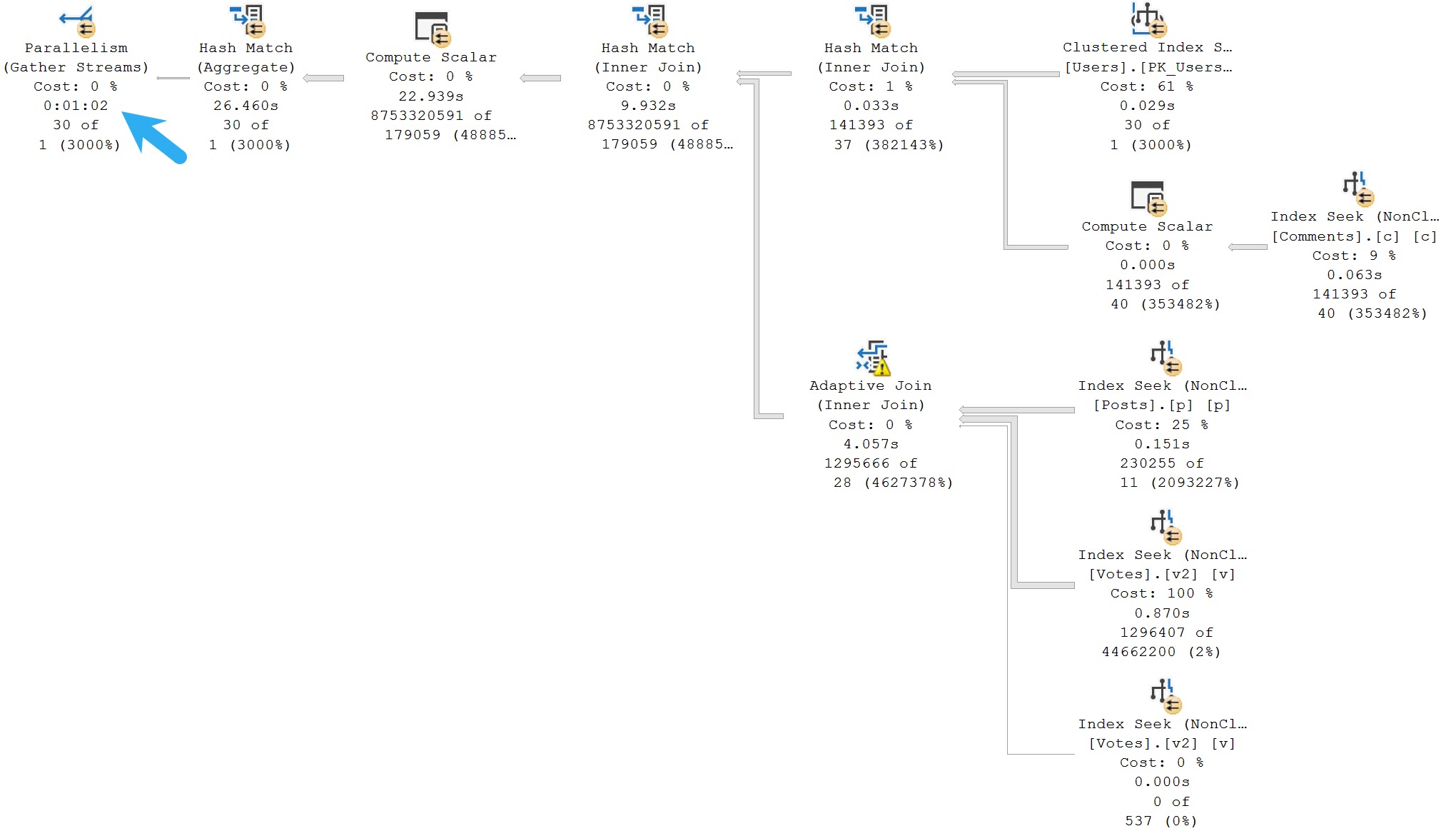
Here’s the query plan, which yes, you’re reading correctly, runs for ~23 seconds, fully joining both tables prior to doing the final aggregation.
poor choice, that
I’m showing you a little extra here, because there are missing index requests that the optimizer asks for, but we’ll talk about those in tomorrow’s post.
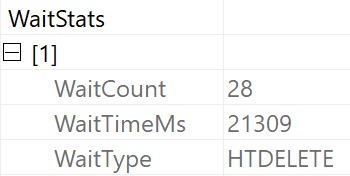
The wait stats for this query, since it’s running in Batch Mode, are predictably HT-related.
ouch dude
It’s not that the optimizer isn’t capable of doing early aggregations — in many cases it will do so quite eagerly — it just… Doesn’t here.
Rewrite #1: Manually Aggregate Posts
Part of what I get paid to do is spot this stuff, and figure out how to make queries better.
If I saw this one, I’d probably start by trying something like this:
WITH
p AS
(
SELECT
UserId = p.OwnerUserId,
Score = MAX(p.Score)
FROM dbo.Posts AS p
GROUP BY
p.OwnerUserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM p
JOIN dbo.Comments AS c
ON c.UserId = p.UserId;
GO
Which would be a pretty good improvement straight out of the gate.
worth the money
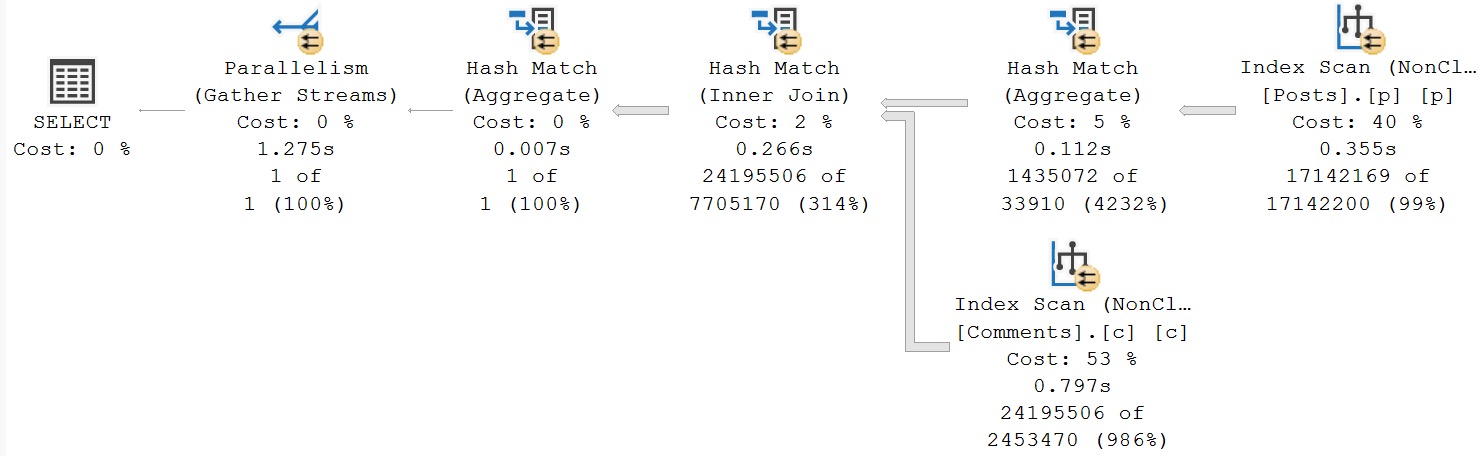
From 23 seconds to 1.2 seconds right off the bat. Pretty good. Note the join placement though, with Posts on the outer, and Comments on the inner side of the join.
Rewrite #2: Manually Aggregate Comments
What if we thought this was maybe a bad situation, and we wanted to try get a different query plan? What if we really didn’t enjoy the 986% overestimate?
WITH
c AS
(
SELECT
UserId = c.UserId,
Score = MAX(c.Score)
FROM dbo.Comments AS c
GROUP BY
c.UserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM dbo.Posts AS p
JOIN c
ON c.UserId = p.OwnerUserId;
GO
We could write the query like above, and see if SQL Server does any better. Right? Right.
christmas bonus
Now we’re down under a second. Comments is on the outer, and Posts is on the inner side of the join, and estimates across the board are just about spot-on.
I know what you’re thinking: We should aggregate BOTH first. When we leave it up to SQL Server’s optimizer, it’s still not getting the early aggregation message.
Rewrite #3: Manually Aggregate Both
You might be thinking “I bet if we aggregate both, it’ll take 500 milliseconds”. You’d be thinking wrong. Sorry.
WITH
p AS
(
SELECT
UserId = p.OwnerUserId,
Score = MAX(p.Score)
FROM dbo.Posts AS p
GROUP BY
p.OwnerUserId
),
c AS
(
SELECT
UserId = c.UserId,
Score = MAX(c.Score)
FROM dbo.Comments AS c
GROUP BY
c.UserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM p
JOIN c
ON c.UserId = p.UserId;
This is great. Aren’t common table expressions just great? Yay. yay. y?
oh you big dummy
We made things nearly 500 milliseconds worse. I want to take this opportunity to share something annoying with you: it doesn’t matter which order we write our common table expressions in, or which order we join them in when we select data out of it, SQL Server’s optimizer chooses the exact same plan as this one. There’s no point in showing you the other query plans, because they look identical to this one: Posts is on the outer, and Comments is on the inner, side of the join.
Cardinality estimates improve somewhat but not in a meaningful way. We just know we’re gonna have to aggregate both sets before doing the join, so we get table cardinality right, but cardinality estimation for the aggregates are both pretty bad, and the join is screwed.
Rewrite #4: Manually Aggregate Both, Force Join Order
This must be the magic that finally improves things substantially. Right? Wrong.
WITH
p AS
(
SELECT
UserId = p.OwnerUserId,
Score = MAX(p.Score)
FROM dbo.Posts AS p
GROUP BY
p.OwnerUserId
),
c AS
(
SELECT
UserId = c.UserId,
Score = MAX(c.Score)
FROM dbo.Comments AS c
GROUP BY
c.UserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM c
JOIN p
ON c.UserId = p.UserId
OPTION(FORCE ORDER);
GO
Doing this will suplex the optimizer into putting Comments on the outer, and Posts on the inner side of the join.
anybody else
This, unfortunately, only gets us in about as good a situation as when we only did a manual aggregate of the Comments table. Given the current set of indexes, the only thing I could find that gave meaningful improvement was to run at DOP 16 rather than DOP 8.
The current set of indexes look like this:
CREATE INDEX
c
ON dbo.Comments
(Score)
INCLUDE
(UserId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
p
ON dbo.Posts
(Score, OwnerUserId)
INCLUDE
(PostTypeId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
And remember I said at the beginning: SQL Server’s optimizer is insistent that better indexes would make things better.
In tomorrow’s post, we’ll look at how that goes.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I have a couple posts scheduled next week about aggregates, so now is a good time to continue my series on how you, my dear, sweet, developers, can use indexes in various ways to fix performance issues.
In this one, we’re going to get into a weird cross-section, because I run into a lot of developers who think that modularizing abstracting queries away in various things is somehow better for performance.
It’ll happen with functions a lot where I’ll hear that, but by far, it is more common to hear this about views.
Everything from results getting cached or materialized to metadata lookups being faster has been thrown at me in their defense.
By far the strangest was someone telling me that SQL Server creates views automatically for frequently used queries.
They are borderline unusable. Seriously, read through the list of “things you can’t do” I linked to up there, and note the utter scarcity of “possible workarounds”.
How a $200 billion dollar a year company has an indexed view feature that doesn’t support MIN, MAX, AVG, subqueries (including EXISTS and NOT EXISTS), windowing functions, UNION, UNION ALL, EXCEPT, INTERSECT, or HAVING in the year 2024 is beyond me, and things like this are why many newer databases will continue to eat SQL Server’s lunch, and many existing databases (Oracle, Postgres) which have much richer features available for indexed (materialized) views point and laugh at us.
Anyway, here’s the query.
SELECT
u.Id,
u.DisplayName,
QuestionUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
QuestionDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
AnswerAcceptedScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 1 THEN 1 ELSE 0 END)),
AnswerUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
AnswerDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
CommentScore =
SUM(CONVERT(bigint, c.Score))
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
JOIN dbo.Votes AS v
ON v.PostId = p.Id
WHERE u.Reputation > 500000
AND p.Score > 0
AND c.Score > 0
AND p.PostTypeId IN (1, 2)
AND v.VoteTypeId IN (1, 2, 3)
GROUP BY
u.Id,
u.DisplayName;
It just barely qualifies for indexed view-ness, but only if I add a COUNT_BIG(*) to the select list.
Now, here’s the thing, currently. We gotta look at a query plan first. Because it’s going to drive a lot of what I tell you later in the post.
A Query Plan!
Right now when I execute this query, I get a nice, happy, Batch Mode on Row Store query plan.
It’s not the fastest, which is why I still want to create an indexed view. But stick with me. It runs for about a minute:
ONE MORE MINUTE
What’s particularly interesting is a Batch Mode Compute Scalar operator running for 22 seconds on its own. Fascinating.
Okay, but the important thing here: It takes one minute to run this query.
In Batch Mode.
An Indexed View Definition!
Let’s take a stab at creating an indexed view out of this thing, named after the Republica song that was playing at the time.
CREATE OR ALTER VIEW
dbo.ReadyToGo
WITH SCHEMABINDING
AS
SELECT
u.Id,
u.DisplayName,
QuestionUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
QuestionDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
AnswerAcceptedScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 1 THEN 1 ELSE 0 END)),
AnswerUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
AnswerDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
CommentScore =
SUM(CONVERT(bigint, c.Score)),
WellOkayThen =
COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
JOIN dbo.Votes AS v
ON v.PostId = p.Id
WHERE u.Reputation > 500000
AND p.Score > 0
AND c.Score > 0
AND p.PostTypeId IN (1, 2)
AND v.VoteTypeId IN (1, 2, 3)
GROUP BY
u.Id,
u.DisplayName;
GO
CREATE UNIQUE CLUSTERED INDEX
RTG
ON dbo.ReadyToGo
(Id)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
This will create successfully but…
An Indexed View Creation Query Plan!
Indexed views can’t be created using Batch Mode. They must be created in Row Mode.
This one takes two hours, almost.
EXCUSE ME WHAT
Yes, please do spend an hour and twenty minutes in a a Nested Loops Join. That’s just what I wanted.
Didn’t have anything else to do with my day.
Of course, with that in place, the query finishes instantly, so that’s nice.
Perils!
So yeah, probably not great that creating the indexed view takes that long. Imagine what that will do to any queries that modify the base data in these tables.
Hellish. And all that to produce a 30 row indexed view. Boy to the Howdy.
This is a bit of a cautionary tale about creating indexed views that span multiple tables. It is probably not the greatest idea, because maintaining them becomes difficult as data is inserted, updated, or deleted. I’m leaving the M(erge) word out of this, because screw that thing anyway.
If we, and by we I mean me, wanted to be smarter about this, we would have taken a better look at the query and taken stock of a couple things and considered some different options.
Maybe the Comments aggregation should be in its own indexed view
Maybe the Posts aggregation should be in its own indexed view (optionally joined to Votes)
Maybe the Comments and Posts aggregations being done in a single indexed view would have been good enough
Of course, doing any of those things differently would change our query a bit. Right now, we’re using PostTypeId to identify questions and answers, but it’s not in the select list otherwise. We’d need to add that, and group by it, too, and we still need to join to Votes to get the VoteTypeId, so we know if something was an upvote, downvote, or answer acceptance.
We could also just live with a query taking a minute to run. If you’re going to sally forth with indexed views, consider what you’re asking them to do, and what you’re asking SQL Server to maintain when you add them across more than one table.
They can be quite powerful tools, but they’re incredibly limited, and creating them is not always fast or straightforward.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
For many SQL Server developers, using statement-level OPTION(RECOMPILE) hints is the path of least resistance for tuning parameter sensitive queries.
And I’m okay with that, for the most part. Figuring out what parameters a stored procedure compiled with, and was later executed with is a hard task for someone busy trying to bring new features to a product.
But let’s say one day you have performance issues regardless of all the recompiling in the world. No matter what set of parameters get passed in, your procedure is just sleepy-dog slow.
Things get so bad that you hire a young, handsome consultant with reasonable rates like myself to help you figure out why.
The plan cache will be pretty useless for troubleshooting the recompile-hinted queries, but we can still use Query Store.
Example
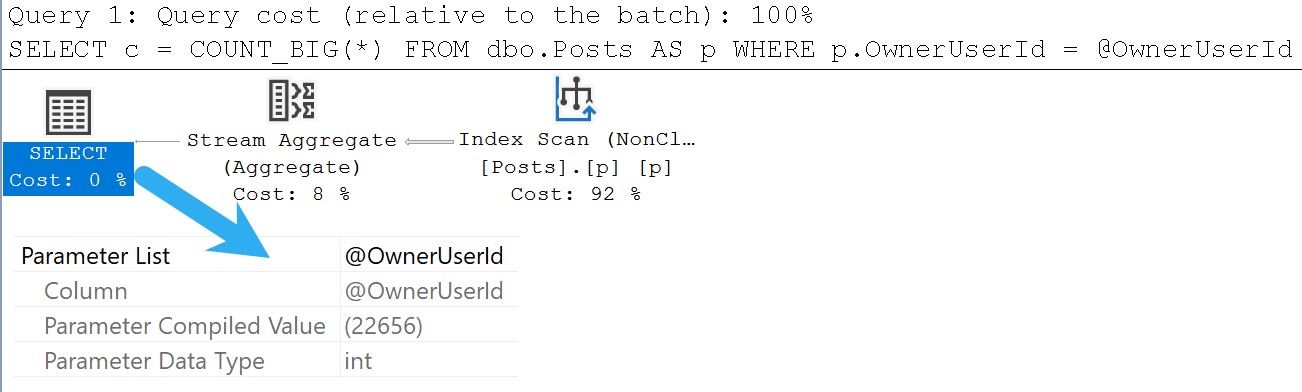
Here’s a simple test procedure to show what I mean, named after a random set of cursor options.
CREATE OR ALTER PROCEDURE
dbo.LocalDynamic
(
@OwnerUserId integer
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @OwnerUserId;
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @OwnerUserId
OPTION(RECOMPILE);
END;
GO
EXEC dbo.LocalDynamic
@OwnerUserId = 22656;
EXEC sp_QuickieStore
@procedure_name = 'LocalDynamic';
The end result in Query Store (as observed with the lovely and talented sp_QuickieStore) will show two execution plans.
The query without the recompile hint will show a compiled parameter value of 22656
The query with the recompile hint will show the literal values used by parameters as predicates
Here’s what I mean. This query has a Parameter List attribute.
cool, cool
This query won’t have the Parameter List attribute, but that’s okay. We can see what got used as a literal value.
don’t despair
Plumbing
This all comes down to the way statement-level recompile hints work. They tell the optimizer to compile a plan based on the literal values that get passed in, that doesn’t have to consider safety issues for other parameter values.
Consider the case of a filtered index to capture only “active” or “not deleted” rows in a table.
Using a parameter or variable to search for those won’t use your filtered index (without a recompile hint), because a plan would have to be cached that safe for searching for 1, 0, or NULL.
If you’re troubleshooting performance problems using Query Store, and you’re dealing with queries with statement-level recompile hints, you just need to look somewhere else for the parameter values.
What this can make tough, though, if you want to re-execute the stored procedure, is if you have multiple queries that use incomplete sets of required parameters. You’ll have to track down other query plans.
But quite often, if there’s one problem query in your procedure, the parameter values it requires will be enough to go on.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
A Follow Up On HT Waits, Row Mode, Batch Mode, and SQL Server Error 666
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Performance Tuning Batch Mode HTDELETE and HTBUILD Waits In SQL Server
Thanks for watching!
Here’s the demo query, in case you’re interested in following along.
SELECT
u.Id,
u.DisplayName,
u.Reputation,
TopQuestionScore =
MAX(CASE WHEN p.PostTypeId = 1 THEN p.Score ELSE 0 END),
TopAnswerScore =
MAX(CASE WHEN p.PostTypeId = 2 THEN p.Score ELSE 0 END),
TopCommentScore =
MAX(c.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
JOIN dbo.Comments AS c
ON u.Id = c.UserId
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
AND v.VoteTypeId IN (1, 2, 3)
)
AND u.Reputation > 10000
AND p.Score > 0
AND c.Score > 0
GROUP BY
u.Id,
u.DisplayName,
u.Reputation
ORDER BY
TopAnswerScore DESC
OPTION
(
RECOMPILE,
USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'),
USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140')
);
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
When you’ve been working with the same technology for long enough, especially if you’ve found your niche, you’re bound to find yourself having to solve the same problems over and over again with it.
Even if you move to a new job, they probably hired you because of your track record with, and skillset in, whatever you were doing before.
One thing I do for clients is review resumes and interview applicants for developer/DBA roles. There are some laughable ones out there, where someone claims to be an expert in every technology they’ve ever touched, and there are some ridiculous ones out there that are obviously copy/paste jobs. I even came across one resume where the job description and qualifications were posted under experience.
As a performance tuning consultant, even I end up fixing a lot of the same issues day to day. There are, of course, weird and cool problems I get to solve, but most folks struggle with the grasping the fundamentals so bad that I have to ~do the needful~ and take care of really basic stuff.
There’s something comforting in that, because I know someone out there will always need my help, and I love seeing a client happy with my work, even if it wasn’t the most challenging work I’ve ever done.
Anyway, to celebrate the times where we’ve gotten to come out of our groundhog holes (I’m sure they have a real name, but I’m not a groundhogologist), leave a comment below with a cool problem you’ve gotten to solve recently.
In the case of a tie, there will be a drinking contest to determine the winner.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
bit Obscene Episode 1: What Developers Need To Know About Transactions
In the inaugural episode, Joe Obbish and Erik Darling talk about how developers use and abuse transactions, and some surprises you might run into for them.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
 Foreign Keys Suck
Foreign Keys Suck