With Sympathy
Of all the cardinality estimation processes that SQL Server has to do, the two that I sympathize the most with are joins and aggregations.
It would be nice if the presence of a foreign key did absolutely anything at all whatsoever to improve join estimation, but that’s just another example of a partial birth feature in SQL Server.
While SQL Server 2022 does have Cardinality Estimation Feedback available, you need to:
- Use compatibility level 160
- Enable the database scoped configuration
- Have Query Store enabled to persist the hint
The compatibility level thing can be a real deal-breaker for a lot of people, though I think a safer path forward is to use the legacy cardinality estimator in conjunction with higher compatibility levels, like so:
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = ON; ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 160;
At any rate, Cardinality Estimation feedback, at least in its initial implementation, does not work do anything for aggregations.
Team Spirit
One thing I’m always grateful for is the circle of smart folks I can share my demos, problems, ideas, and material with for sanity checking.
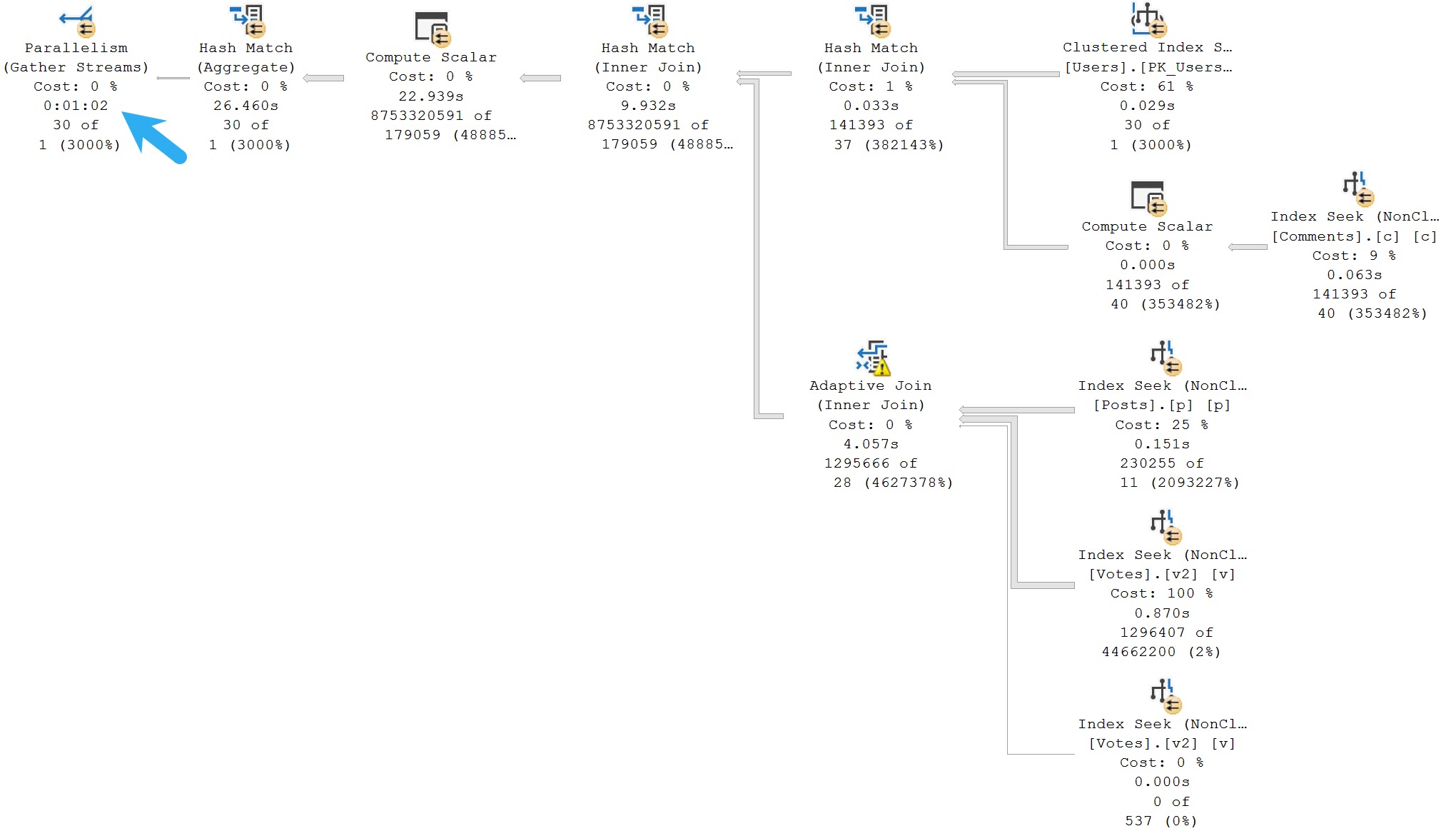
While I was talking about the HT waits, this demo query came up, where SQL Server just makes the dumbest possible choice, via Paul White (b|t):
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON c.UserId = p.OwnerUserId;
GO
Here’s the query plan, which yes, you’re reading correctly, runs for ~23 seconds, fully joining both tables prior to doing the final aggregation.
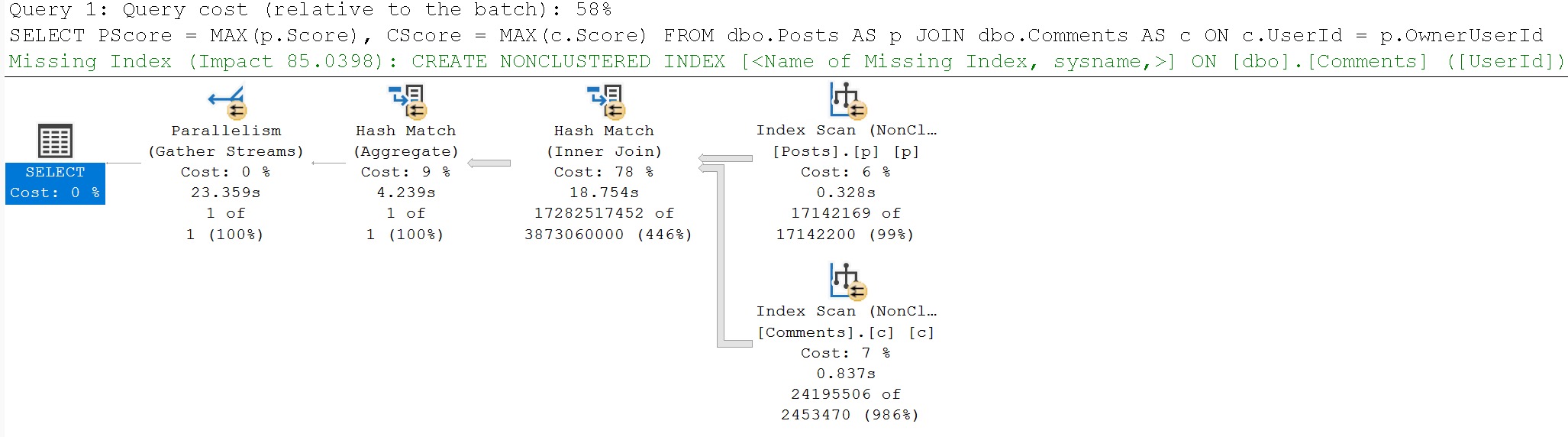
I’m showing you a little extra here, because there are missing index requests that the optimizer asks for, but we’ll talk about those in tomorrow’s post.
The wait stats for this query, since it’s running in Batch Mode, are predictably HT-related.
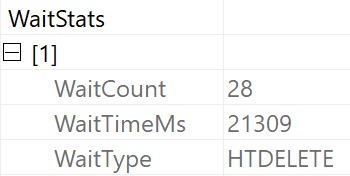
It’s not that the optimizer isn’t capable of doing early aggregations — in many cases it will do so quite eagerly — it just… Doesn’t here.
Rewrite #1: Manually Aggregate Posts
Part of what I get paid to do is spot this stuff, and figure out how to make queries better.
If I saw this one, I’d probably start by trying something like this:
WITH
p AS
(
SELECT
UserId = p.OwnerUserId,
Score = MAX(p.Score)
FROM dbo.Posts AS p
GROUP BY
p.OwnerUserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM p
JOIN dbo.Comments AS c
ON c.UserId = p.UserId;
GO
Which would be a pretty good improvement straight out of the gate.
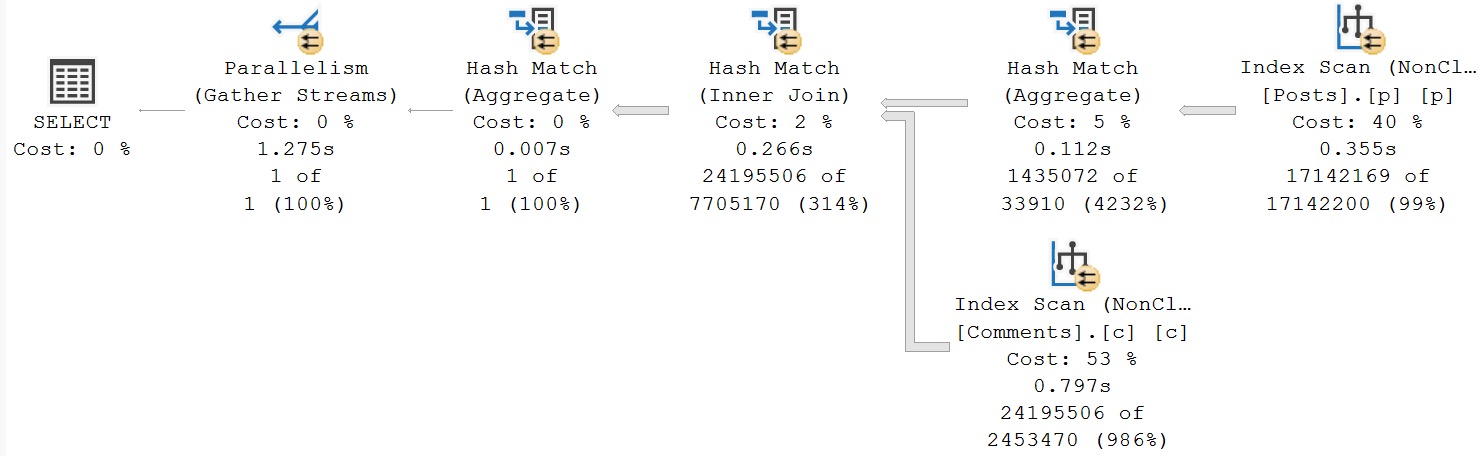
From 23 seconds to 1.2 seconds right off the bat. Pretty good. Note the join placement though, with Posts on the outer, and Comments on the inner side of the join.
Rewrite #2: Manually Aggregate Comments
What if we thought this was maybe a bad situation, and we wanted to try get a different query plan? What if we really didn’t enjoy the 986% overestimate?
WITH
c AS
(
SELECT
UserId = c.UserId,
Score = MAX(c.Score)
FROM dbo.Comments AS c
GROUP BY
c.UserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM dbo.Posts AS p
JOIN c
ON c.UserId = p.OwnerUserId;
GO
We could write the query like above, and see if SQL Server does any better. Right? Right.
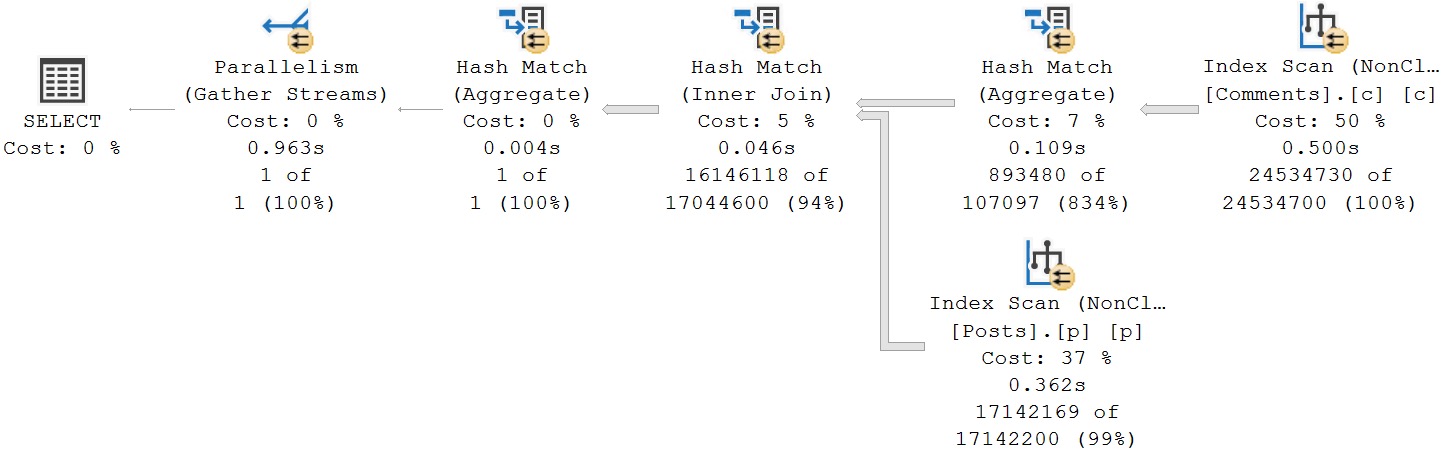
Now we’re down under a second. Comments is on the outer, and Posts is on the inner side of the join, and estimates across the board are just about spot-on.
I know what you’re thinking: We should aggregate BOTH first. When we leave it up to SQL Server’s optimizer, it’s still not getting the early aggregation message.
Rewrite #3: Manually Aggregate Both
You might be thinking “I bet if we aggregate both, it’ll take 500 milliseconds”. You’d be thinking wrong. Sorry.
WITH
p AS
(
SELECT
UserId = p.OwnerUserId,
Score = MAX(p.Score)
FROM dbo.Posts AS p
GROUP BY
p.OwnerUserId
),
c AS
(
SELECT
UserId = c.UserId,
Score = MAX(c.Score)
FROM dbo.Comments AS c
GROUP BY
c.UserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM p
JOIN c
ON c.UserId = p.UserId;
This is great. Aren’t common table expressions just great? Yay. yay. y?
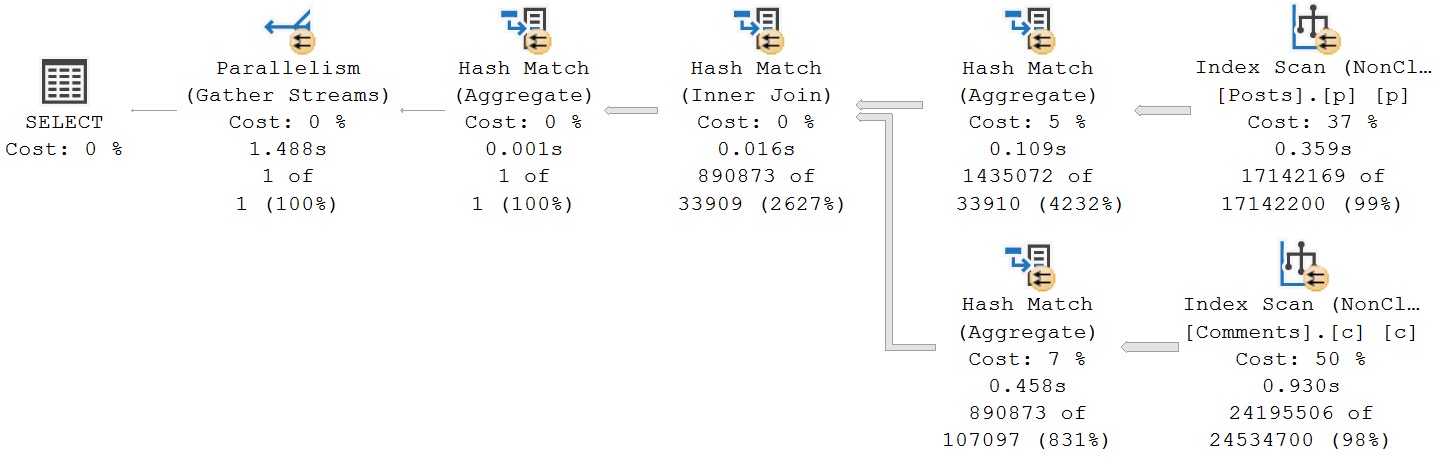
We made things nearly 500 milliseconds worse. I want to take this opportunity to share something annoying with you: it doesn’t matter which order we write our common table expressions in, or which order we join them in when we select data out of it, SQL Server’s optimizer chooses the exact same plan as this one. There’s no point in showing you the other query plans, because they look identical to this one: Posts is on the outer, and Comments is on the inner, side of the join.
Cardinality estimates improve somewhat but not in a meaningful way. We just know we’re gonna have to aggregate both sets before doing the join, so we get table cardinality right, but cardinality estimation for the aggregates are both pretty bad, and the join is screwed.
Rewrite #4: Manually Aggregate Both, Force Join Order
This must be the magic that finally improves things substantially. Right? Wrong.
WITH
p AS
(
SELECT
UserId = p.OwnerUserId,
Score = MAX(p.Score)
FROM dbo.Posts AS p
GROUP BY
p.OwnerUserId
),
c AS
(
SELECT
UserId = c.UserId,
Score = MAX(c.Score)
FROM dbo.Comments AS c
GROUP BY
c.UserId
)
SELECT
PScore = MAX(p.Score),
CScore = MAX(c.Score)
FROM c
JOIN p
ON c.UserId = p.UserId
OPTION(FORCE ORDER);
GO
Doing this will suplex the optimizer into putting Comments on the outer, and Posts on the inner side of the join.
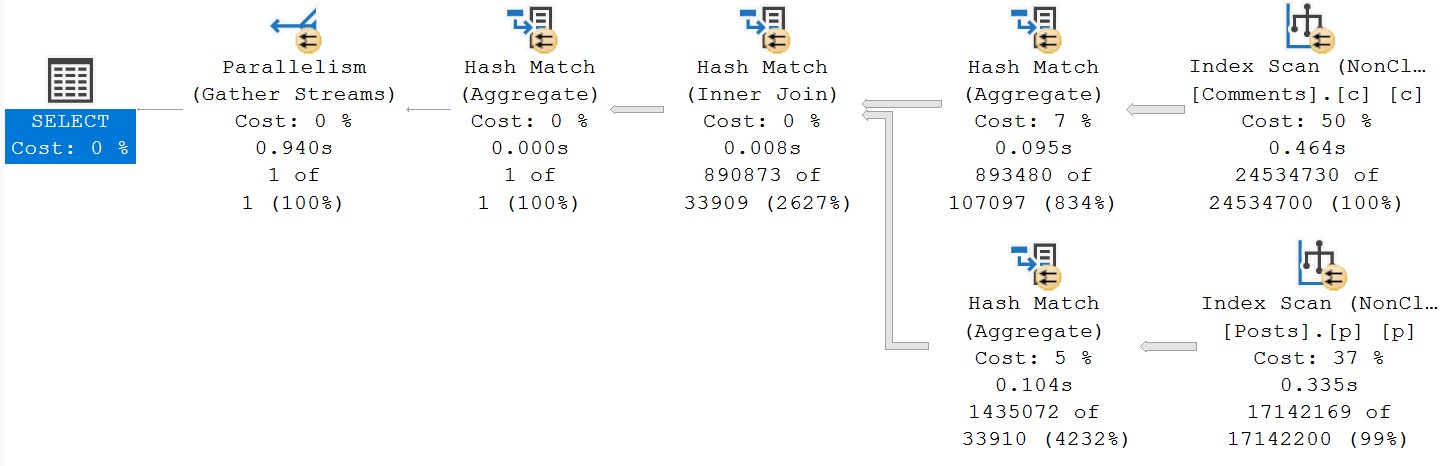
This, unfortunately, only gets us in about as good a situation as when we only did a manual aggregate of the Comments table. Given the current set of indexes, the only thing I could find that gave meaningful improvement was to run at DOP 16 rather than DOP 8.
The current set of indexes look like this:
CREATE INDEX
c
ON dbo.Comments
(Score)
INCLUDE
(UserId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
p
ON dbo.Posts
(Score, OwnerUserId)
INCLUDE
(PostTypeId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
And remember I said at the beginning: SQL Server’s optimizer is insistent that better indexes would make things better.
In tomorrow’s post, we’ll look at how that goes.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.