Good And Bad
The good news is that SQL Server’s query plans will attempt to warn you about problems. The bad news is that most of the warnings only show up in Actual Execution Plans. The worse news is that a lot of the warnings that try to be helpful in Estimated Execution plans can be pretty misleading.
Here’s a current full list:
<xsd:element name="SpillOccurred" type="shp:SpillOccurredType" minOccurs="0" maxOccurs="1"/> <xsd:element name="ColumnsWithNoStatistics" type="shp:ColumnReferenceListType" minOccurs="0" maxOccurs="1"/> <xsd:element name="SpillToTempDb" type="shp:SpillToTempDbType" minOccurs="0" maxOccurs="unbounded"/> <xsd:element name="Wait" type="shp:WaitWarningType" minOccurs="0" maxOccurs="unbounded"/> <xsd:element name="PlanAffectingConvert" type="shp:AffectingConvertWarningType" minOccurs="0" maxOccurs="unbounded"/> <xsd:element name="SortSpillDetails" type="shp:SortSpillDetailsType" minOccurs="0" maxOccurs="unbounded"/> <xsd:element name="HashSpillDetails" type="shp:HashSpillDetailsType" minOccurs="0" maxOccurs="unbounded"/> <xsd:element name="ExchangeSpillDetails" type="shp:ExchangeSpillDetailsType" minOccurs="0" maxOccurs="unbounded"/> <xsd:element name="MemoryGrantWarning" type="shp:MemoryGrantWarningInfo" minOccurs="0" maxOccurs="1"/> <xsd:attribute name="NoJoinPredicate" type="xsd:boolean" use="optional"/> <xsd:attribute name="SpatialGuess" type="xsd:boolean" use="optional"/> <xsd:attribute name="UnmatchedIndexes" type="xsd:boolean" use="optional"/> <xsd:attribute name="FullUpdateForOnlineIndexBuild" type="xsd:boolean" use="optional"/>
Certain of these are considered runtime issues, and are only available in Actual Execution Plans, like:
- Spills to tempdb
- Memory Grants
I’ve never seen the “Spatial Guess” warning in the wild, which probably speaks to the fact that you can measure Spatial data/index adoption in numbers that are very close to zero. I’ve also never seen the Full Update For Online Index Build warning.
Then there are some others like Columns With No Statistics, Plan Affecting Converts, No Join Predicate, and Unmatched Indexes.
Let’s talk about those a little.
Columns With No Statistics
I almost never look at these, unless they’re from queries hitting indexed views.
The only time SQL Server will generate statistics on columns in an indexed view is when you use the NOEXPAND hint in your query. That might be very helpful to know about, especially if you don’t have useful secondary indexes on your indexed view.
If you see this in plans that aren’t hitting an indexed view, it’s likely that SQL Server is complaining that multi-column statistics are missing. If your query has a small number of predicates, it might be possible to figure out which combination and order will satisfy the optimizer, but it’s often not worth the time involved.
Like I said, I rarely look at these. Though one time it did clue me in to the fact that a database had auto create stats disabled.
So I guess it’s nice once every 15 years or so.
Plan Affecting Converts
There are two of these:
- Ones that might affect cardinality estimates
- Ones that might affect your ability to seek into an index
Cardinality Affecting
The problem I have with the cardinality estimation warning is that it shows up when it’s totally useless.
SELECT TOP (1)
Id = CONVERT(varchar(1), u.Id)
FROM dbo.Users AS u;

Like I said, misleading.
Seek Affecting
These can be misleading, but I often pay a bit more attention to them. They can be a good indicator of data type issues in comparison operations.
Where they’re misleading is when they tell you they mighta-coulda done a seek, when you don’t have an index that would support a seek.
SELECT TOP (1)
u.Id
FROM dbo.Users AS u
WHERE u.Reputation = CONVERT(sql_variant, N'138');
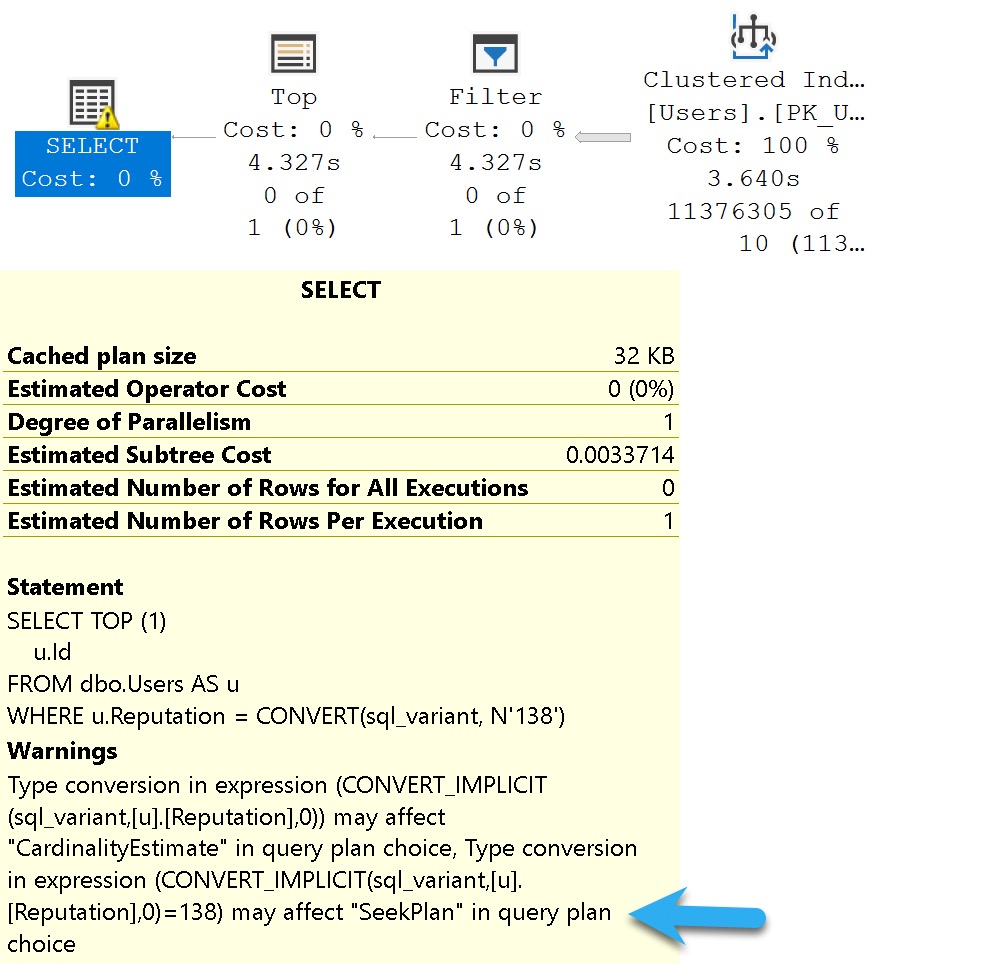
Of course, without an index on Reputation, what am I going to seek to?
Nothing. Nothing at all.
No Join Predicate
This one is almost a joke, I think.
Back when people wrote “old style joins”, they could have missed a predicate, or something. Like so:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u,
dbo.Badges AS b,
dbo.Comments AS c
WHERE u.Id = b.UserId;
/*Oops no join on comments!*/
Except there’s no warning in this query plan for a missing join predicate.
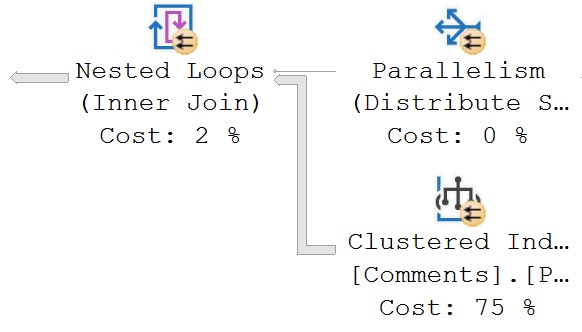
But if we change the query to this, it’ll show up:
SELECT
u.Id
FROM dbo.Users AS u,
dbo.Badges AS b,
dbo.Comments AS c
WHERE u.Id = b.UserId;
/*Oops no join on comments!*/
But let’s take a query that has a join predicate:
SELECT TOP (1)
b.*
FROM dbo.Comments AS c
JOIN dbo.Badges AS b
ON c.UserId = b.UserId
WHERE b.UserId = 22656;
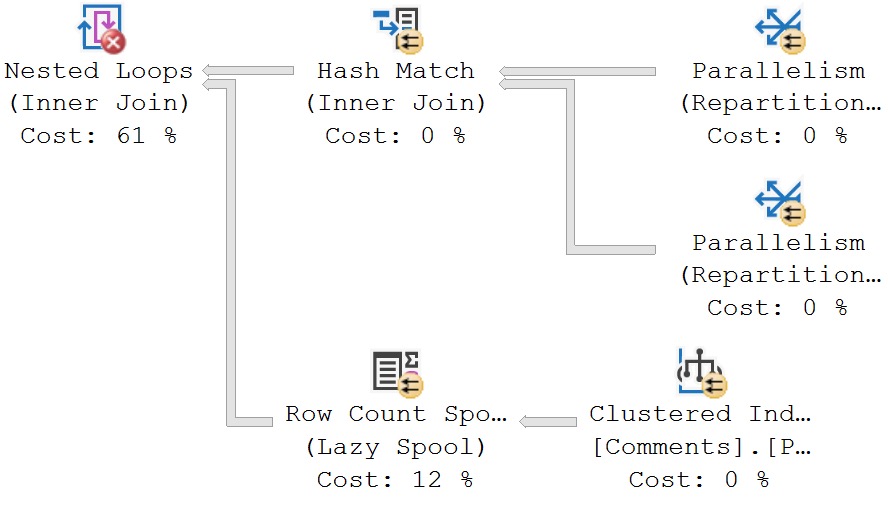
We still get that warning:

We still get a missing join predicate, even though we have a join predicate. The predicate is implied here, because of the where clause.
But apparently the check for this is only at the Nested Loops Join. No attempt is made to track pushed predicates any further.

If there were, the warning would not appear.
Unmatched Indexes
If you create filtered indexes, you should know a couple things:
- It’s always a good idea to have the column(s) you’re filter(ing) on somewhere in the index definition (key or include, whatever)
- If query predicate(s) are parameterized on the column(s) you’re filter(ing) on, the optimizer probably won’t choose your filtered index
I say probably because recompile hints and unsafe dynamic SQL may prompt it to use your filtered index. But the bottom line here is parameters and filtered indexes are not friends in some circumstances.
Here’s a filtered index:
CREATE INDEX
cigarettes
ON dbo.Users
(Reputation)
WHERE
(Reputation >= 1000000)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
And here’s a query that should use it:
SELECT
u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation >= 1000000;
BUUUUUUUUUUUUUUUT!
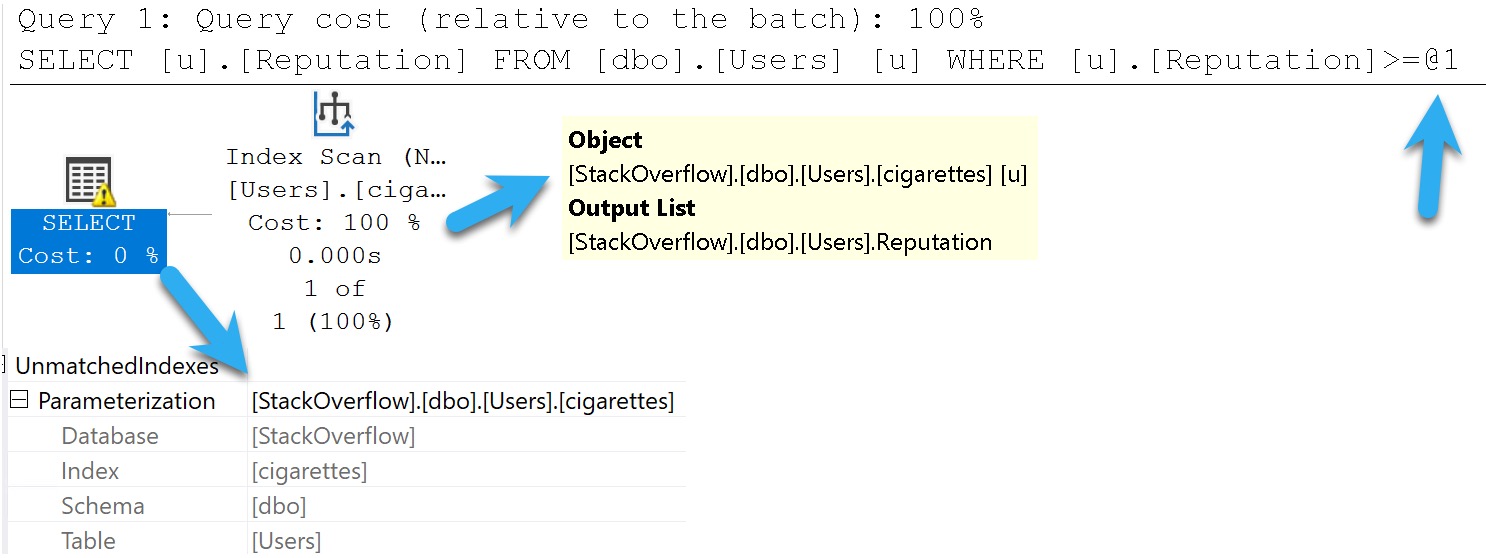
SQL Server warns us we didn’t. This is an artifact of Simple Parameterization, which happens early on in the Trivial Plan optimization phase.
It’s very misleading, that.
Warnings And Other Drugs
In this post we covered common scenarios when plan warnings just don’t add up to much of a such. Does that mean you should always ignore them? No, but also don’t be surprised if your investigation turns up zilch.
If you’re interested in learning more about spills, check out the Spills category of my blog. I’ve got a ton of posts about them.
At this point, you’re probably wondering why people bother with execution plans. I’m sort of with you; everything up to the actual version feels futile and useless, and seems to lie to you.
Hopefully Microsoft invests more in making the types of feedback mechanisms behind gathering plans and runtime metrics easier for casual users in future versions of SQL Server.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.