Batchius Modius
Much like parallelism, Batch Mode is something I often resort to to make queries get reliably faster.
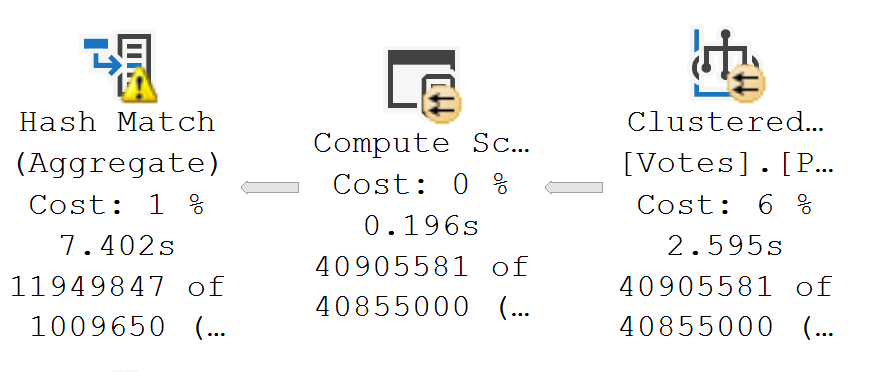
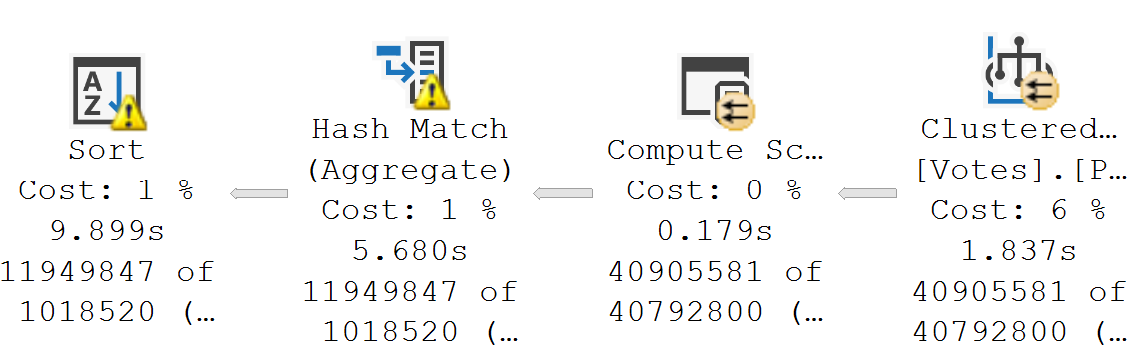
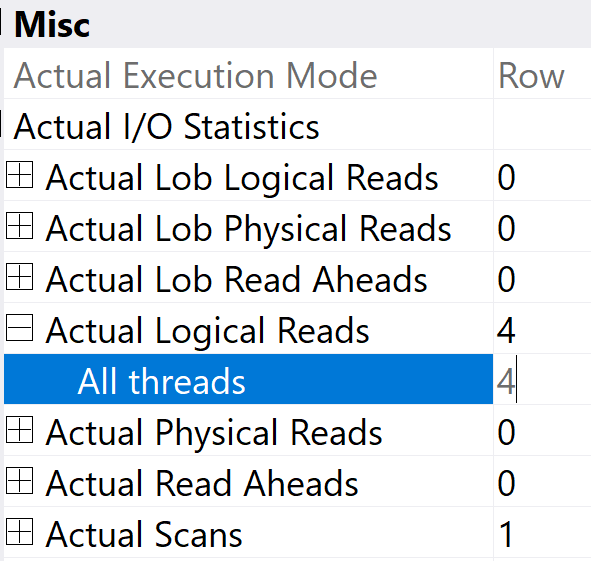
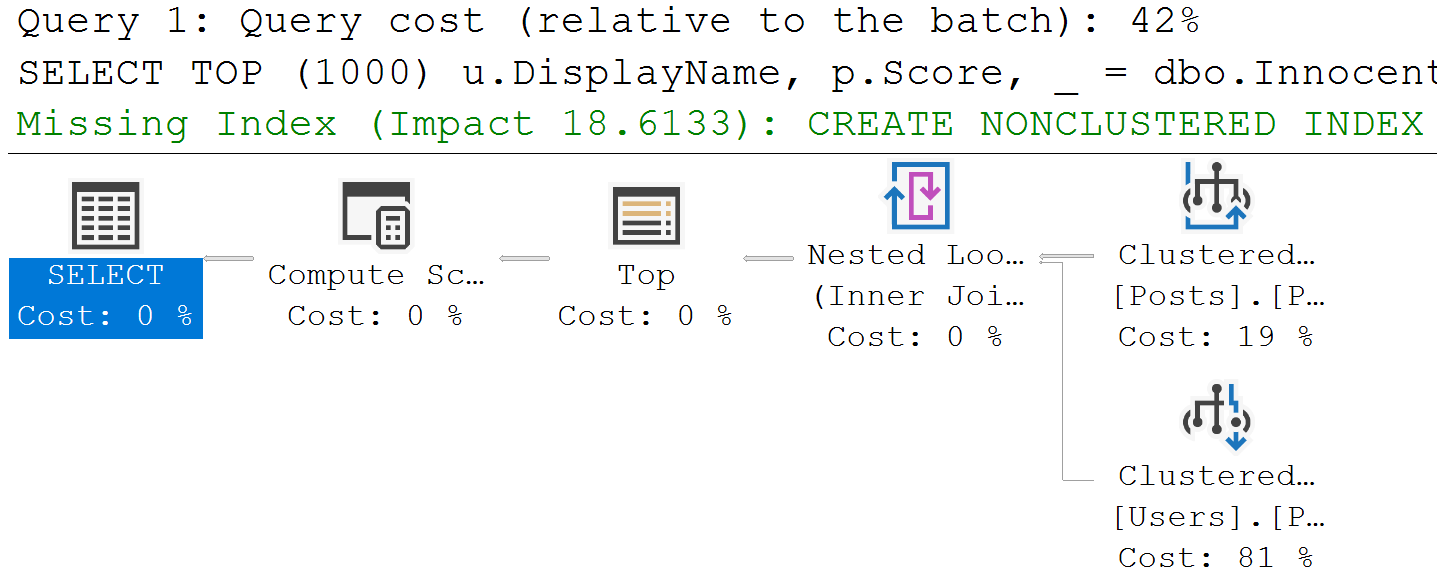
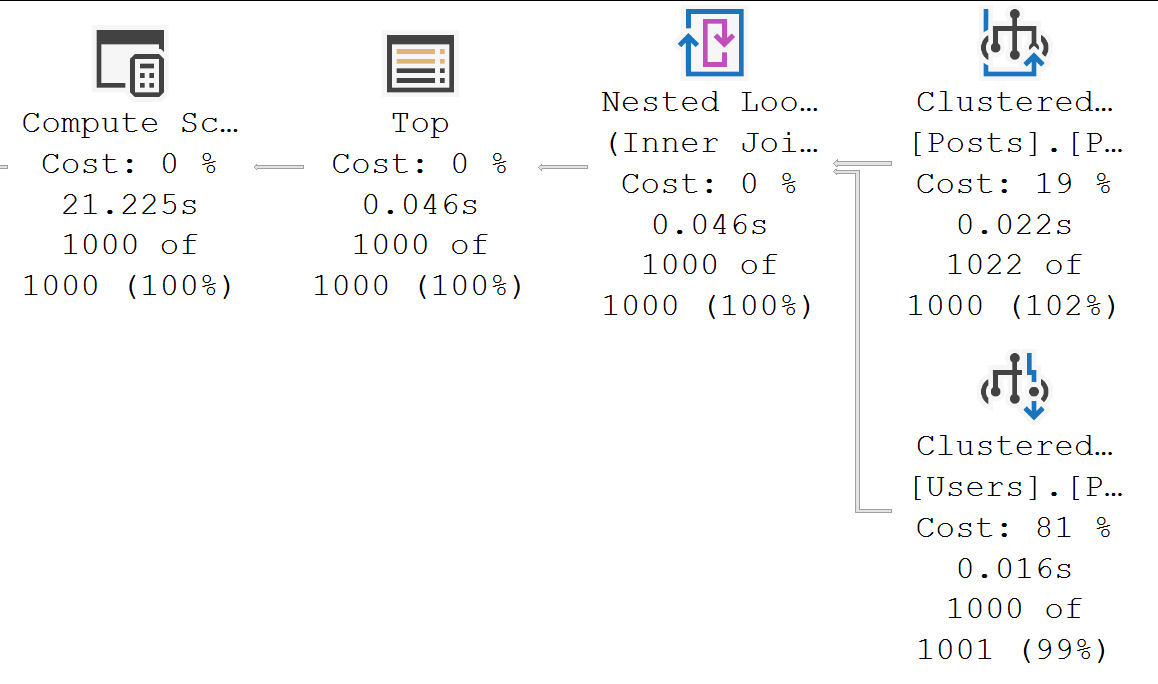
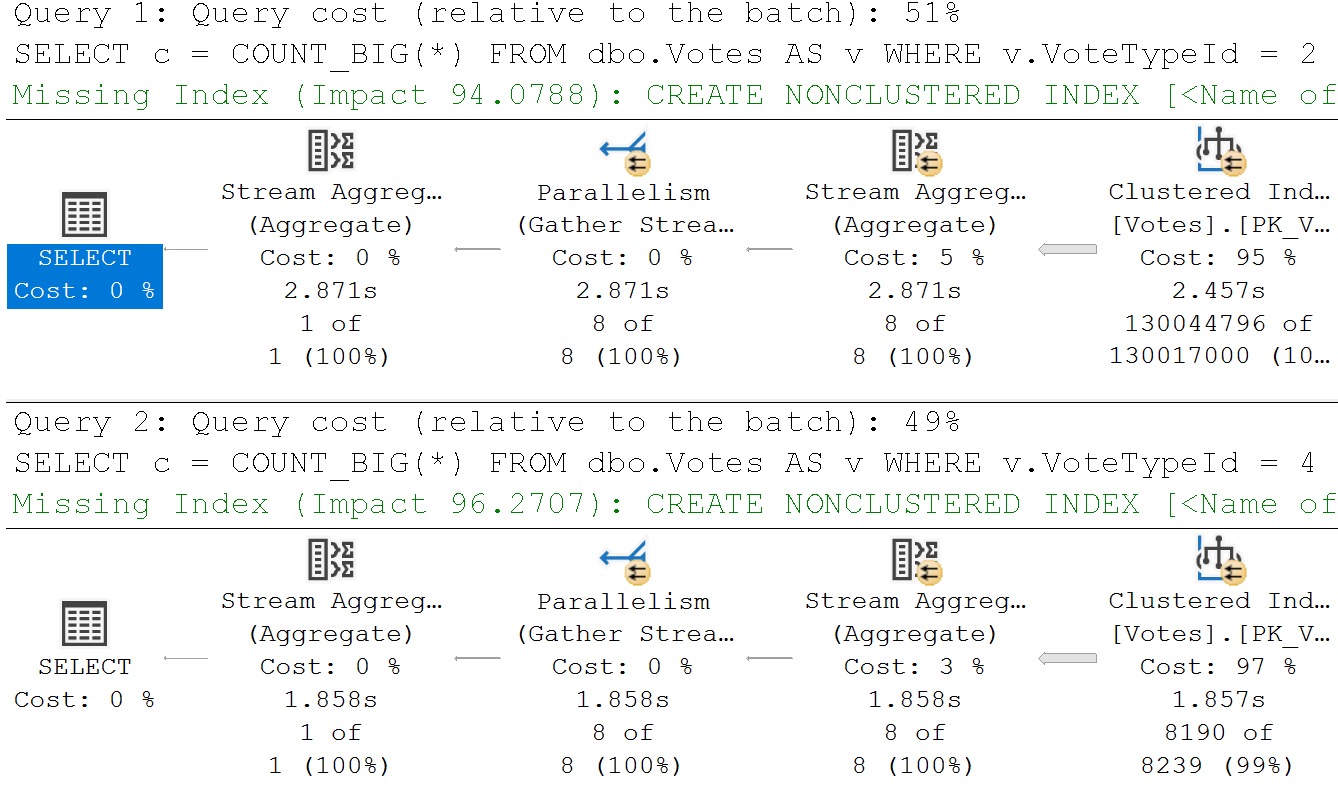
There aren’t a lot of great visual indicators in SSMS about when a query uses it, aside from:
- Adaptive joins
- Operator Properties (Execution Mode)
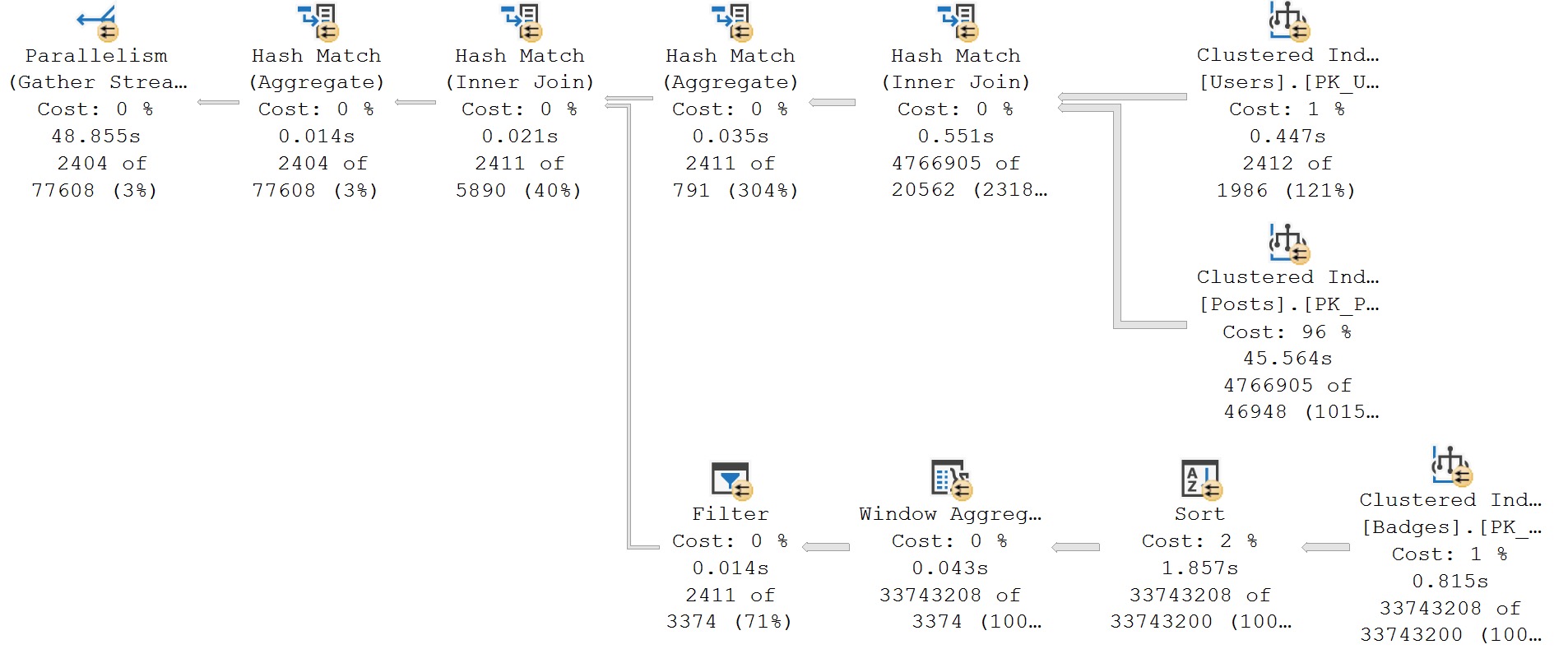
- Window Aggregates
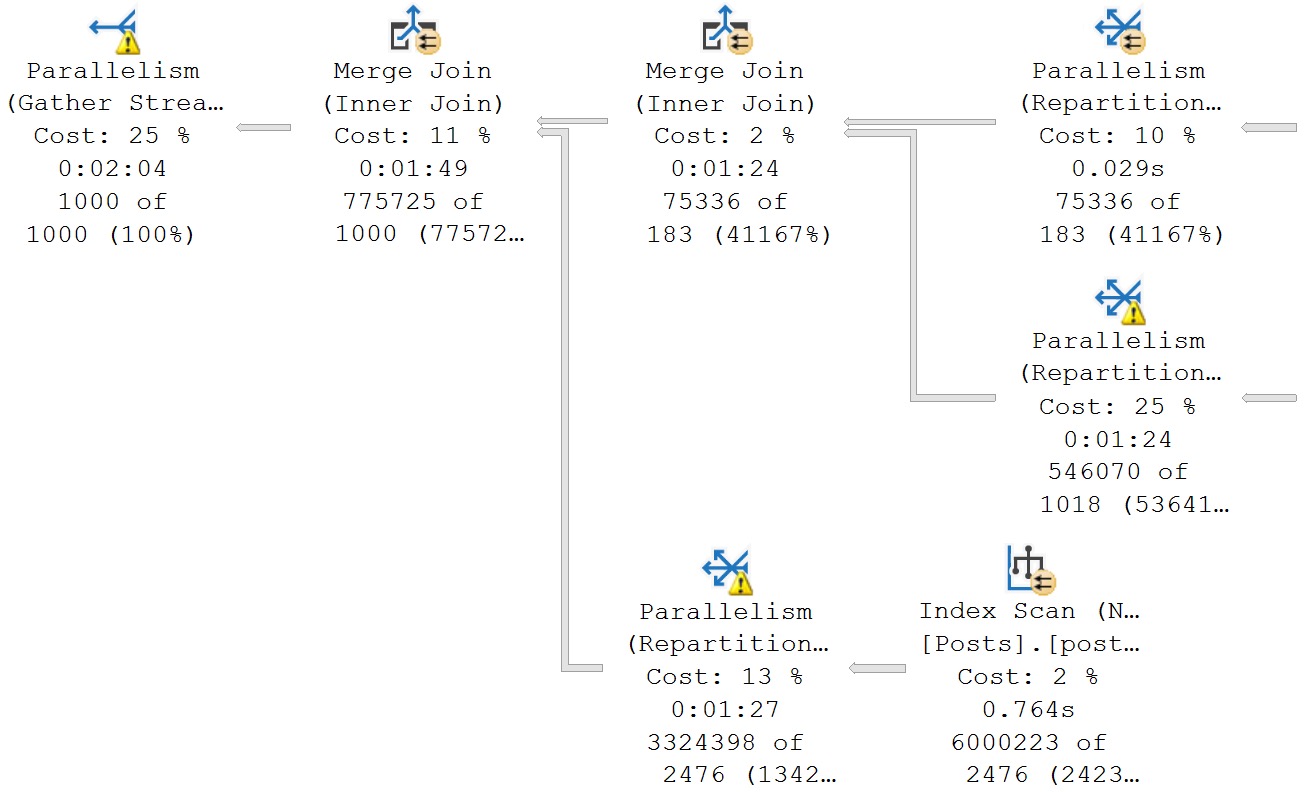
- Parallel plans sometimes missing Exchange Operators
- Your horrible reporting query finishes immediately for some reason
There might be more, but I’ve been day drinking.
Of course, it’s basically useless on Standard Edition:
https://erikdarling.com/sql-server/how-useful-is-column-store-in-standard-edition/
Heuristic Worship
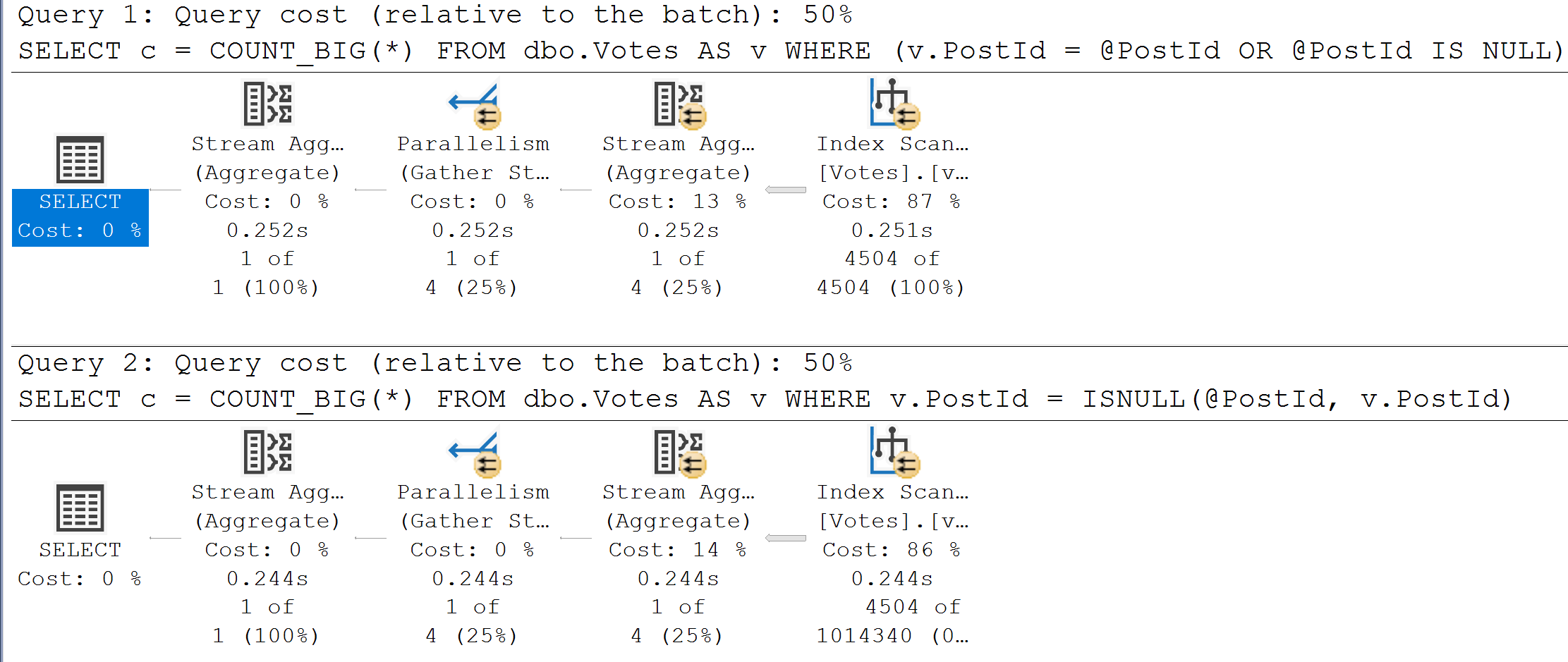
Prior to SQL Server 2019, you needed to have a columnstore index present somewhere for batch mode to kick in for a query.
Somewhere is, of course, pretty loose. Just having one on a table used in a query is often enough, even if a different index from the table is ultimately used.
That opened up all sorts of trickery, like creating empty temporary or permanent tables and doing a no-op left join to them, on 1 = 0 or something along those lines.
Sure, you couldn’t read from rowstore indexes using batch mode doing that prior to SQL Server 2019, but any other operator that supported Batch Mode could use it.
- Hash Joins
- Hash Aggregates
- Sorts
- Window Aggregates
- Filter
- Compute Scalar
- Others, but again, I’ve been day drinking
You can read more about the differences here:
https://erikdarling.com/sql-server/batch-mode-on-row-store-vs-batch-mode-tricks/
Homebody
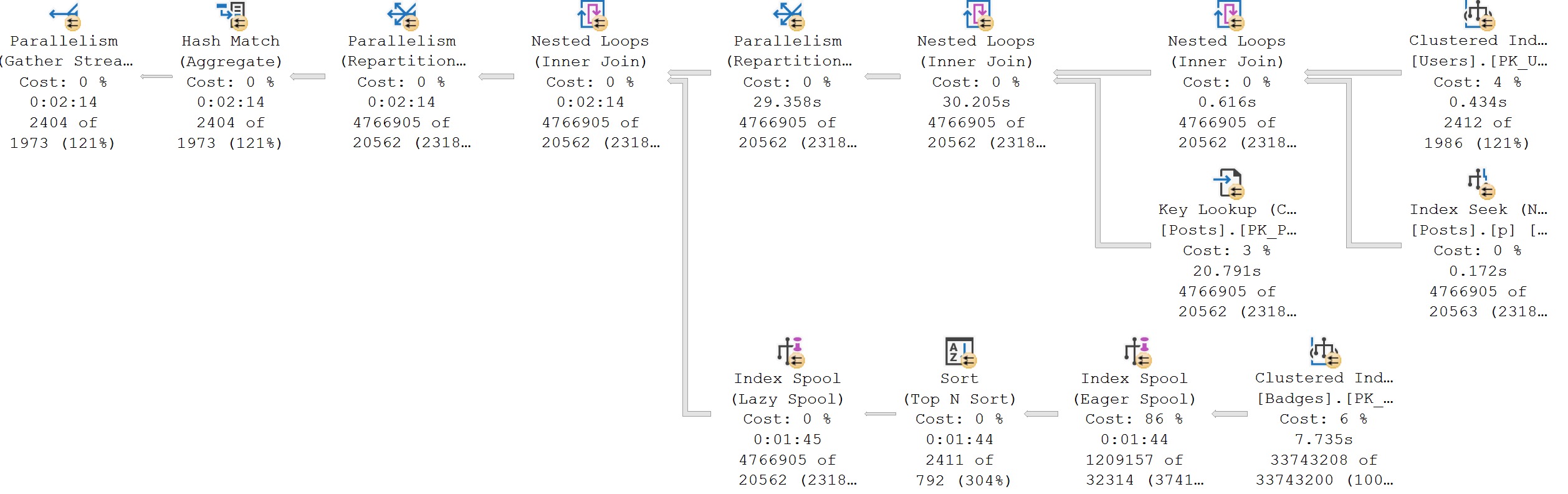
With SQL Server 2019 Enterprise Edition, in Compatibility Level 150, SQL Server can decide to use Batch Mode without a columnstore index, even reading from rowstore indexes in Batch Mode.
The great thing is that you can spend hours tediously tuning queries and indexes to get exactly the right plan and shape and operators or you can just use Batch Mode and get back to day drinking.
Trust me.
To get a sense of when you should be trying to get Batch Mode in your query plans, check out this post:
https://erikdarling.com/sql-server/signs-you-need-batch-mode-for-your-sql-server-queries/
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.