Jam Job
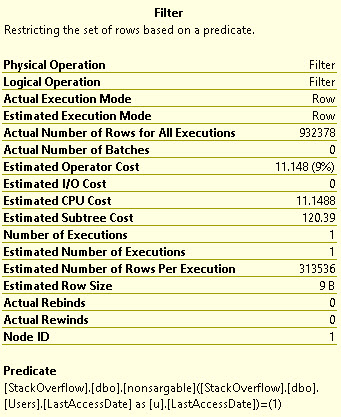
Hash spills are, as we’ll see, sometimes identified by a different wait than sort spills. In small quantities, spills are often not worth bothering with. But when they pile up, they can really cause some severe performance issues.
In this post, I want to show that both Hash Aggregates and Joins can cause the same wait type, along with some evidence that strings make things worse.
In all the queries, I’m going to be using the MAX_GRANT_PERCENT hint to set the memory grant ridiculously low, to make the waits I care about stick out.
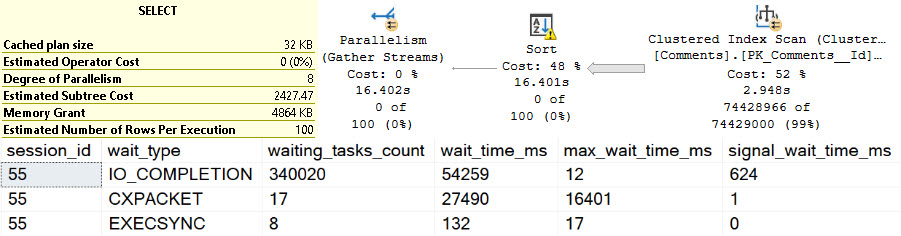
For each query we run, we’re gonna execute the query, and then this query to look at session level wait stats.
SELECT
desws.*
FROM sys.dm_exec_session_wait_stats AS desws
WHERE desws.session_id = @@SPID
ORDER BY desws.wait_time_ms DESC;
Merch Pants
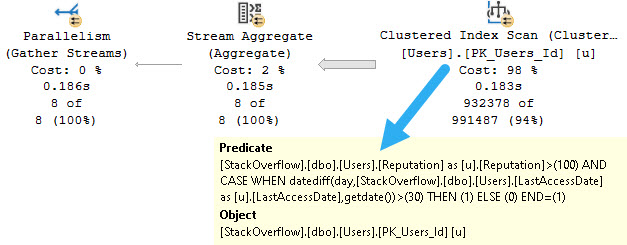
First up, a highly doctored hash aggregate:
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.UserId
FROM dbo.Comments AS c
GROUP BY
c.CreationDate,
c.PostId,
c.Score,
c.UserId
HAVING COUNT_BIG(*) > 2147483647
OPTION(HASH GROUP, QUERYRULEOFF GenLGAgg, MAX_GRANT_PERCENT = 0.0);
But the important thing here is that there are no strings involved.
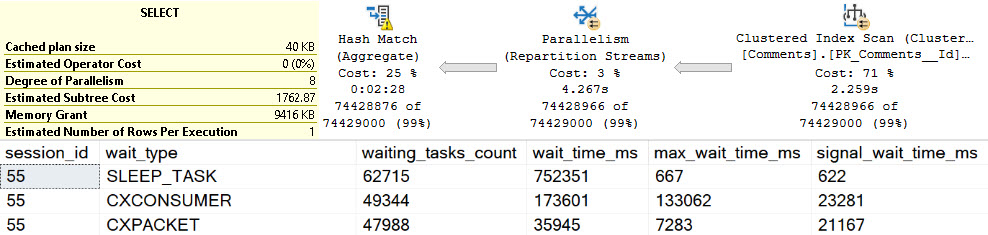
The spill goes on for about two minutes and twenty seconds, in row mode, at DOP 8.
That sure is bad, but in the words of Sticky Fingaz: Bu-bu-bu-but wait it gets worse.
Foolproof Plan
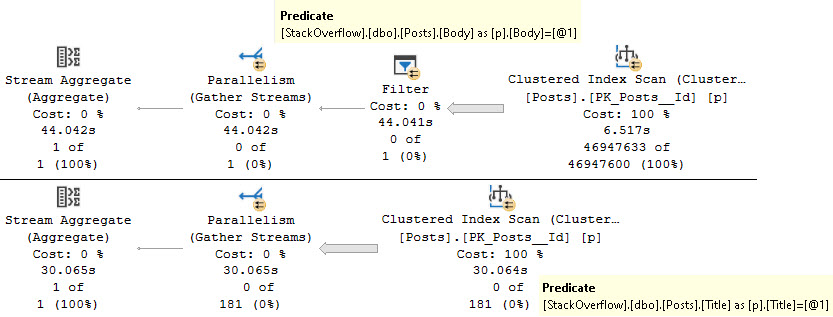
Let’s pull out another highly doctored hash aggregate, this time with our friend the Text column.
SELECT
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
GROUP BY
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
HAVING COUNT_BIG(*) > 2147483647
OPTION(HASH GROUP, QUERYRULEOFF GenLGAgg, MAX_GRANT_PERCENT = 0.0);
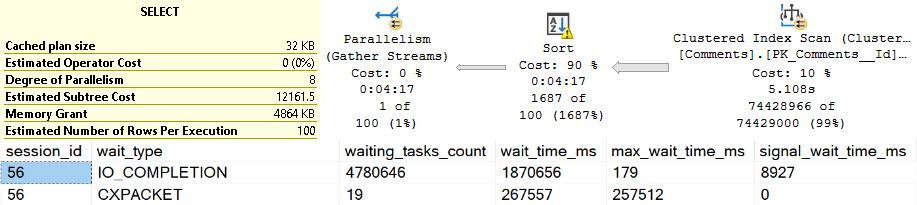
We see more of our friend SLEEP_TASK. Again, many other things may add to this wait, but holy hoowee, this is hard to ignore.
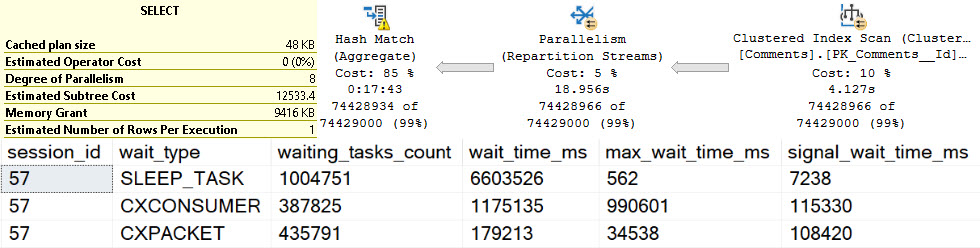
That’s a solid — heck, let’s just call it 18 minutes — of spill time. That’s just plain upsetting.
Filthy.
And Join
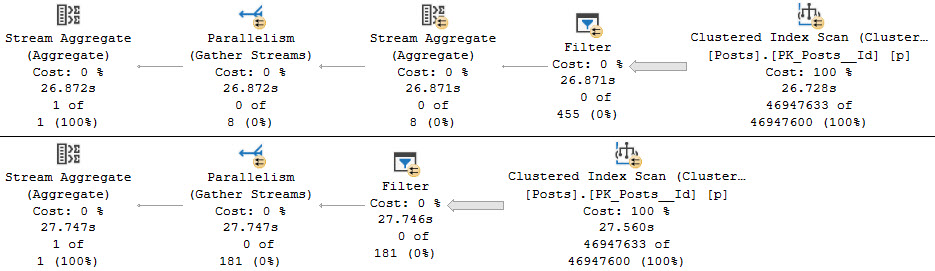
Causing the same problem where a Hash Join is in play will exhibit the same wait.
SELECT
c.*
FROM dbo.Votes AS v
LEFT JOIN dbo.Comments AS c
ON v.PostId = c.PostId
WHERE ISNULL(v.UserId, c.UserId) > 2147483647
OPTION(MAX_GRANT_PERCENT = 0.0);
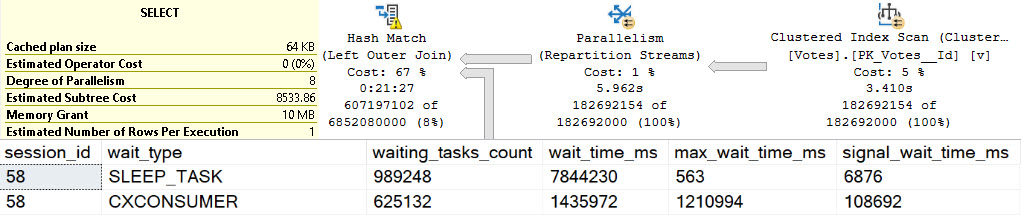
Now we get stuck spilling for about 21 minutes, which is also awkward and uncomfortable.
Funkel
We’ve looked at sort spills being the cause of IO_COMPLETION waits, and hash spills being the cause of SLEEP_TASK waits.
Again, if you see a lot of these waits on your servers, you may want to check out the query here to find plans in the cache that are selects that cause writes, for reasons explained in the linked post.
Tomorrow we’ll wake up bright and early to look at which waits crop up during exchange spills.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.