You Know You Wanna
Every time you push F5, decades of research, code, and math kick in and have their way with your query. No, really. They do.
Your query is a question that the database has to answer, and not only does it have to make sure that your syntax is correct, and the objects you’re asking questions of exist, but it also needs to figure out the cheapest way to come up with that answer.
How you design tables and indexes and constraints, and write your queries, can help better choices get made. But we’re getting ahead of ourselves a little bit, aren’t we?
The first thing we have to talk about is the difference between how you write your query, and how the database sees your query.
It’s Trees All The Way Down
You start your query with a select, list a bunch of columns, maybe calculate some expressions, or do some aggregations. Sometimes you can throw a top or distinct in there for fun.
Then you mosey on to from, maybe with a join or forty, and hopefully a where clause that’ll filter out some rows. Good stuff. I’m proud of you already.
If you’re feeling extra spicy (or if necessitated by the abovesaid aggregation), you might group by some columns. It’s nice to not get error messages, after all.
After that, you’ve got your order by, if you so choose. Or if your query needs data in a particular order. Remember, without an order by, you don’t get data in a special order.
Of course, there are some less common things you may do along the way. You might use cube or rollup, a having clause, or use offset/fetch.
But the point is that the optimizer rearranges things a little bit. That old dog goes from > where > group by > having > select > order by.
Wild, right? But what does that mean for you?
It’s Tables All The Way Down, Too
When you run a query, the results are tabular, but not necessarily a table. That’s why you’re allowed to do certain things when you nest parts of the query that you can’t do without some nesting.
For example, I can reference an alias in the order by, because the optimizer processes the select list first:
SELECT p.PostTypeId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
GROUP BY p.PostTypeId
ORDER BY records DESC;
But I can’t reference that alias in the where clause, because it hasn’t been materialized yet.
SELECT p.PostTypeId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE records > 1000
GROUP BY p.PostTypeId
ORDER BY records DESC;
I know, I know. This is what having is for. But you’re jumping ahead again.
The point I’m getting to is that with a little nesting, we can take those tabular results and work with them in a way that’s totally tubular.
SELECT *
FROM
(
SELECT p.PostTypeId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
GROUP BY p.PostTypeId
) AS not_a_table
WHERE not_a_table.records > 1000
ORDER BY records DESC;
Virtually Yours
The thing is, that internal query isn’t physically materialized anywhere. The result set is computed, and the filter is applied against that result.
That means you have to calculate it every single time. The same goes for if you put it in a (non-materialized) view. That view will run the query and calculate the result and return it to the user, but it won’t physically exist anywhere.
For example, let’s look at two logically equivalent queries.
SELECT *
FROM
(
SELECT p.PostTypeId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
GROUP BY p.PostTypeId
) AS not_a_table
WHERE not_a_table.records > 1000
ORDER BY records DESC;
SELECT p.PostTypeId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
GROUP BY p.PostTypeId
HAVING COUNT_BIG(*) > 1000
ORDER BY records DESC;
When we run them, the optimizer comes up with identical physical implementations of both queries.
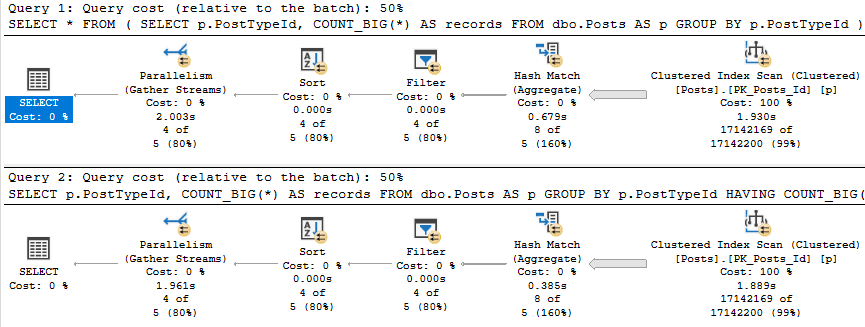
If I run them both a few times, the operator times will wiggle back and forth some, but the plans don’t change, and they both take in the neighborhood of two seconds each.
The point here is that there’s no performance advantage right now to either query form. So if this is something you need to calculate frequently, you might start looking at ways to physically persist the result. That way queries that need it would have to do less work.
Tomorrow, we’ll start to look at how indexes can help things out.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.