Mostoftentimes
There is a good solution to alleviating parameter sniffing. Ones I commonly use are:
- Temp tables
- Changing indexes
- Dynamic SQL
There isn’t really a good place to put a temp table in this stored procedure, though I did blog about a similar technique before.
It would certainly be a good candidate for index changes though, because the first thing we need to address is that key lookup.
It’s a sensitive issue.
King Index
We’re going to walk through something I talked about what seems like an eternity ago. Why? Because it has practical application here.
When you look at the core part of the query, PostId is only in the select list. Most advice around key lookups (including, generally, my own) is to consider putting columns only in the output into the includes of the index.
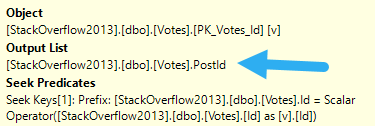
But we’re in a slightly different situation, here.
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
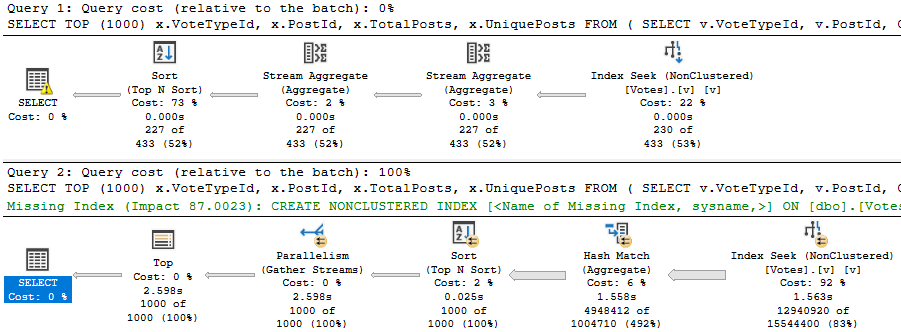
We’re getting a distinct count, and SQL Server has some choices for coming up with that.
If we follow the general advice here and create this index, we’ll end up in trouble:
CREATE INDEX v
ON dbo.Votes(VoteTypeId, CreationDate) INCLUDE(PostId)
WITH (DROP_EXISTING = ON);
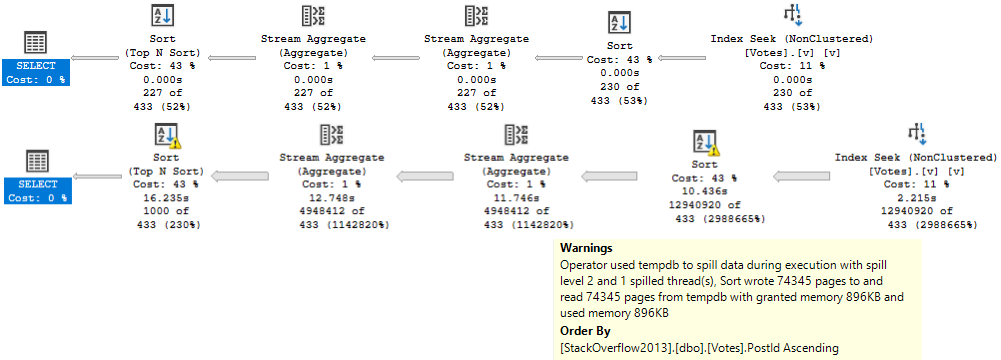
Since the Stream Aggregate expects ordered data, and PostId isn’t in order in the index (because includes aren’t in any particular order), we need to sort it. For a small amount of data, that’s fine. For a large amount of data, it’s not.
There is a second Sort in the plan further down, but it’s on the count expression, which means we can’t index it without adding in additional objects, like an indexed view.
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts, -- this is the expression
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC; -- this is the ordering
What’s An Index To A Non-Believer?
A better index in this case looks like this:
CREATE INDEX v
ON dbo.Votes(VoteTypeId, PostId, CreationDate)
WITH (DROP_EXISTING = ON);
It will shave about 6 seconds off the run time, but there’s still a problem when the “big” data doesn’t go parallel:
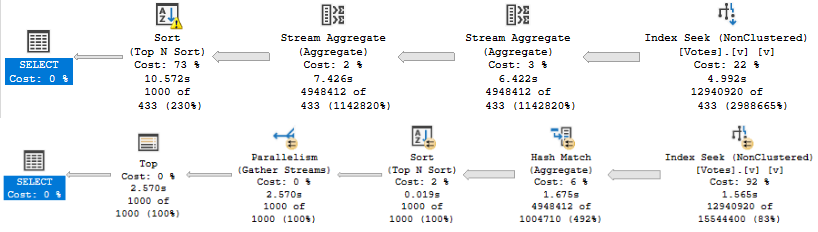
When the plan goes parallel, it’s about 4x faster than the serial version. Now I know what you’re thinking, here. We could use OPTIMIZE FOR to always get the plan for the big value. And that’s not a horrible idea — the small data parameter runs very quickly re-using the parallel plan here — but there’s another way.
Let’s look at our data.
Don’t Just Stare At It
Let’s draw an arbitrary line. I think a million is a popular number. I wish it was a popular number in my bank account, but you know.
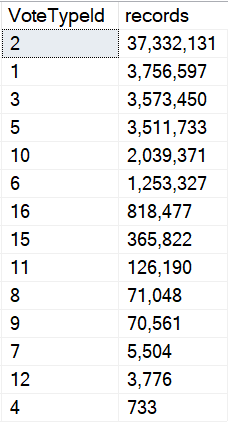
I know we’re ignoring the date column data, but this is good enough for now. There’s only so much I can squeeze into one blog post.
The point here is that we’re going to say that anything under a million rows is okay with using the small plan, and anything over a million rows needs the big plan.
Sure, we might need to refine that later if there are outliers within those two groups, but this is a blog post.
How do we do that? We go dynamic.
Behike 54
Plan ol’ IF branches plan ol’ don’t work. We need something to get two distinct plans that are re-usable.
Here’s the full procedure:
CREATE OR ALTER PROCEDURE dbo.VoteCount (@VoteTypeId INT, @YearsBack INT)
AS
BEGIN
DECLARE @sql NVARCHAR(MAX) = N'';
SET @sql += N'
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
/*dbo.VoteCount*/
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), ''2014-01-01'')
AND v.VoteTypeId = @VoteTypeId '
IF @VoteTypeId IN (2, 1, 3, 5, 10, 6)
BEGIN
SET @sql += N'
AND 1 = (SELECT 1)'
END
IF @VoteTypeId IN (16, 15, 11, 8, 9, 7, 12, 4)
BEGIN
SET @sql += N'
AND 2 = (SELECT 2)'
END
SET @sql += N'
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC;
';
RAISERROR('%s', 0, 1, @sql) WITH NOWAIT;
EXEC sys.sp_executesql @sql,
N'@VoteTypeId INT, @YearsBack INT',
@VoteTypeId, @YearsBack;
END;
There’s a bit going on in there, but the important part is in the middle. This is what will give use different execution plans.
IF @VoteTypeId IN (2, 1, 3, 5, 10, 6)
BEGIN
SET @sql += N'
AND 1 = (SELECT 1)'
END
IF @VoteTypeId IN (16, 15, 11, 8, 9, 7, 12, 4)
BEGIN
SET @sql += N'
AND 2 = (SELECT 2)'
END
Sure, there are other ways to do this. You could even selectively recompile if you wanted to. But some people complain when you recompile. It’s cheating.
Because the SQL Server Query Optimizer typically selects the best execution plan for a query, we recommend only using hints as a last resort for experienced developers and database administrators.
See? It’s even documented.
Now that we’ve got that all worked out, we can run the procedure and get the right plan depending on the amount of data we need to shuffle around.
Little Star
Now I know what you’re thinking. You wanna know more about that dynamic SQL. You want to solve performance problems and have happy endings.
We’ll do that next week, where I’ll talk about common issues, best practices, and more tricks you can use to get queries to perform better with it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Yesss!
Can’t wait next week! Wish to see a dynamic query with multitude of filtering fields and multitude of selected fields too and the best method to paginate without surprises when browsing the pages ?
I think you’ve seen that already ?
Yes! You are right but can’t get enough
Have you got a version of this where the list of IDs is not hardcoded ?
i.e. Have an overnight job that refills the table with those IDs with a high occurrence and use that to drive the IF statement ?
Or am I missing something fundamental ?
Just reluctant to put hard coding into my SPs
No, sorry, but it sounds like you’ve got a pretty good idea of what you’d want to do?
In this case, the numbers for a single value aren’t going to swing so rapidly that I’d worry about it.
Thanks!