Source Of Frustration
Ahem.
*taps mic*
When we write queries that need to filter data, we tend to want to have that filtering happen as far over to the right in a query plan as possible. Ideally, data is filtered when we access the index.
Whether it’s a seek or a scan, or if it has a residual predicate, and if that’s all appropriate isn’t really the question.
In general, those outcomes are preferable to what happens when SQL Server is unable to do any of them for various reasons. The further over to the right in a query plan we can reduce the number of rows we need to contend with, the better.
There are some types of filters that contain something called a “startup expression”, which are usually helpful. This post is not about those.
Ain’t Nothin’ To Do
There are some cases when you have no choice but to rely on a Filter to remove rows, because we need to calculate some expression that we don’t currently store the answer to.
For example, having:
SELECT
p.OwnerUserId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON c.PostId = p.Id
JOIN dbo.Votes AS v
ON v.PostId = p.Id
GROUP BY p.OwnerUserId
HAVING COUNT_BIG(*) > 2147483647;
We don’t know which rows might qualify for the count filter up front, so we need to run the entire query before filtering things out:
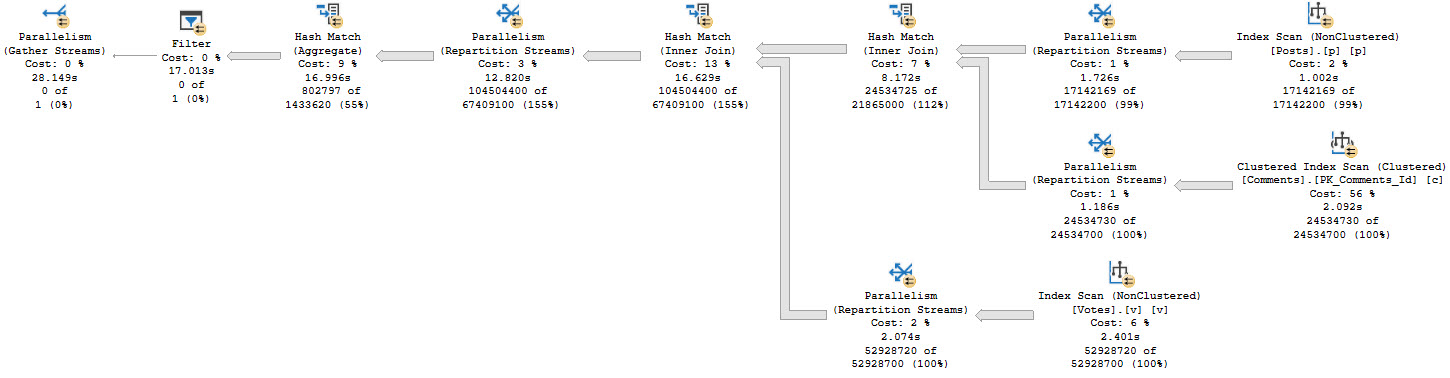
There’s a really big arrow going into that Filter, and then nothing!
Likewise, filtering on the result of a windowing function will get you a similar execution plan.
Of course, there’s not a lot to be done about these Filters, is there?
Unless you pre-compute things somewhere else, you have to figure them out at runtime.
Leftish Fetish
If you write yourself a left join, Filters may become more common, too.
You might do something terrible:
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE DATEDIFF(YEAR, p.CreationDate, p.LastActivityDate) > 5;
Or you might do something that seems reasonable:
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE p.Id IS NULL;
But what you get is disappointing!
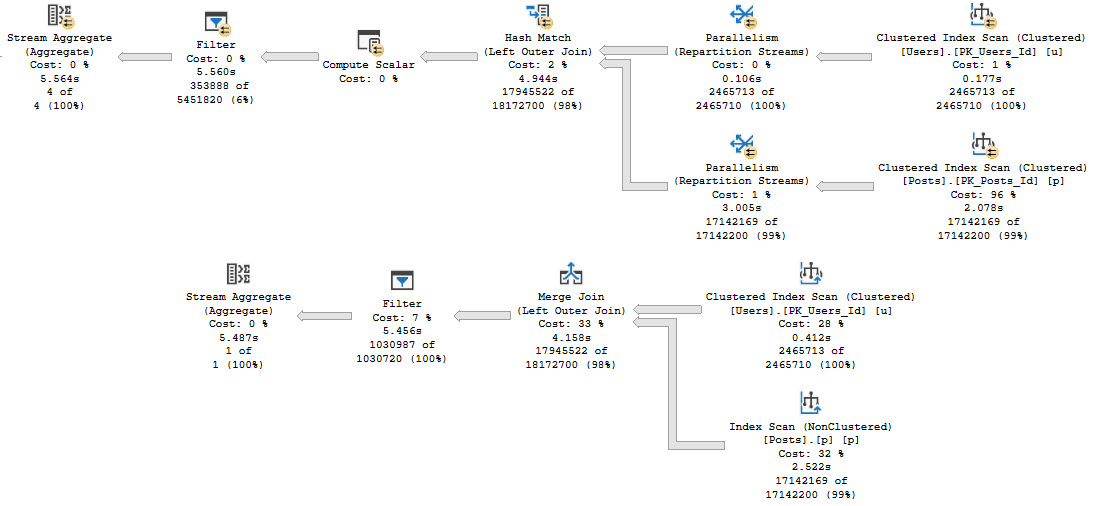
What we care about here is that, rather than filtering rows out when we touch indexes or join the tables, we have to fully join the tables together, and then eliminate rows afterwards.
This is generally considered “less efficient” than filtering rows earlier. Remember when I said that before? It’s still true.
Click the links above to see some solutions, so you don’t feel left hanging by your left joins.
The Message
If you see Filters in query plans, they might be for a good reason, like calculating things you don’t currently know the answer to.
They might also be for bad reasons, like you writing a query in a silly way.
There are other reasons they might show up too, that we’ll talk about tomorrow.
Why tomorrow? Why not today? Because if I keep writing then I won’t take a shower and run errands for another hour and my wife will be angry.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2017 CU 30: The Real Story With SelOnSeqPrj Fixes
- Getting Parameter Values From A SQL Server Query Plan For Performance Tuning
- Getting The Top Value Per Group With Multiple Conditions In SQL Server: Row Number vs. Cross Apply With MAX
- Getting The Top Value Per Group In SQL Server: Row Number vs. Cross Apply Performance
One thought on “Why You Shouldn’t Ignore Filter Operators In SQL Server Query Plans Part 1”
Comments are closed.