I Got No Rows
Over in the Votes table in the Stack Overflow database, a couple of the more popular vote types are 1 and 2.
A vote type of 1 means that an answer was accepted as being the solution by a user, and a vote type of 2 means someone upvoted a question or answer.
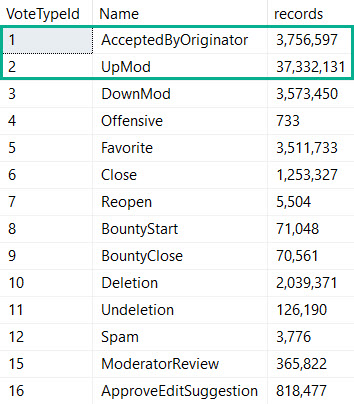
What this means is that it’s impossible for a question to ever have an accepted answer vote cast for it. A question can’t be an answer, here.
Unfortunately, SQL Server doesn’t have a way of inferring that.
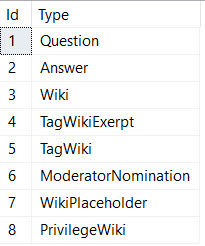
Anything with a post type id of 1 is a question.
The way the tables are structured, VoteTypeId and PostTypeId don’t exist together, so we can’t use a constraint to validate any conditions that exist between them.

Lost And Found
When we run a query that looks for posts with a type of 2 (that’s an answer) that have a vote type of 1, we can find 2500 of them relatively quickly.
SELECT TOP (2500)
p.OwnerUserId,
p.Score,
p.Title,
v.CreationDate,
ISNULL(v.BountyAmount, 0) AS BountyAmount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 2 --WHERE VoteTypeId = 2
AND p.PostTypeId = 1
ORDER BY v.CreationDate DESC;
Here’s the stats:
Table 'Posts'. Scan count 0, logical reads 29044 Table 'Votes'. Scan count 1, logical reads 29131 SQL Server Execution Times: CPU time = 63 ms, elapsed time = 272 ms.
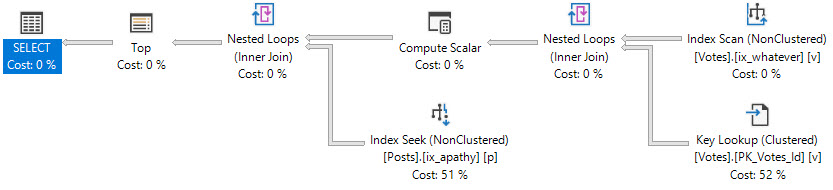
And here’s the plan:
Colossus of Woes
Now let’s ask SQL Server for some data that doesn’t exist.
SELECT TOP (2500)
p.OwnerUserId,
p.Score,
p.Title,
v.CreationDate,
ISNULL(v.BountyAmount, 0) AS BountyAmount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 1 --Where VoteTypeId = 1
AND p.PostTypeId = 1
ORDER BY v.CreationDate DESC;
Here’s the stats:
Table 'Posts'. Scan count 0, logical reads 11504587 Table 'Votes'. Scan count 1, logical reads 11675392 SQL Server Execution Times: CPU time = 14813 ms, elapsed time = 14906 ms.
You could say things got “worse”.
Not only that, but they got worse for the exact same plan.
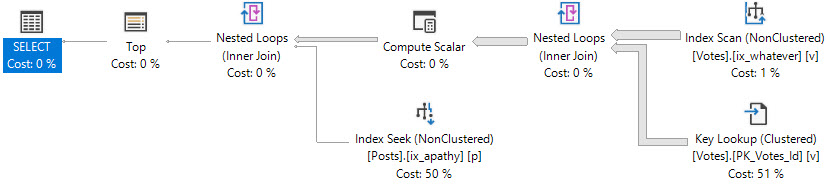
So What Happened?
In the original plan, the TOP asked for rows, and quickly got them.
In the second plan, the TOP kept asking for rows, getting them from the Votes table, and then losing them on the join to Posts.
There was no parameter sniffing, there were no out of date stats, no blocking, or any other oddities. It’s just plain bad luck because of the data’s relationship.
If we apply hints to this query to:
- Scan the clustered index on Votes
- Choose Merge or Hash joins instead of Nested Loops
- Force the join order as written
We get much better performing queries. The plan we have is chosen because the TOP sets a row goal that makes a Nested Loops plan using narrow (though not covering) indexes attractive to the optimizer. When it’s right, like in the original query, you probably don’t even think about it.
When it’s wrong, like in the second query, it can be quite mystifying why such a tiny query can run forever to return nothing.
If you want to try it out for yourself, use these indexes:
CREATE INDEX whatever
ON dbo.Votes( CreationDate, VoteTypeId, PostId );
CREATE NONCLUSTERED INDEX apathy
ON dbo.Posts ( PostTypeId )
INCLUDE ( OwnerUserId, Score, Title );
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
2 thoughts on “SQL Server Query Performance When You Search For Rare Data Points”
Comments are closed.