The Memes On The Blogs Fall Mainly On The Aughs
Unless your column is unique, and defined as unique, and people are searching for equality predicates on it — and I don’t mean column = column — I mean column = value, it might not be a great first column in your index. Many unique columns I see are identity columns that don’t necessarily define a relationship or usable search values. They’re cool for keeping the clustered index sane, but no one’s looking at the values in them.
The problem with the advice that you should “always put the most selective column first” is that not many columns are uniformly selective. For some ranges, they may be selective, for other ranges, they may not be.
Let’s look at some examples.
Usery
Let’s look at some tables in the Stack Overflow data dump. I realize this isn’t a perfect data set, but it has a lot of things in common with data sets I see out in the world.
- The site has gotten more popular over time, so year over year dates become less selective
- The site has definite groups of “power users” and “one and done” users
- Certain site activities are more common than others: votes cast, types of posts made
- Certain user attributes, like badges, are more common than others
All of these patterns are generally observable in real world data, too. Growth is a near constant, and with growth is going to come lumpy patterns.
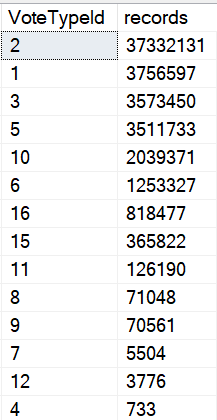
Looking at significant number differences here, the top vote type (an upvote) has 37 million entries. The next most popular one has 3.7 million.
Are either of those selective? No.
But when you get down to the bottom, you reach some selectivity.
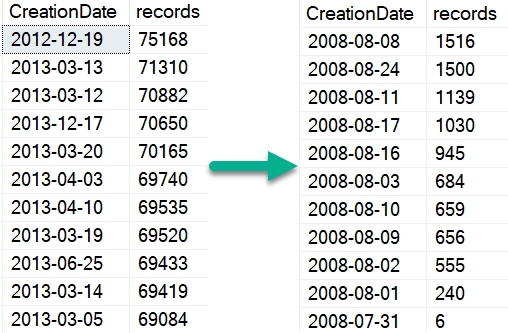
The dates the vote were cast become less selective over time, too.
Within User Reputations, things become skewed towards the bottom end.
Though the site gets more users overall, Reputation is still largely skewed towards power users.
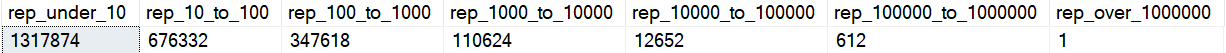
What Does This Mean For You?
- Don’t assume that just because you search for something with an equality that it’s the most selective predicate.
- Don’t assume that any search will always be selective (unless the column is unique).
- Don’t assume that the most selective predicate should always be the first column in an index; there are other query operations that should be considered as well
I can’t count the number of times that someone has told me something like “this query is fast, except when someone searches for X”, or “this query is fast, except when they ask for a year of data”, and the solution has been creating alternate indexes with key columns in a different order, or flipping current index key columns around.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.