Dos Puntos
Look, I really like EXISTS and NOT EXISTS. I do. They solve a lot of problems.
This post isn’t a criticism of them at all, nor do I want you to stop using them. I would encourage you to use them more, probably.
But there’s some stuff you need to be aware of when you use them, whether it’s in control-flow logic, or in queries.
If you keep your head about you, you’ll do just fine.
IF EXISTS
The issue you can hit here is one of row goals. And a T-SQL implementation shortcoming.
If I run this query, it’ll chug along for about 10 seconds.
IF EXISTS
(
SELECT
1/0
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 1
AND v.CreationDate >= '2018-12-01'
AND p.PostTypeId = 1
)
BEGIN
SELECT x = 1;
END;
The part of the plan that we care about is a seek into the Votes table.
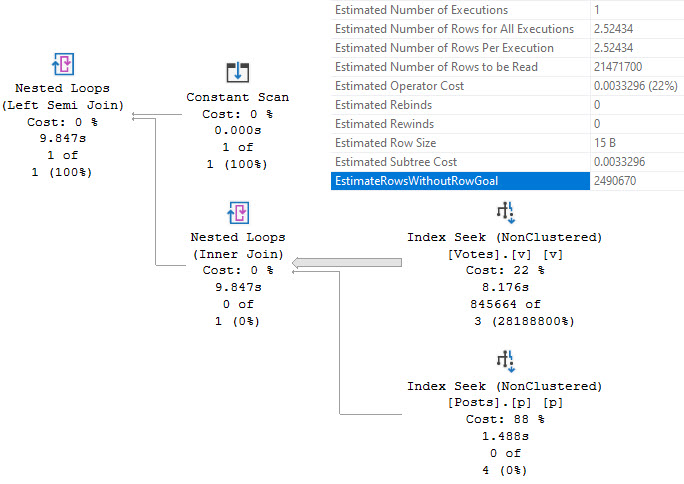
SQL SERVER’S COST BASED OPTIMIZER™ thinks that 2.52 (rounded to 3) rows will have to get read to find data we care about, but it ends up having to do way more work than that.
It’s worth a short topic detour here to point out that when you’re tuning a slow query, paying attention to operator costs can be a real bad time. The reason this query is slow is because the costing was wrong and it shows. Costed correctly, you would not get this plan. You would not spend the majority of the query execution time executes in the lowest-costed-non-zero operator.
Normally, you could explore query hints to figure out why this plan was chosen, but you can’t do that in the context of an IF branch. That sucks, because a Hash Join hinted query finished in about 400ms. We could solve a problem with that hint, or if we disabled row goals for the query.
Fixing It
In order to tune this, we need to toggle with the logic a little bit. Rather than put a query in the IF EXISTS, we’re going to set a variable based on the query, and use the IF logic on that, instead.
DECLARE
@do_it bit;
SELECT
@do_it =
(
SELECT
CONVERT
(
bit,
ISNULL
(
MAX(1),
0
)
)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 1
AND v.CreationDate >= '2018-12-01'
AND p.PostTypeId = 1
)
OPTION(HASH JOIN);
IF @do_it = 1
BEGIN
SELECT x = 1;
END;
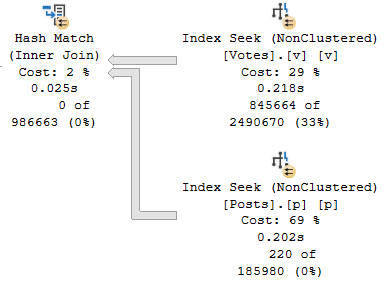
This produces the fast plan that we’re after. You can’t use a CASE expression here and get a hash join though, for reasons explained in this post by Pablo Blanco.
But here it is. Beautiful hash join.
EXISTS With OR Predicates
A common query pattern is to is EXISTS… OR EXISTS to sort out different things, but you can end up with a weird optimizer query rewrite (SplitSemiApplyUnionAll) that looks a lot like the LEFT JOIN… IS NULL pattern for finding rows that don’t exist. Which is generally a bad pattern, as discussed in the linked post.
Anyhoo.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation > 1000000
AND EXISTS
(
SELECT
1/0
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
)
OR EXISTS
(
SELECT
1/0
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
);
This is what I’m talking about, in the plan for this query.
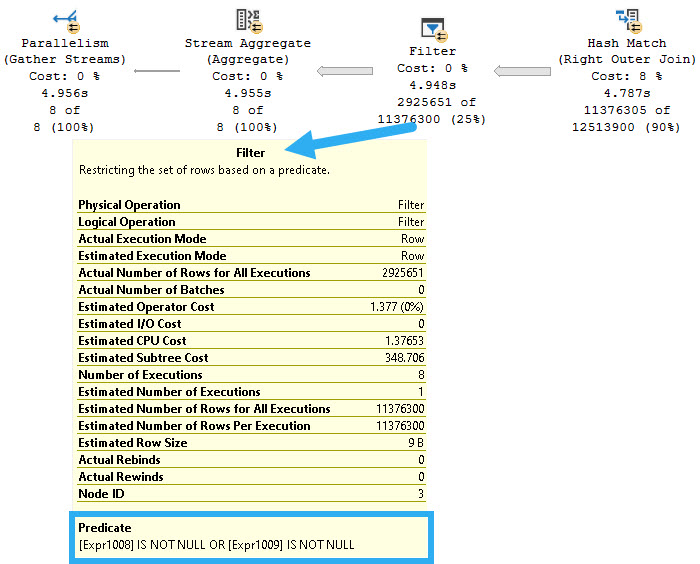
Rather than do two semi joins here for the EXISTS, we get two right outer joins. That means (like in the linked post above), all rows between tables are joined, and filters are applied much later on in the plan. You can see one of the right outer joins, along with the filters (on expressions!) in the nice picture up there.
Fixing It
The fix here, of course (of course!) is to write the query in a way that the optimizer can’t apply that foolishness to.
SELECT
c = SUM(x.c)
FROM
(
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation > 1000000
AND EXISTS
(
SELECT
1/0
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
)
UNION ALL
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
)
) AS x;
This query completes in around 1.5 seconds, compared to 4.9 seconds above.

Seasoned Veteran
It’s rough when you run into these problems, because solutions aren’t always obvious (obvious!), nor is the problem.
Most of the posts I write about query tuning arise from issues I solve for clients. While most performance problems come from predictable places, sometimes you have to deal with edge cases like this, where the optimizer mis-costs things.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- SQL Server 2017 CU 30: The Real Story With SelOnSeqPrj Fixes
- Getting Parameter Values From A SQL Server Query Plan For Performance Tuning
- Getting The Top Value Per Group With Multiple Conditions In SQL Server: Row Number vs. Cross Apply With MAX
- Getting The Top Value Per Group In SQL Server: Row Number vs. Cross Apply Performance
Sorry but the third query and the optimized one not doing the same
There can be users, who have badges and comments as well so they will be calculated twice.
Do you get different results between the two queries?
I think I see what Gabor is saying – there might be something in the stack overflow system restricting putting in users for both comments and badges so the stackoverflow results end up the same between the two queries, but if I repro some data with users having both a badge with high reputation and also comments, a user can be counted twice in the second version of the query (unless I’m misinterpreting something – it is Friday after all! brain is usually fried by Fridays 😀 ):
declare @u table (id int, reputation int)
declare @b table (userid int)
declare @c table (userid int)
insert into @u
values (1, 1000001), (2, 1), (3, 1000001)
insert into @b values (1), (2)
insert into @c values (1), (3)
–userid 1 is only counted once:
SELECT c = COUNT_BIG(*)
FROM @u AS u
WHERE u.Reputation > 1000000
AND EXISTS (SELECT 1/0
FROM @b AS b
WHERE b.UserId = u.Id)
OR EXISTS (SELECT 1/0
FROM @c AS c
WHERE c.UserId = u.Id);
–userid 1 is counted twice:
SELECT c = SUM(x.c)
FROM (SELECT c = COUNT_BIG(*)
FROM @u AS u
WHERE u.Reputation > 1000000
AND EXISTS(SELECT 1/0
FROM @b AS b
WHERE b.UserId = u.Id)
UNION ALL
SELECT c = COUNT_BIG(*)
FROM @u AS u
WHERE EXISTS (SELECT 1/0
FROM @c AS c
WHERE c.UserId = u.Id)) AS x;
Continuing from my repro – if we just add the userid’s to the subqueries and remove the keyword ALL from the UNION, it counts User ID1 properly, but I don’t think the execution plan is probably as good 😀
SELECT sum(x.c) c
FROM (SELECT c = COUNT_BIG(*), u.id
FROM @u AS u
WHERE u.Reputation > 1000000
AND EXISTS(SELECT 1/0
FROM @b AS b
WHERE b.UserId = u.Id)
group by u.id
UNION
SELECT c = COUNT_BIG(*), u.id
FROM @u AS u
WHERE EXISTS(SELECT 1/0
FROM @c AS c
WHERE c.UserId = u.Id)
group by u.id) AS x
Yes, rewrites can work in some places that don’t in others. Because of what I know about this data I know I can do this. Sorry if every blog post can’t explore every possible data set 🤷♂️
In the two non-zero operators from the original query, they had 88% and 22% of the cost. Is that because SQL Server is giving 110%?
Databases are notoriously bad at math.