How Long Must I Stay On This Stuff?
One thing about queues in databases: hey kinda suck. But with a little finesse, there are ways to make them function pretty well.
Before you ask about Service Broker: it’s usually overkill, and unnecessary XML in these scenarios.
When you’re building queues, there are lots of different things to consider.
- Do I want to reuse it?
- Can I just dequeue (delete) items?
- Do I need to process things in any order?
- Is there a “pending” element to the processing?
An example of a pending queue is in sp_AllNightLog, where there’s a list of databases that worker Agent jobs hit to take log backups repeatedly.
Four Queue
Let’s gin up a simple scenario, and say we wanna stick a list of unique Reputations from the Users table into another table, and then have a whole bunch of queries work off of it to do something.
The something in this case is getting a simple count, which is just to be pithy, and probably a bad use of a queue IRL.
Here’s what my ideal table would look like:
CREATE TABLE dbo.four_queue
(
id BIGINT IDENTITY NOT NULL,
in_process BIT NOT NULL DEFAULT 0,
reputation INT NOT NULL,
start_date DATETIME NULL DEFAULT GETDATE(),
end_date DATETIME NULL DEFAULT GETDATE() + 0.00001,
duration_milliseconds AS (DATEDIFF(MILLISECOND, start_date, end_date)),
CONSTRAINT big_idea PRIMARY KEY CLUSTERED(in_process, id),
INDEX fq_uq_r UNIQUE NONCLUSTERED (reputation) WITH(IGNORE_DUP_KEY = ON)
);
A little explanation of the table: this is good for a reusable, ordered queue, that’ll give us some feedback on how long things took. It could also be used if there were a pending element, but we’d probably wanna change the indexing so that we could find either the last start time, or the last end time efficiently.
The thing that probably needs the most explanation here is the indexing and constraints. Because I know you, and you’re staring at the way I have my primary key, and you’re getting an itch and a twitch. That’s okay, you’ve been conditioned for years to put the most selective column first. Unfortunately, that won’t work here.
It’ll make a little more sense in part 2 when we take a closer look at the queries, but the gist of it is that when we’re searching for rows to process (in_process = 0), we want to be able to find them quickly, which is harder to do when it’s the second column in the index and we’re not searching on the id column.
We’ve also got a fun constraint on there to make sure we only have unique values for Reputation, but we’re just going to silently throw away duplicates without throwing an error. This is there just in case someone tries to be sneaky and insert a row on their own to thwart our Perfect Queue Process™
Data Dumping
The cool part about the way the table is set up is that we don’t need to do anything special to get data into it.
INSERT dbo.four_queue ( reputation ) SELECT u.Reputation FROM dbo.Users AS u;
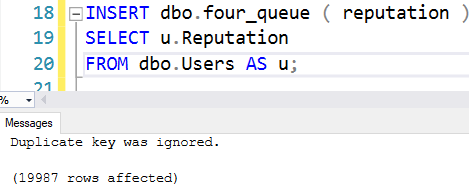
Fair warning here, IGNORE_DUP_KEY does fun stuff to our identity column:
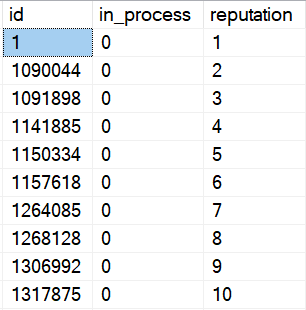
Since the identity doesn’t have any meaning beyond the order that rows were inserted in, it doesn’t matter that it’s not sequential. Order is order, even with gaps.
If you need it to be sequential for some in(s)ane reason, don’t use an identity and use ROW_NUMBER instead.
Totally Tabular
We’ve got a table, and we’ve got data in it.
In Part 2, we’ll look at designing a procedure to work off the queue.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Building Reusable Queues In SQL Server Part 1”
Comments are closed.