Pre-faced
Every post this week is going to be about spills. No crazy in-depth, technical, debugger type stuff.
Just some general observations about when they seem to matter more for performance, and when you might be chasing nothing by fixing them.
The queries I use are sometimes a bit silly looking, but the outcomes are ones I see.
Sometimes I correct them and it’s a good thing. Other times I correct them and nothing changes.
Anyway, all these posts started because of the first demo, which I intended to be a quick post.
Oh well.
Intervention
Spills are a good thing to make note of when you’re tuning a query.
They often show up as a symptom of a bigger problem:
- Parameter sniffing
- Bad cardinality estimates
My goal is generally to fix the larger symptom than to hem and haw over the spill.
It’s also important to keep spills in perspective.
- Some are small and inconsequential
- Some are going to happen no matter what
And some spills… Some spills…
Can’t Hammer This
Pay close attention to these two query plans.
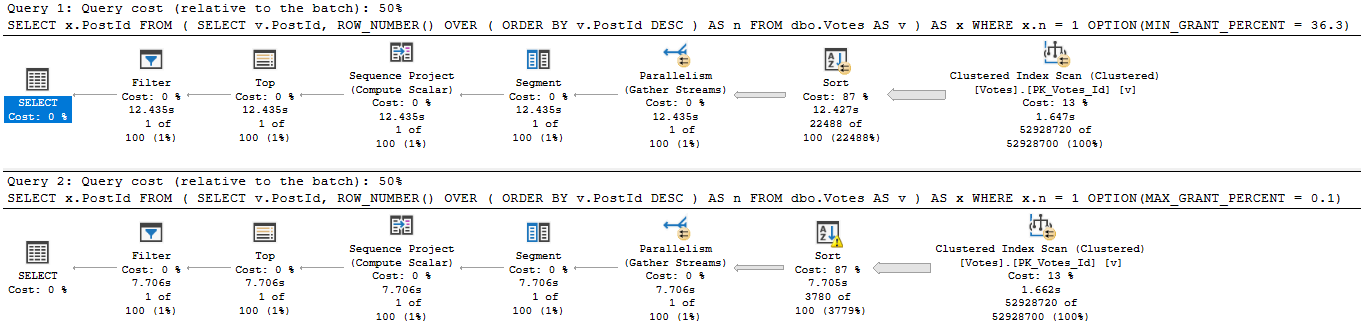
Not sure where to look? Here’s a close up.
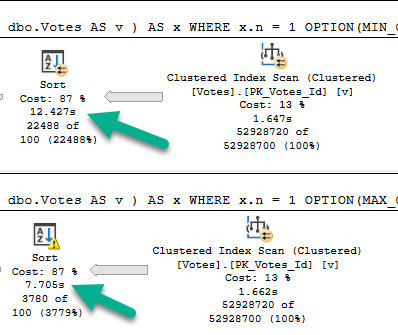
See that, there?
Yeah.
That’s a Sort with a Spill running about 5 seconds faster than a Sort without a Spill.
Wild stuff, huh? Here’s what it looks like.
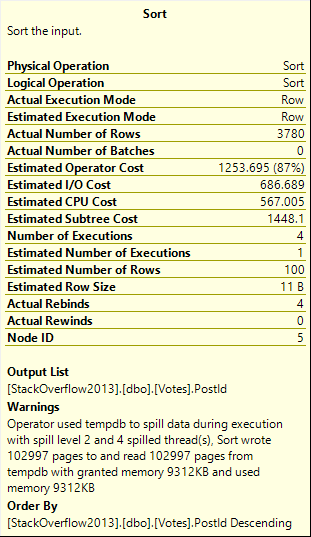
Not inconsequential. >100k 8kb pages.
Spill level 2, too. Four threads.
A note from future Erik: if I run this with the grant capped at 0.0 rather than 0.1, the spill plan takes 12 seconds, just like the non-spill plan.
There are limits to how efficiently a spill can be handled when memory is capped at a level that increases the number of pages spilled without increasing the spill level.
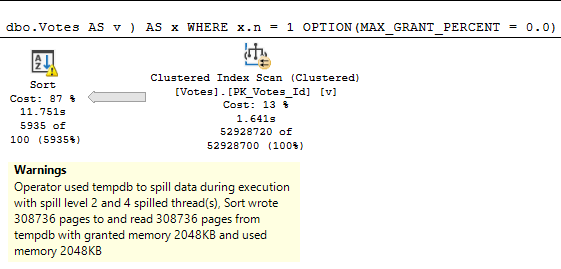
But it’s still funny that the spill and non-spill plans take about the same time.
Why Is This Faster?
Well, the first thing we have to talk about is storage, because that’s where I spilled to.
My Lenovo P52 has some seriously fast SSDs in it. Here’s what they give me, via Crystal Disk Mark:
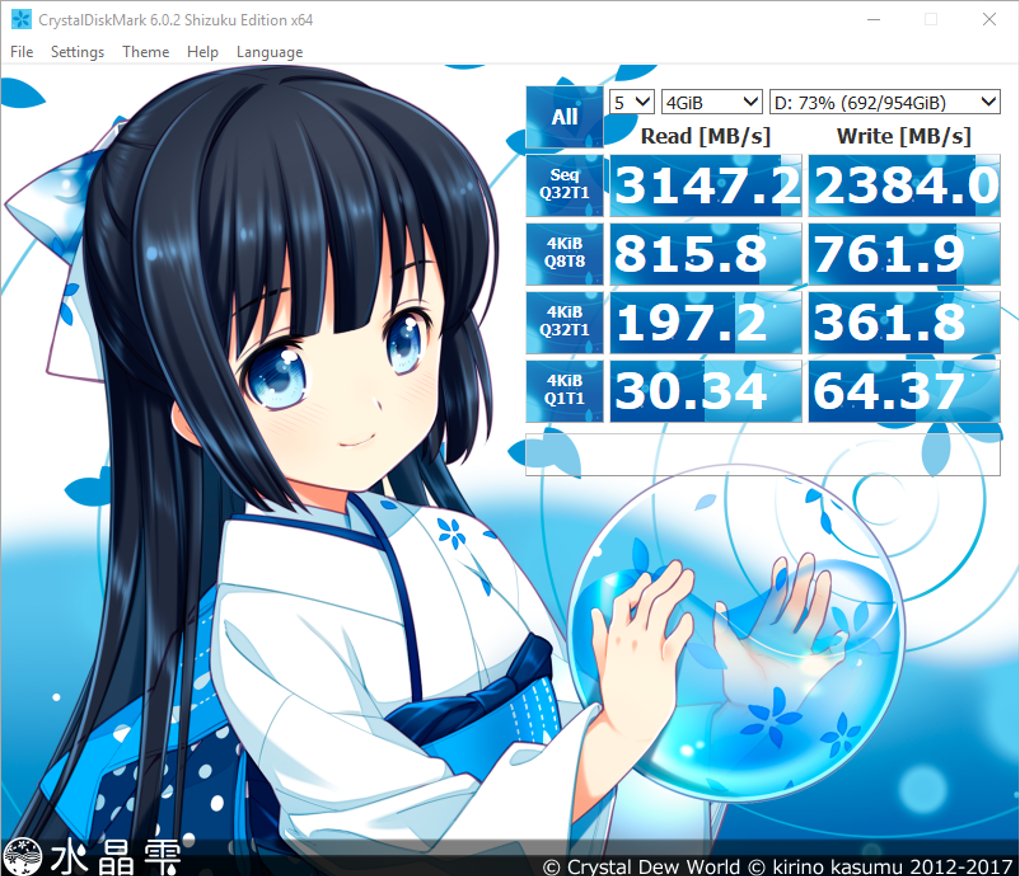
If you’re on good local storage, you might see those speeds.
If you’re on a SAN, I don’t care how much anyone squawks about how fast it is: you’re not gonna see that.
(But seriously, if you do get those speeds on a SAN, tell me about your setup.)
(If you think you should but you don’t, uh… Operators are standing by.)
With that out of the way, let’s hit some reference material.
Kiwis & Machanics
First, Paul White:
Multiple merge passes can be used to work around this. The general idea is to progressively merge small chunks into larger ones, until we can efficiently produce the final sorted output stream. In the example, this might mean merging 40 of the 800 first-pass sorted sets at a time, resulting in 20 larger chunks, which can then be merged again to form the output. With a total of two extra passes over the data, this would be a Level 2 spill, and so on. Luckily, a linear increase in spill level enables an exponential increase in sort size, so deep sort spill levels are rarely necessary.
Next, Paul White showing an Adam Machanic demo:
Well, okay, I’ll paraphrase here. It’s faster to sort a bunch of small things than one big thing.
If you watch the demo, that’s what happens with using the cross apply technique.
And that’s what’s happening here, too, it looks like.
On With It
The spills to (very fast) disk work in my favor here, because we’re sorting smaller data sets, then reading from (very fast) disk more small data sets, and sorting/merging those together for a final finished product.
Of course, this has limits, and is likely unrealistic in many tuning scenarios. I probably should have lead with that, huh?
But hey, if you ever fix a Sort Spill have have a query slow down, now you know why.
In tomorrow’s post, you’ll watch my luck run out (very fast) with different data.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.