Natural Language
In SQL Server’s T-SQL, and in the more general ANSI-Standard SQL, you’re supposed to write queries in a way that mimics how you’d ask the same question — just don’t call it a query — in English. Because of that, there are some ways to phrase a query that are more natural than others.
Some are more intuitive once you get them down, and others can bewitch you for decades. For example, I’m still not always awesome at reasoning out INTERSECT and EXCEPT queries, or even thinking of them first when writing a query where they’d be useful.
Maybe someday.
Dirty Pig Latin
Bad advice exists in many places in the world. I don’t mean to single out the internet, though it certainly has made the publishing and proliferation of bad advice much more accessible.
I do a lot of reading about databases in general, and SQL Server specifically, to see what other folks are out there writing about and teaching others. One of my favorite arrondissements of that world is the stuff that attracts beginners.
After all, that’s when you develop habits, good or bad. Much of this series focuses on the bad habits learned in that time, and how they muck up performance.
One of those bad habits I see over and over again is using LEFT JOINs to find rows that don’t exist. The reason I focus on these is because of the effect they have on query plans, due to the way that queries have to be logically processed.
Let’s look at that, first.
Who’s Not On First?
A quite common looking query for doing this (if you want to do it wrong) would look something like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS U
LEFT JOIN dbo.Comments AS C
ON C.UserId = U.Id
AND C.Score > 0
WHERE C.Id IS NULL;
The important part of the query plan is right around here:

If you’re looking extra closely, without any leading or prompting by me whatsoever, you’ll notice that after the join operation bring the two tables we’re querying togethers — Users and Comments — which is expressed as a left outer join of course, then and only then do we filter out rows where the Id column in Comments is NULL.
The problem is that all this is after the join, and in some scenarios this is far less efficient. Both from the perspective that you have to join many more matching rows together, and from the perspective that the optimizer can sometimes have a weird time ordering outer joins, especially when there are a lot of them.
Note that, for various reasons, this query runs for around 4 seconds total.
Who Doesn’t Exist On First?
An often better way of expressing this sort of query is using the — wait for it — natural expression of the Structured Query Language.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS U
WHERE NOT EXISTS
(
SELECT
1/0
FROM dbo.Comments AS C
WHERE C.UserId = U.Id
AND C.Score > 0
);
This query is logically equivalent to the last one. It may even be arguably better looking. More elegant, as the developers say when they want to describe well-formatted code that no one really understands.
The query plan looks like this now:
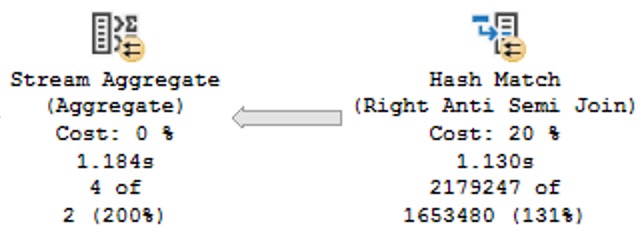
Now we get this crazy little thing called an Anti Semi Join. That means rows are filtered out at the join rather than at some point later on in an explicit Filter operator.
To highlight things a little further, look at the actual number of rows that pass through the filter in the original query and the join in the second query:
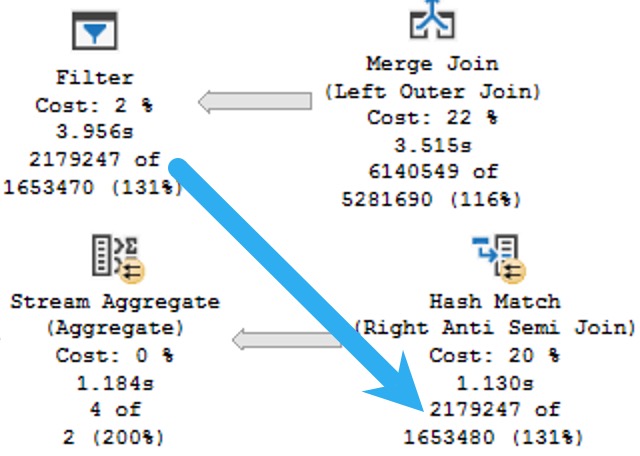
See there? The filter in the LEFT JOIN query reduces he working row set to the same number as the NOT EXISTS query does at the join.
In most cases, you’re better off writing queries this way. It may depend a bit on available indexes, batch mode, and server settings. But writing a blog post that takes every single one of those things into account would likely leave you bored out of your gourd.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One of the things I used to see a lot with novice SQL programmers was to LEFT OUTER JOIN every table:
SELECT DISTINCT
FROM
tab1
LEFT JOIN tab2 ON …
LEFT JOIN …
Normally an indication that they’d got the rows they thought they needed, but they had too many of them, and most of them looked the same, so distinct would tidy up the dataset! (There was a reason we implemented 100% code reviews for SQL).
Ooh yeah, originally I had planned on doing a post on developers abusing distinct for things like this, but it didn’t make the cut. Glad I’m not crazy for noticing it!
Awesome explanation Erik, thanks
You got it! Thanks for reading!