Frangible Tuning
Right now, the optimizer’s costing algorithm’s cost lookups as being pretty expensive.
Why? Because it’s stuck in the 90s, and it thinks that random I/O means mechanical doo-dads hopping about on a spinning platter to fetch data.
And look, I get why changes like this would be really hard. Not only would it represent a change to how costs are estimated, which could throw off a whole lot of things, but you also open potentially more queries up to parameter sniffing issues.
Neither of those prospects are great, but I hear from reliable sources that Microsoft “hope[s] to make parameter sniffing less of a problem for customers” in the future.
In the meantime, what do I mean?
Kiss of Death
Scanning clustered indexes can be painful. Not always, of course, but often enough that it’s certainly something to ask questions about in OLTP-ish queries.
Let’s use the example query from yesterday’s blog post again, with a couple minor changes, and an index.
CREATE INDEX unusable
ON dbo.Posts(OwnerUserId, Score DESC, CreationDate, LastActivityDate)
INCLUDE(PostTypeId);
Let’s run this hyper-realistic query, with slightly different dates in the where clause.
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130927'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130928'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
The query plan for the first query looks like this:
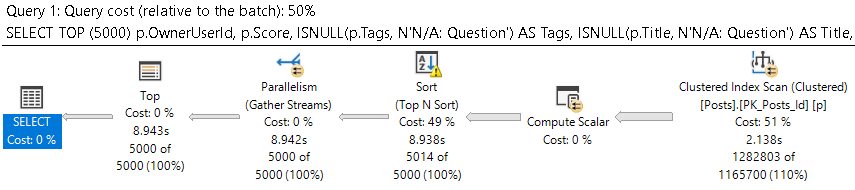
We scan the clustered index, and the query as a whole takes around 9 seconds.
Well, okay.
What about the other query plan?
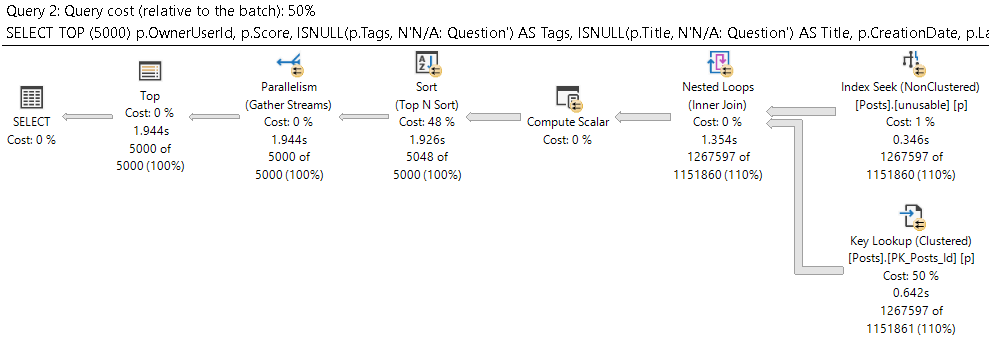
That runs about 7 seconds faster. But why?
Come Clean
There’s one of those ✌tipping points✌ you may have heard about. One day. What a difference, huh?
Let’s back up to the first query.
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130927'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p WITH(INDEX = unusable)
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130927'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
There’s no way one day should make this thing 7 seconds slower, so we’re going to hint one copy of it to the use nonclustered index.
How do we do there?
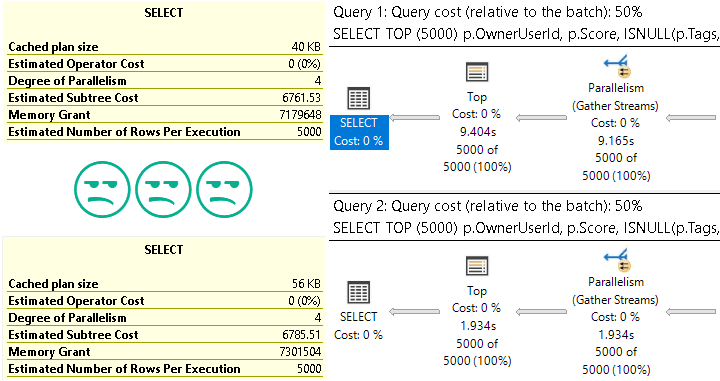
The much slower plan has a lower cost. The optimizer gave the seek + lookup a higher cost than the scan.
If we look at the subtree cost of the first operator, you’ll see what I mean.
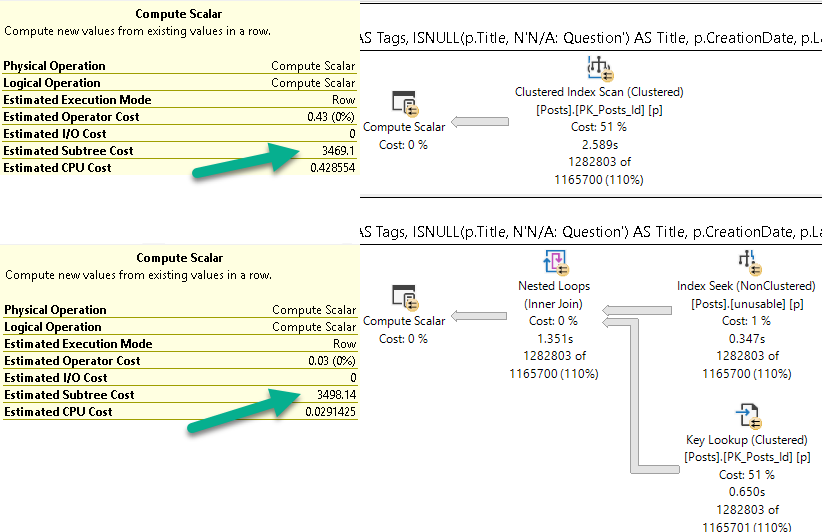
Zone Out
You may hear people talk about costs, either of query plans, or of operators, that indicate what took the most time. This is unfortunately not quite the case.
Note that there are no “actual cost” metrics that get calculated and added to the plan later. The estimates remain with no counterparts.
You can answer some common questions this way:
- Why didn’t my index get chosen? The optimizer thought it’d be more work
- How did it make that choice? Estimated costs of different potential plans
- Why was the optimizer wrong? Because it’s biased against random I/O.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.