Butt Out Bag
There was one thing that I didn’t talk about earlier in the week.
You see, there’s a mystery plan.
It only shows up once in a while, like Planet X. And when it does, we get bombarded by asteroids.
Just like when Planet X shows up.
I wouldn’t call it a good all-around plan, but it does something that we would want to happen when we run this procedure for VoteTypeId 5.
Let’s go look!
The Optimizer Discovers Aggregates, Sort Of
This isn’t a good “general” plan. In fact, for any of the previously fast values, it sucks.
It sucks because just like the “optimize for unknown” plan, it has a bunch of startup costs, does a lot of scanning, and is generally a bad choice for VoteTypeIds that produce a small number of values.
Johnny Four
If you look carefully, you can see what the problem is.
For VoteTypeIds that filter out a lot of rows (which is most of them), that predicate doesn’t get applied until after Posts and Badges have been joined.
In other words, you fully join those tables, and then the result of that join is joined to the predicate-filtered result of Votes.
For this execution, the plan was compiled initially for VoteTypeId 2. It has 130 million entries in Votes. It’s the only VoteTypeId that produces this plan naturally.
The plan you’re looking at above was re-executed with VoteTypeId 4, which has… 8,190 rows in Votes.
I can’t stress enough how difficult it would be to figure out why this is bad just looking at estimated plans.
Though one clue would be the clustered index scan + predicate, if we knew that we had a suitable index.

This kind of detail with row discrepancies only surfaces with actual plans.
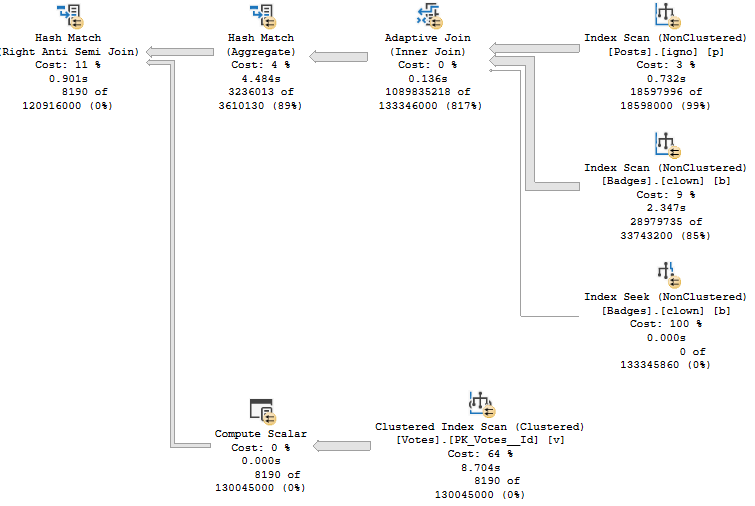
But there is one thing here that wasn’t showing up in other plans, when we wanted it to: The optimizer decides to aggregate OwnerUserId coming from the Posts table prior to joining to Votes.
Johnny Five
If you recall the previously used plan, one complaint was that the result of joining Posts and Badges then joined to Votes had to probe 932 million rows.
You can sort of see that here, where the Adaptive Join prior to the highlighted Hash Match Aggregate produces >100 million rows. It’s more here because we don’t have Bitmaps against both Posts and Badges, but… We’re going off track a bit with that.
That could have been avoided if the optimizer had decided to aggregate OwnerUserId, like it does in this plan.
To compare:
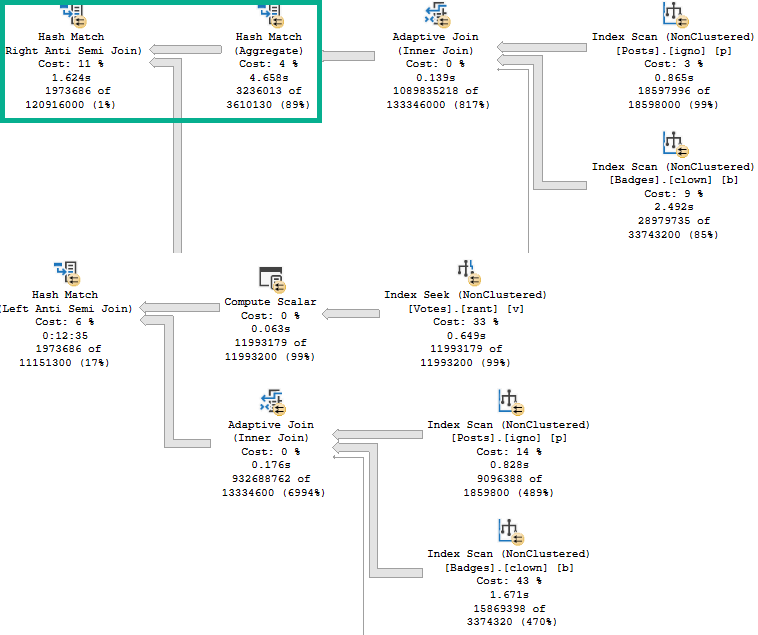
The top plan has a handy green square to show you a helpful pre-join aggregation.
The bottom plan has no handy green squares because there is no helpful pre-join aggregation.
The product of the aggregation is 3.2 million rows, which is exactly what we got as a distinct count when we began experimenting with temp tables:
SELECT COUNT_BIG(DISTINCT p.OwnerUserId) AS records --3,236,013
FROM dbo.Posts AS p
JOIN dbo.Badges AS b
ON b.UserId = p.OwnerUserId
WHERE p.PostTypeId = 1;
Outhouse
If the optimizer had chosen to aggregate OwnerUserId prior to the join to Votes, we all could have gone home early on Friday and enjoyed the weekend
Funny, that.
Speaking of which, it’s Friday. Go enjoy the weekend.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.