Are We Still Friends?
When I first wrote this demo, I called it dbo.ParameterSniffingMonstrosity.
Because , you know, it’s really terrible.
CREATE OR ALTER PROCEDURE dbo.VoteSniffing( @VoteTypeId INT )
AS
SET XACT_ABORT, NOCOUNT ON;
BEGIN
SELECT ISNULL(v.UserId, 0) AS UserId,
SUM(CASE WHEN v.CreationDate >= '20190101'
AND v.CreationDate < '20200101'
THEN 1
ELSE 0
END) AS Votes2019,
SUM(CASE WHEN v.BountyAmount IS NULL
THEN 0
ELSE 1
END) AS TotalBounty,
COUNT(DISTINCT v.PostId) AS PostCount,
@VoteTypeId AS VoteTypeId
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @VoteTypeId
AND NOT EXISTS
(
SELECT 1/0
FROM dbo.Posts AS p
JOIN dbo.Badges AS b
ON b.UserId = p.OwnerUserId
WHERE p.OwnerUserId = v.UserId
AND p.PostTypeId = 1
)
GROUP BY v.UserId;
END;
GO
The only parameter is for VoteTypeId, which has some pretty significant skew towards some types, especially in the full size Stack Overflow database.
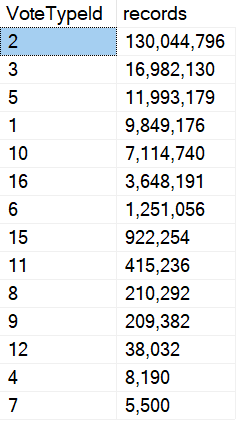
It’s like, when people tell you to index the most selective column first, well.
- Sometimes it’s pretty selective.
- Sometimes it’s not very selective
But this is exactly the type of data that causes parameter sniffing issues.
With almost any data set like this, you can draw a line or three, and values within each block can share a common plan pretty safely.
But crossing those lines, you run into issues where either little plans do far too much looping and seeking and sorting for “big” values, and big plans do far too much hashing and scanning and aggregating for “little” values.
This isn’t always the exact case, but generally speaking you’ll observe something along these lines.
It’s definitely not the case for what we’re going to be looking at this week.
This week is far more interesting.
That’s why it’s a monstrosity.
Fertilizer
The indexes that I create to support this procedure look like so — I’ve started using compression since at this point in time, 2016 SP1 is commonplace enough that even people on Standard Edition can use them — and they work quite well for the majority of values and query plans.
CREATE INDEX igno
ON dbo.Posts
(OwnerUserId, PostTypeId)
WHERE PostTypeId = 1
WITH(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = ROW);
GO
CREATE INDEX rant
ON dbo.Votes
(VoteTypeId, UserId, PostId)
INCLUDE
(BountyAmount, CreationDate)
WITH(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = ROW);
GO
CREATE INDEX clown ON dbo.Badges( UserId )
WITH(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = ROW);
GO
If there are other indexes you’d like to test, you can do that locally.
What I want to point out is that for many values of VoteTypeId, the optimizer comes up with very good, very fast plans.
Good job, optimizer.
In fact, for any of these runs, you’ll get a good enough plan for any of the other values. They share well.
EXEC dbo.VoteSniffing @VoteTypeId = 4; EXEC dbo.VoteSniffing @VoteTypeId = 6; EXEC dbo.VoteSniffing @VoteTypeId = 7; EXEC dbo.VoteSniffing @VoteTypeId = 9; EXEC dbo.VoteSniffing @VoteTypeId = 11; EXEC dbo.VoteSniffing @VoteTypeId = 12; EXEC dbo.VoteSniffing @VoteTypeId = 13; EXEC dbo.VoteSniffing @VoteTypeId = 14; EXEC dbo.VoteSniffing @VoteTypeId = 15; EXEC dbo.VoteSniffing @VoteTypeId = 16;
VoteTypeIds 1, 2, 3, 5, 8, and 10 have some quirks, but even they mostly do okay using one of these plans.
There are two plans you may see occur for these.
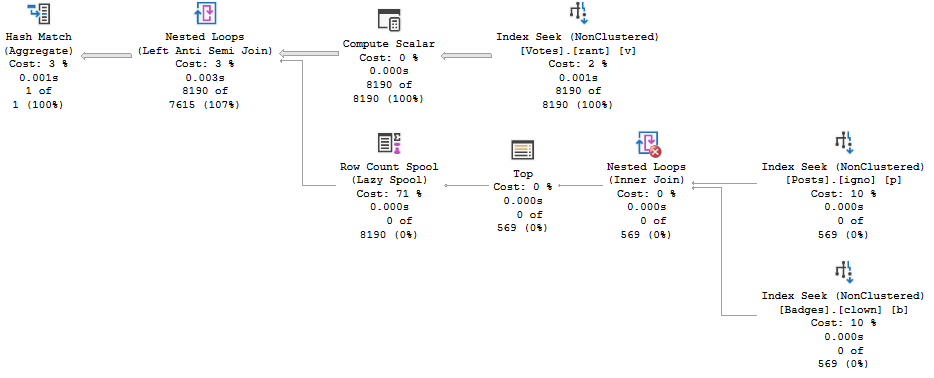
Plan 1
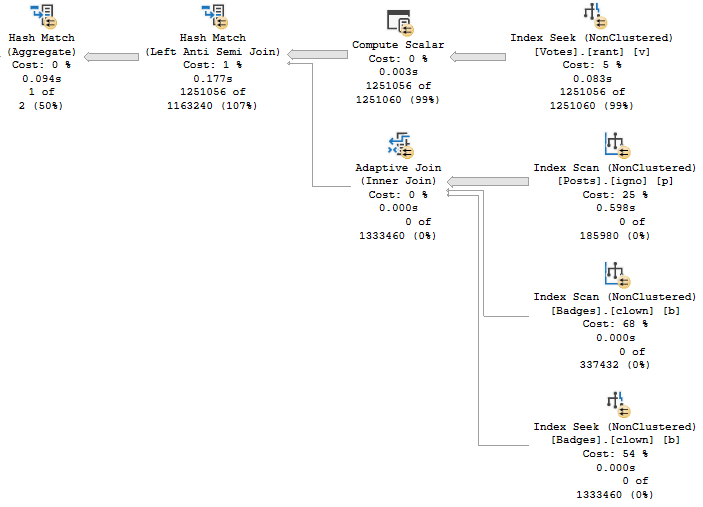
Plan 2
Particulars & Peculiars
Plan 1 is first generated when the procedure is compiled with VoteTypeId 4, and Plan 2 is first generated when the procedure is compiled with VoteTypeId 6.
There’s a third plan that only gets generated when VoteTypeId 2 is compiled first, but we’ll have to save that for another post, because it’s totally different.
Here’s how each of those plans works across other possible parameters.
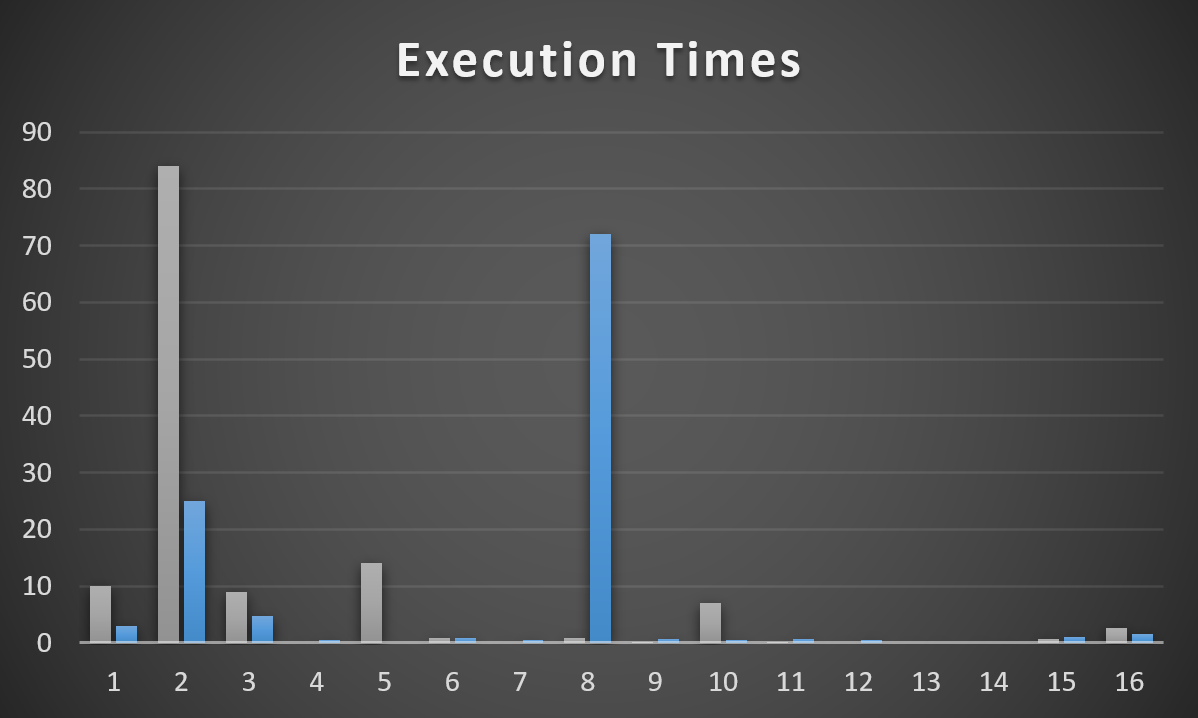
Plan 1 is grey, Plan 2 is blue. It’s pretty easy to see where each one is successful, and then not so much. Anything < 100ms got a 0.
The Y axis is runtime in seconds. A couple are quite bad. Most are decent to okay.
Plans for Type 2 & 8 obviously stick out, but for different plans.
This is one of those things I need to warn people about when they get wrapped up in:
- Forcing a plan (e.g. via Query Store or a plan guide)
- Optimizing for unknown
- Optimizing for a specific value
- Recompiling every time (that backfires in a couple cases here that I’m not covering right now)
One thing I need to point out is that Plan 2 doesn’t have an entry here for VoteTypeId 5. Why?
Because when it inherits the plan for VoteTypeId 6, it runs for 17 minutes.
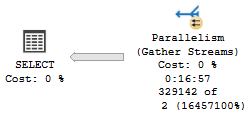
This is probably where you’re wondering “okay, so what plan does 5 get when it runs on its own? Is this the mysterious Plan 4 From Outer Space?”
Unfortunately, the plan that gets generated for VoteTypeId 5 is… the same one that gets generated for VoteTypeId 6, but 6 has a much smaller memory grant.
If you’re not used to reading operator times in execution plans, check out my video here.
Since this plan is all Batch Mode operators, each operator will track its time individually.
The Non-Switch
VoteTypeId 5 runtime, VoteTypeId 6 compile time
If I were to put a 17 minute runtime in the graph (>1000 seconds), it would defeat the purpose of graphing things.
Note the Hash Match has, by itself, 16 minutes and 44 seconds of runtime.
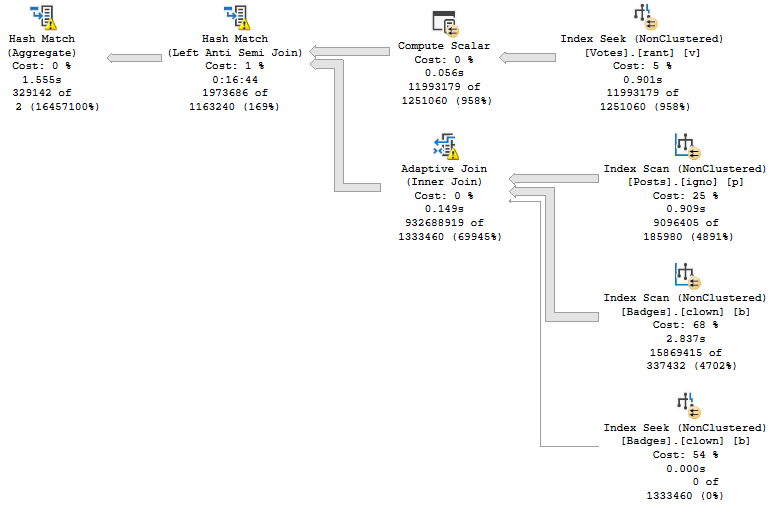
VoteTypeId 5 runtime, and compile time
This isn’t awesome, either.
The Hash Join, without spilling, has 12 minutes and 16 seconds of runtime.
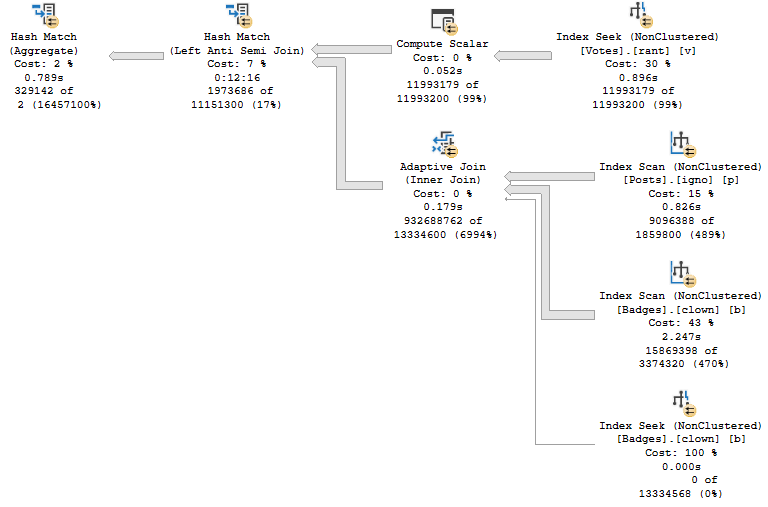
Big Differentsiz
You have the same plan shape and operators. Even the Adaptive Join follows the same path to hash instead of loop.
Sure, the spills account for ~4 minutes of extra time. They are fairly big spills.
But the plan for VoteTypeId 5, even when compiled specifically for VoteTypeId 5… sucks, and sucks royally.
There are some dismally bad estimates, but where do they come from?
We just created these indexes, and data isn’t magically changing on my laptop.
TUNE IN TOMORROW!
Thanks for reading
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Commas! You threw those results into Excel, didn’t you?
I use the magic of the FORMAT function.
I use FORMAT to do the same, but discovered when trying to apply the format to the number zero, it returns an empty string instead of 0. I’ve had to use stuff like this:
SELECT @OutputMessage
= CASE
WHEN @TotalToDelete = 0 THEN /* FORMAT returns empty string for 0 for some reason */
‘{‘ + CONVERT(VARCHAR(20), CURRENT_TIMESTAMP, 120) + ‘} Found 0 records to delete.’
ELSE
‘{‘ + CONVERT(VARCHAR(20), CURRENT_TIMESTAMP, 120) + ‘} Found ‘
+ FORMAT(@TotalToDelete, ‘###,###,###,###’) + ‘ records to delete.’
END;
SELECT FORMAT(0, ‘N0’)