Loose Ends
A while back I promised I’d write about what allows SQL Server to perform two seeks rather than a seek with a residual predicate.
More recently, a post touched a bit on predicate selectivity in index design, and how missing index requests don’t factor that in when requesting indexes.
This post should tie the two together a bit. Maybe. Hopefully. We’ll see where it goes, eh?
If you want a TL;DR, it’s that neighboring index key columns support seeks quite easily, and that choosing the leading column should likely be a reflection of which is filtered on most frequently.
If you want more specific advice, I’d be happy to give it to you.
Index Management
Let’s get real wacky and create two indexes.
CREATE NONCLUSTERED INDEX whatever
ON dbo.Posts ( PostTypeId, ClosedDate );
CREATE NONCLUSTERED INDEX apathy
ON dbo.Posts ( ClosedDate, PostTypeId );
Now let’s run two identical queries, and have each one hit one of those indexes.
SELECT p.Id, p.PostTypeId, p.ClosedDate FROM dbo.Posts AS p WITH (INDEX = whatever) WHERE p.PostTypeId = 1 AND p.ClosedDate >= '2018-06-01'; SELECT p.Id, p.PostTypeId, p.ClosedDate FROM dbo.Posts AS p WITH (INDEX = apathy) WHERE p.PostTypeId = 1 AND p.ClosedDate >= '2018-06-01';
If you run them a bunch of times, the first query tends to end up around ~50ms ahead of the second, though they both sport nearly identical query plans.
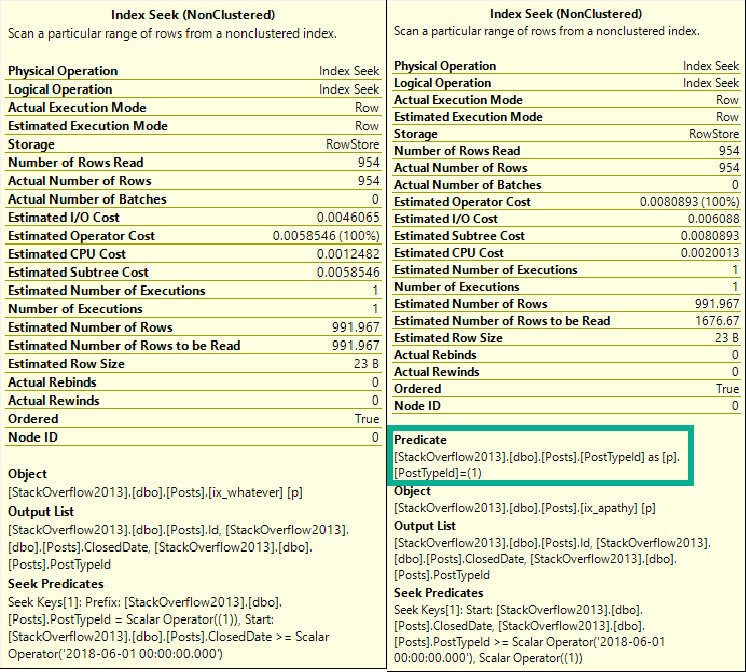
The seek may look confusing, because PostTypeId seems to appear as both a seek and a residual predicate. That’s because it’s sort of both.
The seek tells us where we start reading, which means we’ll find rows starting with ClosedDate 2018-06-01, and with PostTypeId 1.
From there, we may find higher PostTypeIds, which is why we have a residual predicate; to filter those out.
More generally, a seek can find a single row, or a range of rows as long as they’re all together. When the leading column of an index is used to find a range, we can seek to a starting point, but we need a residual predicate to check for other predicates afterwards.
This is why the index rule of thumb for many people is to start indexes with equality predicates. Any rows located will be contiguous, and we can easily continue the seek while applying any other predicates.
There’s also differences in stats time and IO.
Table 'Posts'. Scan count 1, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 156 ms. Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 106 ms.
Remember that this is how things break down for each predicate:
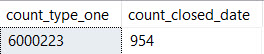
But in neither case do we need to touch all ~6mm rows of PostTypeId 1 to locate the correct range of ClosedDates.
Downstairs Mixup
When does that change?
When we design indexes a little bit more differenter.
CREATE NONCLUSTERED INDEX ennui
ON dbo.Posts ( PostTypeId ) INCLUDE (ClosedDate);
CREATE NONCLUSTERED INDEX morose
ON dbo.Posts ( ClosedDate ) INCLUDE (PostTypeId);
Running the exact same queries, something changes quite drastically for the first one.
Table 'Posts'. Scan count 1, logical reads 16344, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 297 ms, elapsed time = 301 ms. Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 187 ms.
This time, the residual predicate hurts us, when we look for a range of values.
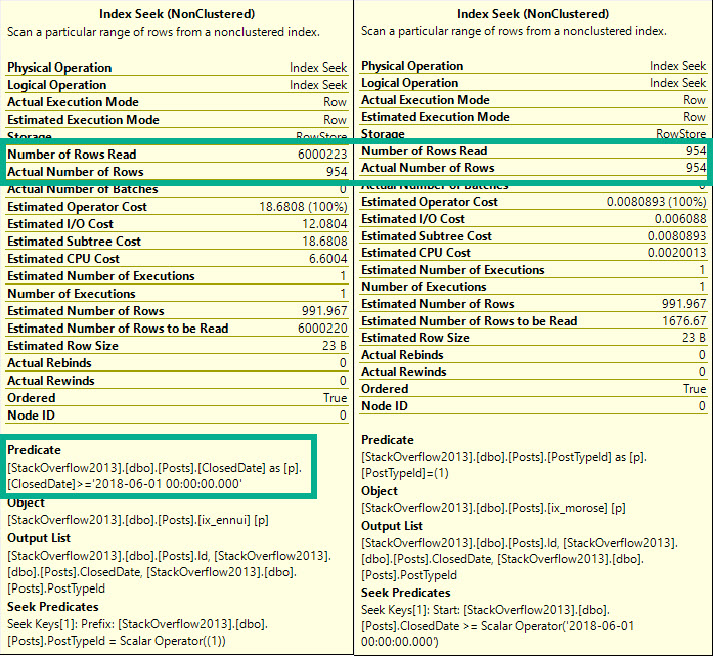
We do quite a lot of extra reads — in fact, this time we do need to touch all ~6mm rows of PostTypeId 1.
Off By One
Something similar happens if we only rearrange key columns, too.
CREATE NONCLUSTERED INDEX ennui
ON dbo.Posts ( PostTypeId, OwnerUserId, ClosedDate ) WITH ( DROP_EXISTING = ON );
CREATE NONCLUSTERED INDEX morose
ON dbo.Posts ( ClosedDate, OwnerUserId, PostTypeId ) WITH ( DROP_EXISTING = ON );
I have both columns I’m querying in the key of the index this time, but I’ve stuck a column I’m not querying at all between them — OwnerUserId.
This also throws off the range predicate. We read ~30k more pages here because the index is larger.
Table 'Posts'. Scan count 1, logical reads 19375, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 312 ms, elapsed time = 314 ms. Table 'Posts'. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 178 ms.
The Seeks here look identical to the ones when I had columns in the include section of the index.
What’s It All Mean?
Index column placement, whether it’s in the key or in the includes, can have a non-subtle impact on reads, especially when we’re searching for ranges.
Even when we have a non-selective leading column like PostTypeId with an equality predicate on it, we don’t need to read every single row that meets the filter to apply a range predicate, as long as that predicate is seek-able.
When we move the range column to the includes, or we add a column before it in the key, we end up doing a lot more work to locate rows.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Predicate Selectivity And SQL Server Index Design”
Comments are closed.