This Is Not A Solution
Right off the bat, I want you to know that this is not a solution, and I’ll get to why in a minute. I’m writing this mainly because every once in a while I’ll try something different to get this working, and it always ends up disappointing.
I wish I had better news for you, here. Hell, I wish I had better news for me here. But alas we’re at the mercy of parameters.
And yeah, I know, recompile, recompile, recompile. All the live long day. But I’ve seen some weird stuff happen with that too under high concurrency.
So what’s the point? Let’s talk about that.
Dot Dot Dot
CREATE INDEX p1 ON dbo.Posts(OwnerUserId, CreationDate); CREATE INDEX p2 ON dbo.Posts(Score, LastActivityDate);
We need some indexes. That’s a fact. I’m intentionally creating them in this way to show you that SQL Server can sometimes be smart about catch all queries.
And here’s the inline table valued function we’ll be working with:
CREATE OR ALTER FUNCTION
dbo.kitchen_sink
(
@OwnerUserId int,
@CreationDate datetime,
@Score int,
@LastActivityDate datetime
)
RETURNS table
AS
RETURN
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE
(p.OwnerUserId = @OwnerUserId OR @OwnerUserId IS NULL)
AND (p.CreationDate >= @CreationDate OR @CreationDate IS NULL)
AND (p.Score >= @Score OR @Score IS NULL)
AND (p.LastActivityDate >= @LastActivityDate OR @LastActivityDate IS NULL);
This pattern usually eats the optimizer alive, and there’s a lot of posts about using dynamic SQL to fix it.
But when we call this function with literal values, it does just fine.
SELECT
ks.c
FROM dbo.kitchen_sink(22656, '20130101', NULL, NULL) AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(NULL, NULL, 100, '20130101') AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(22656, NULL, NULL, '20130101') AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(NULL, '20131225', NULL, '20131225') AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(22656, NULL, NULL, '20131215') AS ks;
Das Plan
You can run those all yourself and look at the plans. I’m just gonna throw a couple of the more interesting examples in the post, though.
The first two queries do exactly what we’d hope to see.
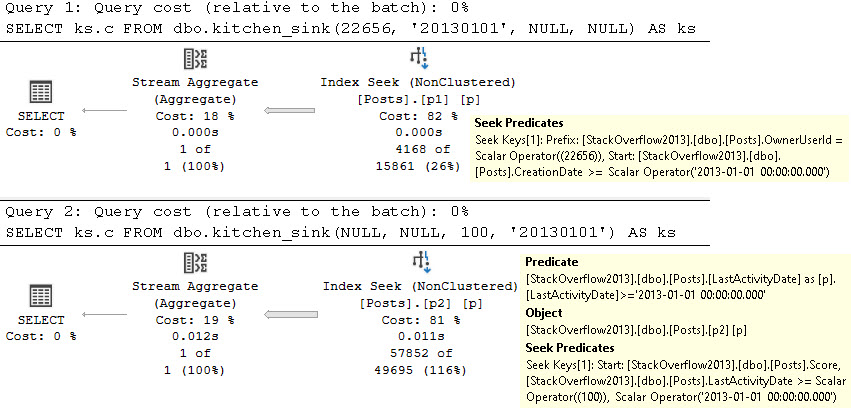
We use the right indexes, we get seeks. Cardinality estimation is about as reliable as ever with the “””””default””””” estimator in place 🙄
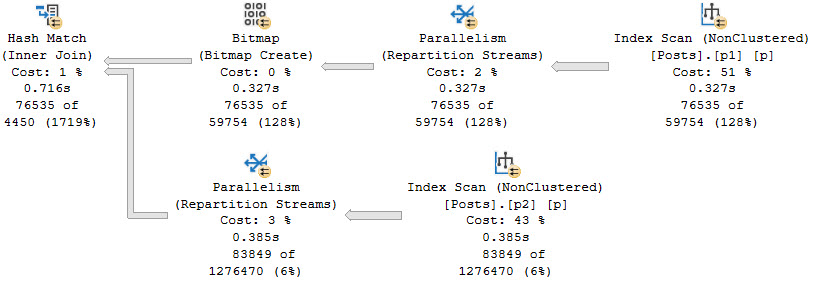
And at one point, we even get a really smart index intersection plan where the optimizer uses both of our nonclustered indexes.
Parameter Problem
The problem is that no one really makes database calls like that.
If you’re using an ORM, you could intentionally not parameterize your queries and get this to “work”, but there are downsides to that around the plan cache. Being honest, most plan caches are useless anyway.
Long Live Query Store, or something.
Most people have their catch all code parameterized, so the query looks like what’s in the function. I’m going to throw the function in a stored procedure now.
CREATE OR ALTER PROCEDURE
dbo.kitchen_wrapper
(
@OwnerUserId int,
@CreationDate datetime,
@Score int,
@LastActivityDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
ks.c
FROM dbo.kitchen_sink
(
@OwnerUserId,
@CreationDate,
@Score,
@LastActivityDate
) AS ks;
END;
If we execute the procedure like this, everything goes to hell rather quickly.
EXEC dbo.kitchen_wrapper
@OwnerUserId = 22656,
@CreationDate = '20131215',
@Score = NULL,
@LastActivityDate = NULL;
EXEC dbo.kitchen_wrapper
@OwnerUserId = NULL,
@CreationDate = NULL,
@Score = 100,
@LastActivityDate = '20131215';
Baywatch
The first execution uses the “right” index, but we lose our nice index seek into the p1 index.
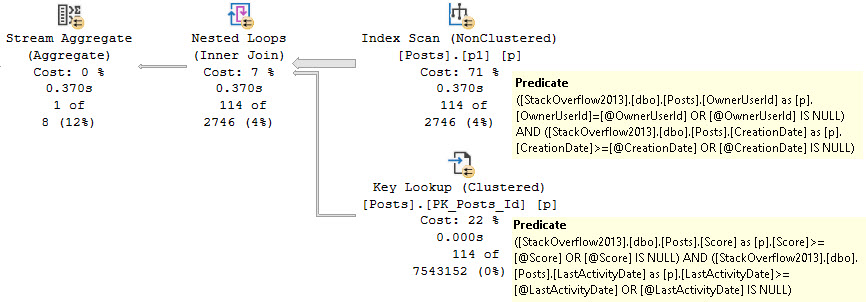
We also end up with Predicates on the Key Lookup, just in case they end up not being NULL. And boy, when they end up not being NULL, we end up with a really slow query.
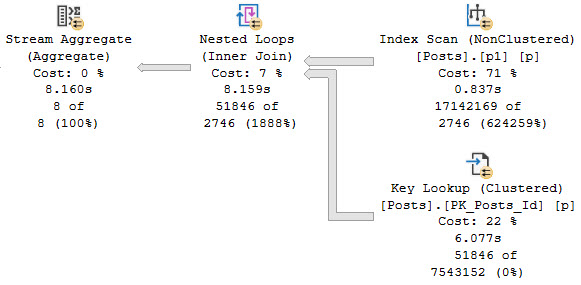
We re-use the execution plan we saw before, because that’s how SQL Server works. But since we don’t filter any rows from p1 since those parameters are NULL now, we pass all 17 million rows to the key lookup to filter them there, but since it’s a Nested Loops Join, we do it… one row at a time.
Fun.
Floss Too Much
There’s no great fix for this, either. This is a problem we’re stuck with when we write queries this way without using dynamic SQL, or a recompile hint.
I’ve seen people try all sorts of things to “fix” this problem. Case expressions, ISNULL and COALESCE, magic values, and more. They all have this exact same issue.
And I know, recompile, recompile, recompile.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
just a very short edge case. when you have two params (@a1, @a2), (p.a1 = @a1 OR @a1 IS NULL) AND (p.a2 >= @a2 OR @a2 IS NULL), you can rewrite it using UNION ALL (assuming the rows returned do not have duplicates). again, just an edge case, but it’s worth mentioning.