Lead Up
I have a couple posts scheduled next week about aggregates, so now is a good time to continue my series on how you, my dear, sweet, developers, can use indexes in various ways to fix performance issues.
In this one, we’re going to get into a weird cross-section, because I run into a lot of developers who think that modularizing abstracting queries away in various things is somehow better for performance.
It’ll happen with functions a lot where I’ll hear that, but by far, it is more common to hear this about views.
Everything from results getting cached or materialized to metadata lookups being faster has been thrown at me in their defense.
By far the strangest was someone telling me that SQL Server creates views automatically for frequently used queries.
Hearts were blessed that day.
A Query!
So, here’s where indexed views are tough: THERE ARE SO MANY RESTRICTIONS ON THEM IT’S ABSURD.
They are borderline unusable. Seriously, read through the list of “things you can’t do” I linked to up there, and note the utter scarcity of “possible workarounds”.
How a $200 billion dollar a year company has an indexed view feature that doesn’t support MIN, MAX, AVG, subqueries (including EXISTS and NOT EXISTS), windowing functions, UNION, UNION ALL, EXCEPT, INTERSECT, or HAVING in the year 2024 is beyond me, and things like this are why many newer databases will continue to eat SQL Server’s lunch, and many existing databases (Oracle, Postgres) which have much richer features available for indexed (materialized) views point and laugh at us.
Anyway, here’s the query.
SELECT
u.Id,
u.DisplayName,
QuestionUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
QuestionDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
AnswerAcceptedScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 1 THEN 1 ELSE 0 END)),
AnswerUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
AnswerDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
CommentScore =
SUM(CONVERT(bigint, c.Score))
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
JOIN dbo.Votes AS v
ON v.PostId = p.Id
WHERE u.Reputation > 500000
AND p.Score > 0
AND c.Score > 0
AND p.PostTypeId IN (1, 2)
AND v.VoteTypeId IN (1, 2, 3)
GROUP BY
u.Id,
u.DisplayName;
It just barely qualifies for indexed view-ness, but only if I add a COUNT_BIG(*) to the select list.
Now, here’s the thing, currently. We gotta look at a query plan first. Because it’s going to drive a lot of what I tell you later in the post.
A Query Plan!
Right now when I execute this query, I get a nice, happy, Batch Mode on Row Store query plan.
It’s not the fastest, which is why I still want to create an indexed view. But stick with me. It runs for about a minute:
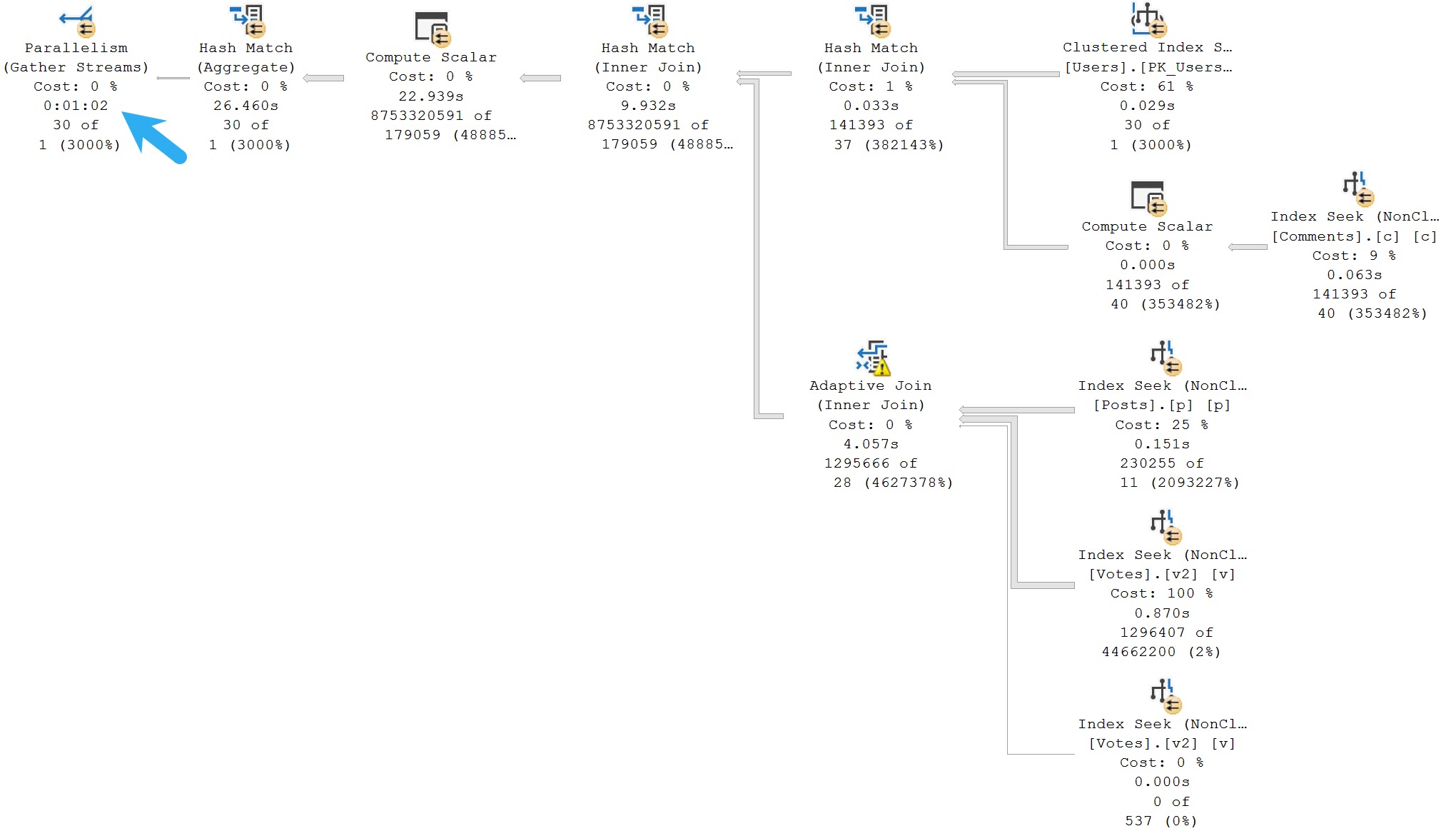
What’s particularly interesting is a Batch Mode Compute Scalar operator running for 22 seconds on its own. Fascinating.
Okay, but the important thing here: It takes one minute to run this query.
In Batch Mode.
An Indexed View Definition!
Let’s take a stab at creating an indexed view out of this thing, named after the Republica song that was playing at the time.
CREATE OR ALTER VIEW
dbo.ReadyToGo
WITH SCHEMABINDING
AS
SELECT
u.Id,
u.DisplayName,
QuestionUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
QuestionDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 1 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
AnswerAcceptedScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 1 THEN 1 ELSE 0 END)),
AnswerUpScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 2 THEN 1 ELSE 0 END)),
AnswerDownScore =
SUM(CONVERT(bigint, CASE WHEN p.PostTypeId = 2 AND v.VoteTypeId = 3 THEN -1 ELSE 0 END)),
CommentScore =
SUM(CONVERT(bigint, c.Score)),
WellOkayThen =
COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
JOIN dbo.Votes AS v
ON v.PostId = p.Id
WHERE u.Reputation > 500000
AND p.Score > 0
AND c.Score > 0
AND p.PostTypeId IN (1, 2)
AND v.VoteTypeId IN (1, 2, 3)
GROUP BY
u.Id,
u.DisplayName;
GO
CREATE UNIQUE CLUSTERED INDEX
RTG
ON dbo.ReadyToGo
(Id)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
This will create successfully but…
An Indexed View Creation Query Plan!
Indexed views can’t be created using Batch Mode. They must be created in Row Mode.
This one takes two hours, almost.

Yes, please do spend an hour and twenty minutes in a a Nested Loops Join. That’s just what I wanted.
Didn’t have anything else to do with my day.
Of course, with that in place, the query finishes instantly, so that’s nice.
Perils!
So yeah, probably not great that creating the indexed view takes that long. Imagine what that will do to any queries that modify the base data in these tables.
Hellish. And all that to produce a 30 row indexed view. Boy to the Howdy.
This is a bit of a cautionary tale about creating indexed views that span multiple tables. It is probably not the greatest idea, because maintaining them becomes difficult as data is inserted, updated, or deleted. I’m leaving the M(erge) word out of this, because screw that thing anyway.
If we, and by we I mean me, wanted to be smarter about this, we would have taken a better look at the query and taken stock of a couple things and considered some different options.
- Maybe the Comments aggregation should be in its own indexed view
- Maybe the Posts aggregation should be in its own indexed view (optionally joined to Votes)
- Maybe the Comments and Posts aggregations being done in a single indexed view would have been good enough
Of course, doing any of those things differently would change our query a bit. Right now, we’re using PostTypeId to identify questions and answers, but it’s not in the select list otherwise. We’d need to add that, and group by it, too, and we still need to join to Votes to get the VoteTypeId, so we know if something was an upvote, downvote, or answer acceptance.
We could also just live with a query taking a minute to run. If you’re going to sally forth with indexed views, consider what you’re asking them to do, and what you’re asking SQL Server to maintain when you add them across more than one table.
They can be quite powerful tools, but they’re incredibly limited, and creating them is not always fast or straightforward.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
“How a $200 billion dollar a year company…”
This is the same fallacious argument that people trot out when some study comes out about cockroach butts or whatever and they say “but scientists still haven’t cured cancer”. Which is to say that it turns out that any sufficiently large (lower case e) enterprise will probably be working on more than one thing at a time and necessarily won’t marshal all of their resources behind one initiative.
All that said, I also agree that most of the restrictions that exists in indexed/materialized views in mssql are the pits. I wouldn’t say that the feature is abandoned like a lot of other v1 features. But I don’t think it’s gotten a lot of love over the years either.
It’s not fallacious, it’s putting the issue into perspective. Curing cancer is hard. Supporting min and max in an indexed view requires an additional index.
Thank you for the post.
I had this discussion a bunch of times and even had to create an index view just to prove that it wouldn’t solve the issue we were having. My team mates had some experience with Oracle and wanted to apply the same logic in MS SQL. The end result was that it started to take longer to show results due to the rebuilding of the index view – I can only use this in very specific and tested scenarios.