Making Change
SQL Server’s missing index requests (and, by extension, automatic index management) are about 70/30 when it comes to being useful, and useful is the low number.
The number of times I’ve seen missing indexes implemented to little or no effect, or worse, disastrous effect… is about 70% of all the missing index requests I’ve seen implemented.
If they’re all you have to go on, be prepared to drop or disable them after reviewing server and index usage metrics.
Here’s what you’re way better off doing:
- Find your slowest queries
- See if there’s a missing index request
- Run them, and get the actual execution plan
- Look at operator times in the execution plan
- Ask yourself if the index would benefit the slowest parts
Or, you can hire me to do all that. I don’t mind. Even the Maytag Man has an alarm clock.
Poor Performer
Let’s start with a query, and just the base tables with no nonclustered indexes added. Each table still has a clustered primary key on its Id column.
Initially, I thought showing the query plan in Row Mode over Batch Mode would make issues more clear, but row mode operator times are a real disaster.

They’re supposed to be cumulative going from right to left, but here we go from 9 to 4 to 10 to 27 to 22 to 41 to 32. Forget that. Batch Mode it is.
Anyway, here’s the query.
SELECT
u.Id,
u.DisplayName,
TopQuestionScore =
MAX(CASE WHEN p.PostTypeId = 1 THEN p.Score ELSE 0 END),
TopAnswerScore =
MAX(CASE WHEN p.PostTypeId = 2 THEN p.Score ELSE 0 END),
TopCommentScore =
MAX(c.Score),
TotalPosts =
COUNT_BIG(DISTINCT p.Id),
TotalComments =
COUNT_BIG(DISTINCT c.Id)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
JOIN dbo.Comments AS c
ON u.Id = c.UserId
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
AND v.VoteTypeId IN (1, 2, 3)
)
AND u.Reputation > 10000
AND p.Score > 10
AND c.Score > 0
GROUP BY
u.Id,
u.DisplayName
ORDER BY
TotalPosts DESC;
The goal is to get… Well, pretty much what the column names describe. A good column name goes a long way.
If you had free and unfettered access to these tables, what row store indexes would your druthers lead you to?
I’m limiting your imagination to row store here, because that’s what the missing index requests are limited to.
Underwhelm
The optimizer has decided two indexes, on the same table, would really help us out. There are two very clunky ways to see them both.
You can always see the first one in green text at the top of your query plan, when a missing index request exists.
You can look in the plan XML:
<MissingIndexes>
<MissingIndexGroup Impact="20.3075">
<MissingIndex Database="[StackOverflow2013]" Schema="[dbo]" Table="[Comments]">
<ColumnGroup Usage="INEQUALITY">
<Column Name="[Score]" ColumnId="4" />
</ColumnGroup>
<ColumnGroup Usage="INCLUDE">
<Column Name="[UserId]" ColumnId="6" />
</ColumnGroup>
</MissingIndex>
</MissingIndexGroup>
<MissingIndexGroup Impact="20.7636">
<MissingIndex Database="[StackOverflow2013]" Schema="[dbo]" Table="[Comments]">
<ColumnGroup Usage="EQUALITY">
<Column Name="[UserId]" ColumnId="6" />
</ColumnGroup>
<ColumnGroup Usage="INEQUALITY">
<Column Name="[Score]" ColumnId="4" />
</ColumnGroup>
</MissingIndex>
</MissingIndexGroup>
</MissingIndexes>
Or you can expand 75,000 nodes in SSMS:
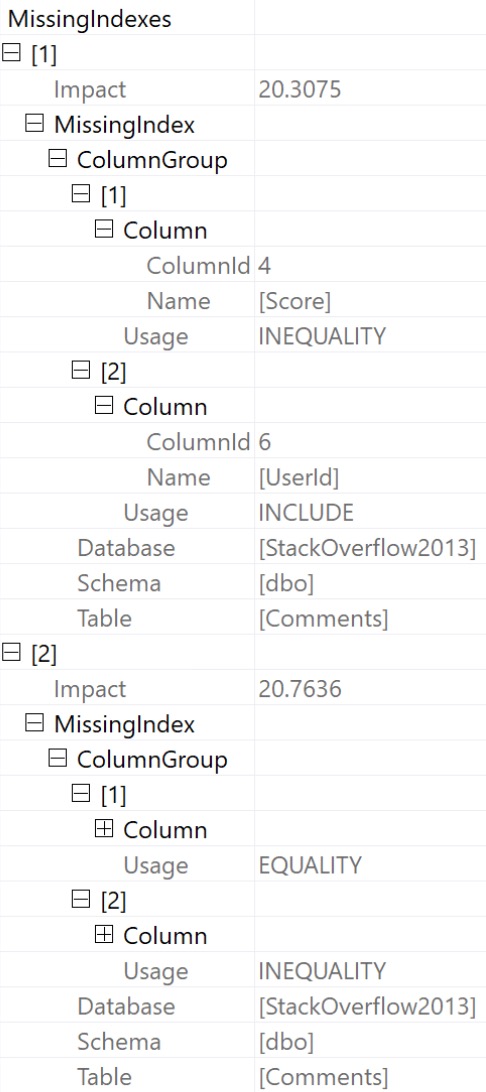
If you prefer something human readable, this is what they would translate to, with a little bit of hot sauce courtesy of yours truly.
CREATE INDEX
c
ON dbo.Comments
(Score)
INCLUDE
(UserId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
c2
ON dbo.Comments
(UserId, Score)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Big Reveal
With all that in mind, let’s look at the query plan before adding the indexes. We’re going to skip ahead a little bit in the bullet points above, to the last two:
- Look at operator times in the execution plan
- Ask yourself if the index would benefit the slowest parts
Here’s the plan, which takes ~10 seconds in total. The arrow is pointing at where the optimizer thinks a new index will help the most.
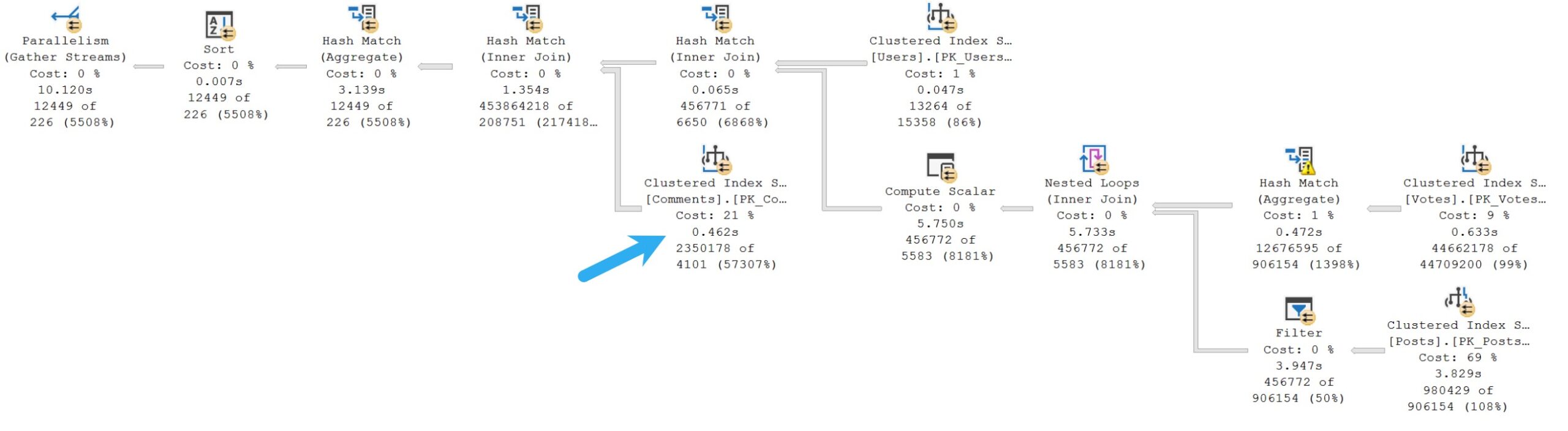
Since the operators in this plan are mostly in Batch Mode, every operator is showing CPU time just for itself.
The exceptions are the Nested Loops join operator, which doesn’t currently have a Batch Mode implementation, despite Microsoft’s consistently shabby Cumulative Update notes saying they cause deadlocks, the scan and filter on the inner side of the Nested Loops join operator, and the compute scalar immediately following the Nested Loops join operator.
That entire portion of the plan is responsible for about half of the total execution time, but there’s no index recommendation there.
And look, I get it, missing index requests happen prior to query execution, while index matching is happening. The optimizer has no idea what might actually take a long time.
But if we’re looking at the only pre-execution metrics the optimizer has, you’d think the estimated costs alone would push it to ask for an index on the Posts table.
Perhaps missing index requests should be selected after query execution. After all, that’s when the engine knows how long everything actually took.
Generous Soul
Okay, so those two indexes on the Comments table up there? I added both of them.
The query plan changes, but it doesn’t get any faster.
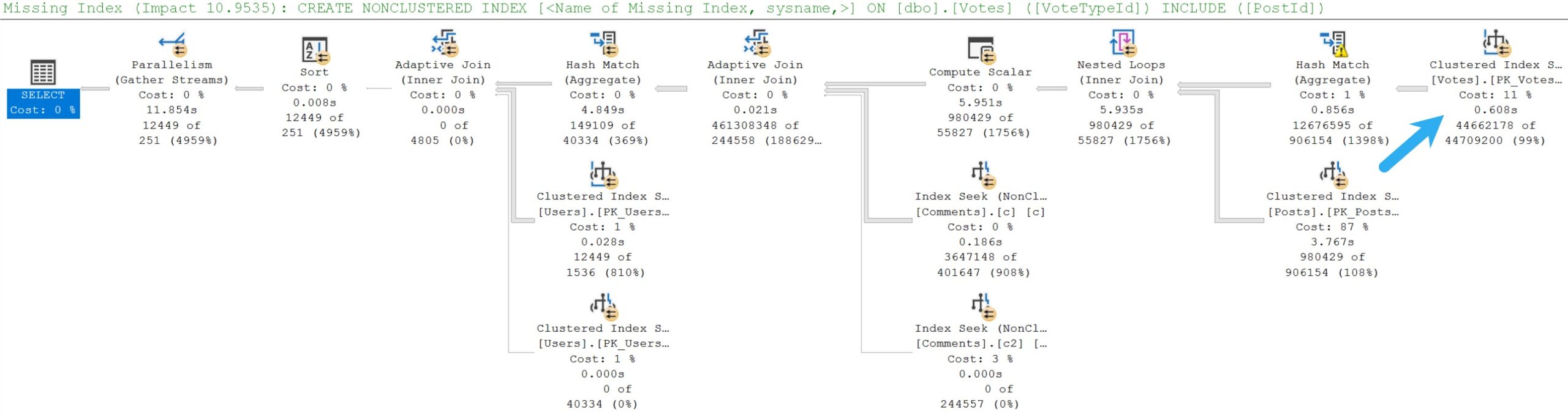
Once again, a missing index request is registered, but only one this time.
On the Votes table.
Not the Posts table.
CREATE INDEX
v
ON dbo.Votes
(VoteTypeId)
INCLUDE
(PostId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Okay SQL Server, you got me. I’ll add it.
Impatience
With that index in place, what sort of totally awesome, fast query plan do we get?
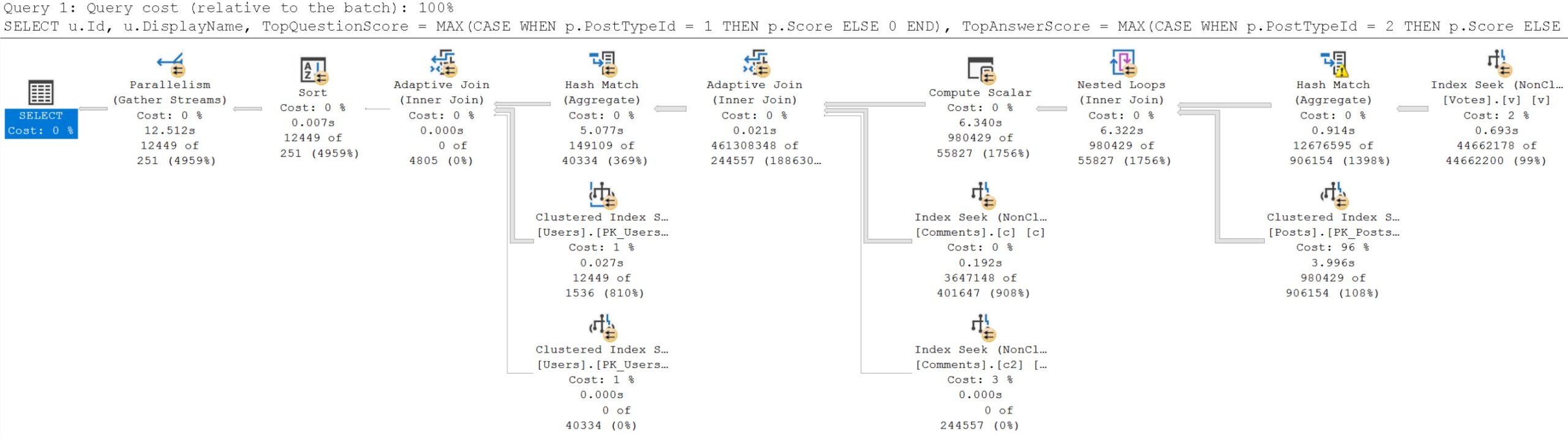
Every time we add an index, this query gets one second slower. Part of the problem, of course, is that the optimizer really likes the idea of joining Posts to Votes first.
All of the query plans we’ve looked at have ad a similar pattern, where Vote is on the outer side of a Nested Loops join, and Posts is on the inner side, correlated on the pre-existing clustered primary key on Posts.
But Posts has a much more important join to the Users table. If we were to make that more efficient, we could perhaps change the optimizer’s mind about join ordering.
And there’s no missing index request to tell us that. We have to use our damned eyes.
Maybe something like this.
CREATE INDEX
p
ON dbo.Posts
(Score, OwnerUserId)
INCLUDE
(PostTypeId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Let’s give that a shot.
“Self-Tuning Database”
When vendors tell you about their self-tuning database systems, they’re lying to you.
Maybe Oracle isn’t. I don’t know.
But I’m so confident in this new index that I’m going to get rid of all the indexes that SQL Server has suggested so far.
They were bad. They made our query slower, and I don’t want them interfering with my awesome index.
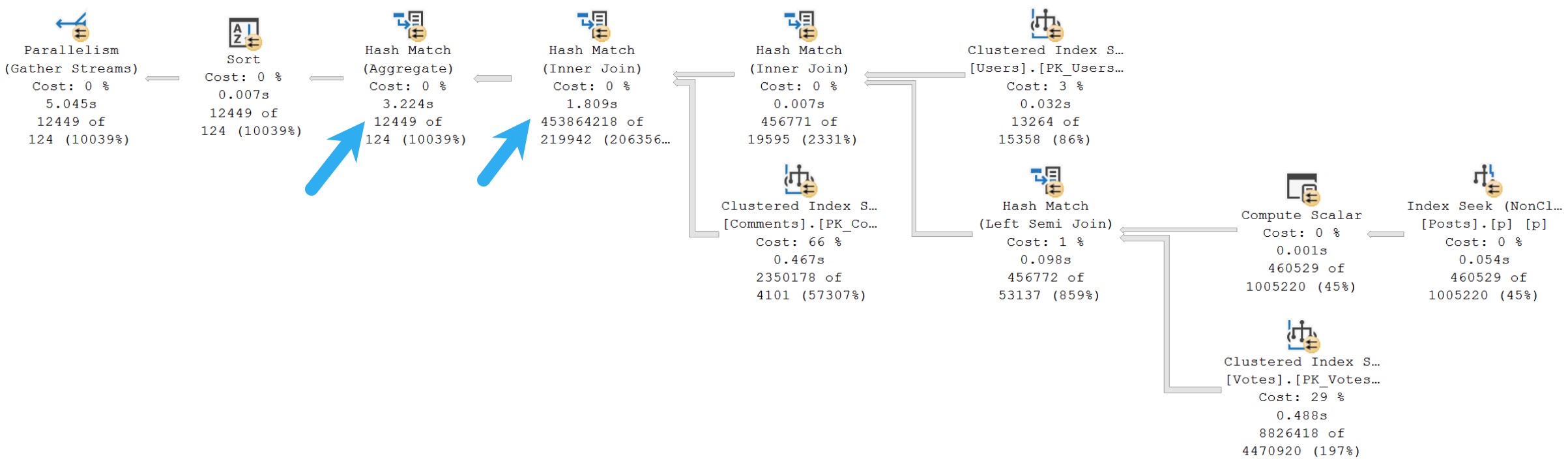
Now the query is twice as fast, at 5 seconds (down from the original 10 seconds). The two operators that take up the majority of the query execution time now are the Hashes; Inner Join and Aggregate.
They don’t spill, but they are likely ill-prepared for the number of rows that they have to deal with. One may infer that from the estimated vs. actual rows that each one sees.
HTDELETE
The primary wait type for the query is HTDELETE, which has had limited documenting.
SQL Server 2014 now uses one shared hash table instead of per-thread copy. This provides the benefit of significantly lowering the amount of memory required to persist the hash table but, as you can imagine, the multiple threads depending on that single copy of the hash table must synchronize with each other before, for example, deallocating the hash table. To do so, those threads wait on the HTDELETE (Hash Table DELETE) wait type.
My friend Forrest has helpfully animated it here.
I tried many different indexing schemes and combinations trying to get the terrible underestimate from the Comments table to not cause this, but nothing quite seemed to do it.
In cases where you run into this, you may need to use a temp table to partially pre-aggregate results, and then join to the troublesome table(s) using that data instead.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
One thought on “Indexing SQL Server Queries For Performance: Fixing A Bad Missing Index Request”
Comments are closed.