Invitational
Defining things scares people. Pause for a moment to think about how many scripts have been written where some roustabout has a mental breakdown when someone refers to them as a boyfriend or girlfriend.
Table definitions have a similar effect on developers. In today’s post, I’m going to use temp tables as an example, but the same thing can happen with regular tables, too.
The issue isn’t with NULL values themselves, of course. The table definition we’re going to use will allow NULLs, but no NULLs will be present in the data.
The issue is with how you query NULLable columns, even when no NULLs are present.
Let’s take a look!
Insecure
Let’s create a temporary table that allows for NULLs, and fill it with all non-NULL values.
CREATE TABLE
#comment_sil_vous_plait
(
UserId int NULL
);
INSERT
#comment_sil_vous_plait WITH(TABLOCK)
(
UserId
)
SELECT
c.UserId
FROM dbo.Comments AS c
WHERE c.UserId IS NOT NULL;
Unfortunately, this is insufficient for SQL Server’s optimizer down the line when we query the table.
But we need one more table to round things out.
Brilliant
This temporary table will give SQL Server’s optimizer all the confidence, temerity, and tenacity that it needs.
CREATE TABLE
#post_sil_vous_plait
(
OwnerUserId int NOT NULL
);
INSERT
#post_sil_vous_plait WITH(TABLOCK)
(
OwnerUserId
)
SELECT
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL;
Just three tiny letters. N-O-T.
That’s all it takes.
The Queries
If you’ve been hanging around SQL Server for long enough, you’re probably aware of what happens when you use NOT IN and encounter NULL values in your tables.
It says “nope” and gives you an empty result (or a NULL result!) because you can’t match values to NULLs that way.
SELECT
c = COUNT_BIG(*)
FROM #post_sil_vous_plait AS psvp
WHERE psvp.OwnerUserId NOT IN
(
SELECT
csvp.UserId
FROM #comment_sil_vous_plait AS csvp
);
SELECT
c = COUNT_BIG(*)
FROM #post_sil_vous_plait AS psvp
WHERE NOT EXISTS
(
SELECT
1/0
FROM #comment_sil_vous_plait AS csvp
WHERE csvp.UserId = psvp.OwnerUserId
);
But since we have no NULLs, well, we don’t have to worry about that.
But we do have to worry about all the stuff SQL Server has to do to see if any NULLs come up.
The Plans
For the NOT IN query, which runs about 4.5 seconds, there are two separate scans of the #comments table.
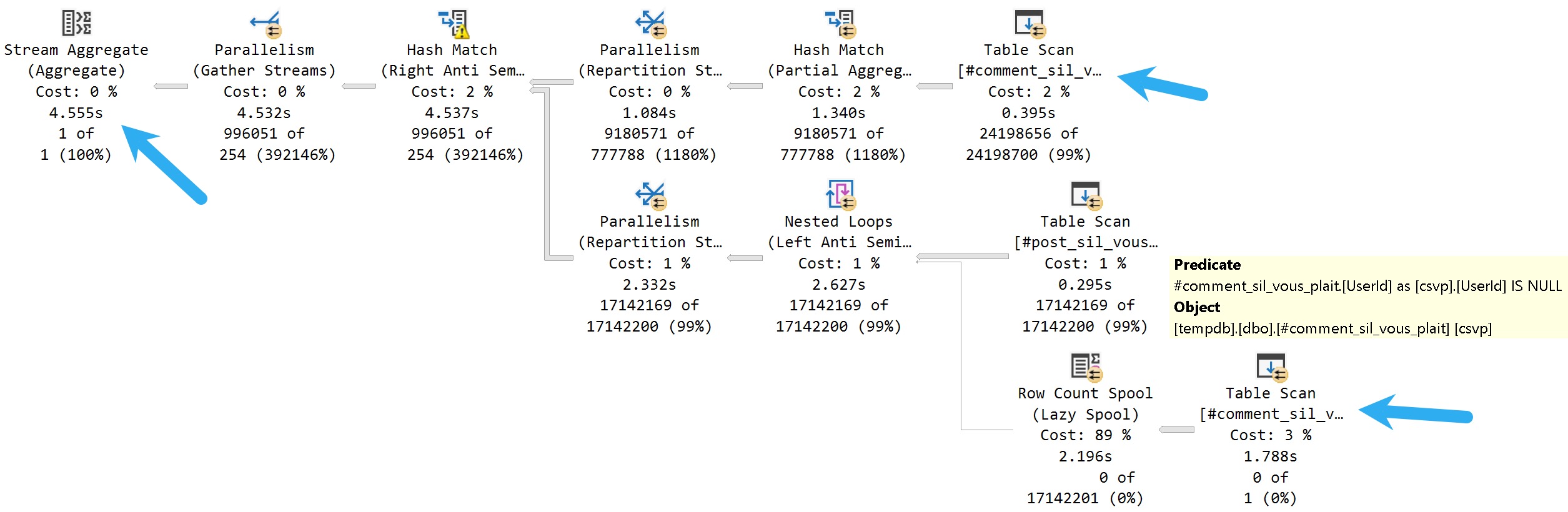
Most of this query plan is expected. There’s a scan of #comments, a scan of #posts, and a hash join to bring them together.
But down below, there’s an additional branch with a row count spool, and a predicate applied to the scan looking for NULL values. The spool doesn’t return data, it’s just there to look for a NULL value and bail the query out if it finds one.
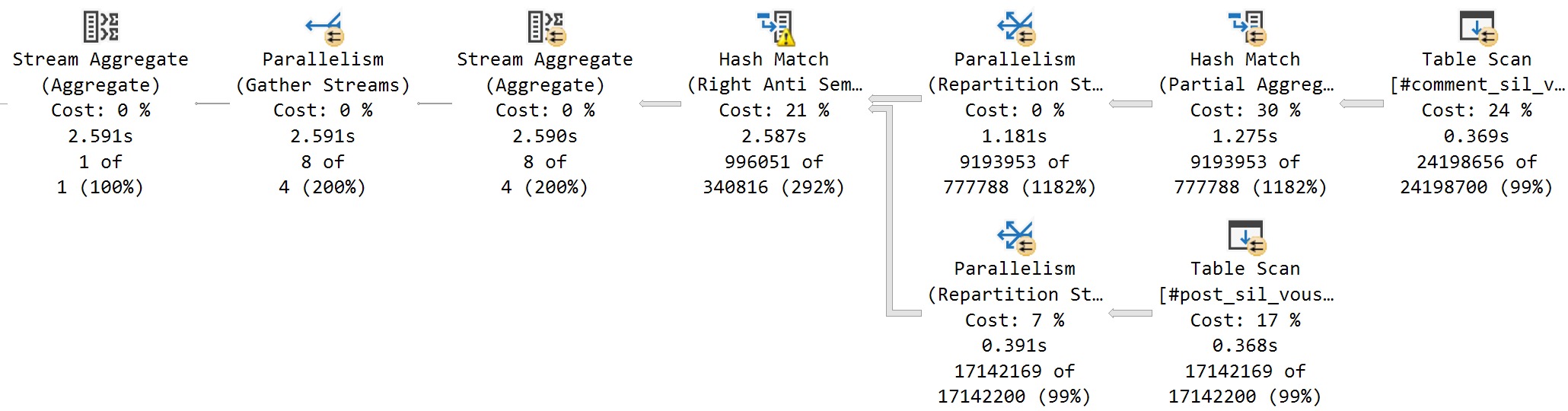
For the NOT EXISTS query, which finishes in 2.5 seconds, we have all the expected parts of the above query plan, but without the spool.
You could partially solve performance issues in both queries by sticking a clustered index on both tables.
If you’re into that sort of thing (I am).
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I wonder how costly it would be to have an auto defined NULL value, like a default calculated column where you could “ISNULL(value, 0)” to your hearts content without the punishment. Whether the cost of implementing that would be more than the cost the engine takes doing things the way we do now.
I sort of wrote about that here: https://www.brentozar.com/archive/2018/06/can-non-sargable-predicates-ever-seek/