Throat Music
In yesterday’s post, we compared a simple situation trying to find the post scoring post for each user.
In today’s post, we’re going to add another condition: we want the highest scoring post for each type of post someone has made.
Now look, most people don’t get involved with any of these things, but whatever. It just poses an interesting and slightly more complicated problem.
Slightly Different Index
Since we’re going to be using PostTypeId in the window function, we need it in the key of our index:
CREATE INDEX p ON dbo.Posts(OwnerUserId, PostTypeId, Score DESC) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Now our query looks like this:
SELECT
u.DisplayName,
u.Reputation,
p.PostTypeId,
p.Score
FROM dbo.Users AS u
JOIN
(
SELECT
p.*,
n =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId,
p.PostTypeId --This is new!
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p
) AS p
ON p.OwnerUserId = u.Id
AND p.n = 1
WHERE u.Reputation > 50000
ORDER BY
u.Reputation DESC,
p.Score DESC;
S’good? S’good. Let’s go.
Row Number Query Plan
Similar to yesterday’s plan, this one is rather slow, rather serial, and generally not how we want to be spending our precious time.
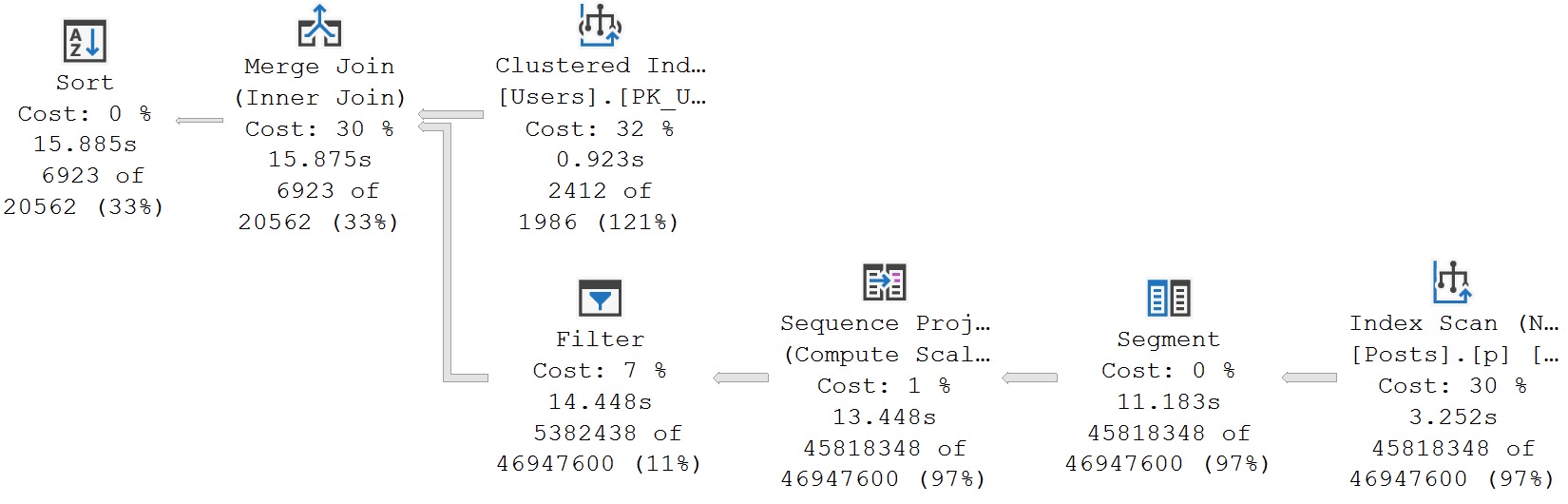
Let’s look at the apply method, because we have to change our query a little bit to accomplish the same thing.
Cross Apply With MAX
Rather than go with TOP (1), we’re going to GROUP BY OwnerUserId and PostTypeId, and get the MAX(Score).
SELECT
u.DisplayName,
u.Reputation,
p.PostTypeId,
p.Score
FROM dbo.Users AS u
CROSS APPLY
(
SELECT
p.OwnerUserId,
p.PostTypeId,
Score = MAX(p.Score)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
GROUP BY
p.OwnerUserId,
p.PostTypeId
) AS p
WHERE u.Reputation > 50000
ORDER BY
u.Reputation DESC,
p.Score DESC;
This will give us the same results, but a lot faster. Again.
Cross Apply Query Plan
Like I was saying…

Down to ~400ms now. Not bad, right?
Lower Selectivity
If we take those same queries and lower the reputation filter from 50,000 to 1, some interesting changes to the query plans happen.
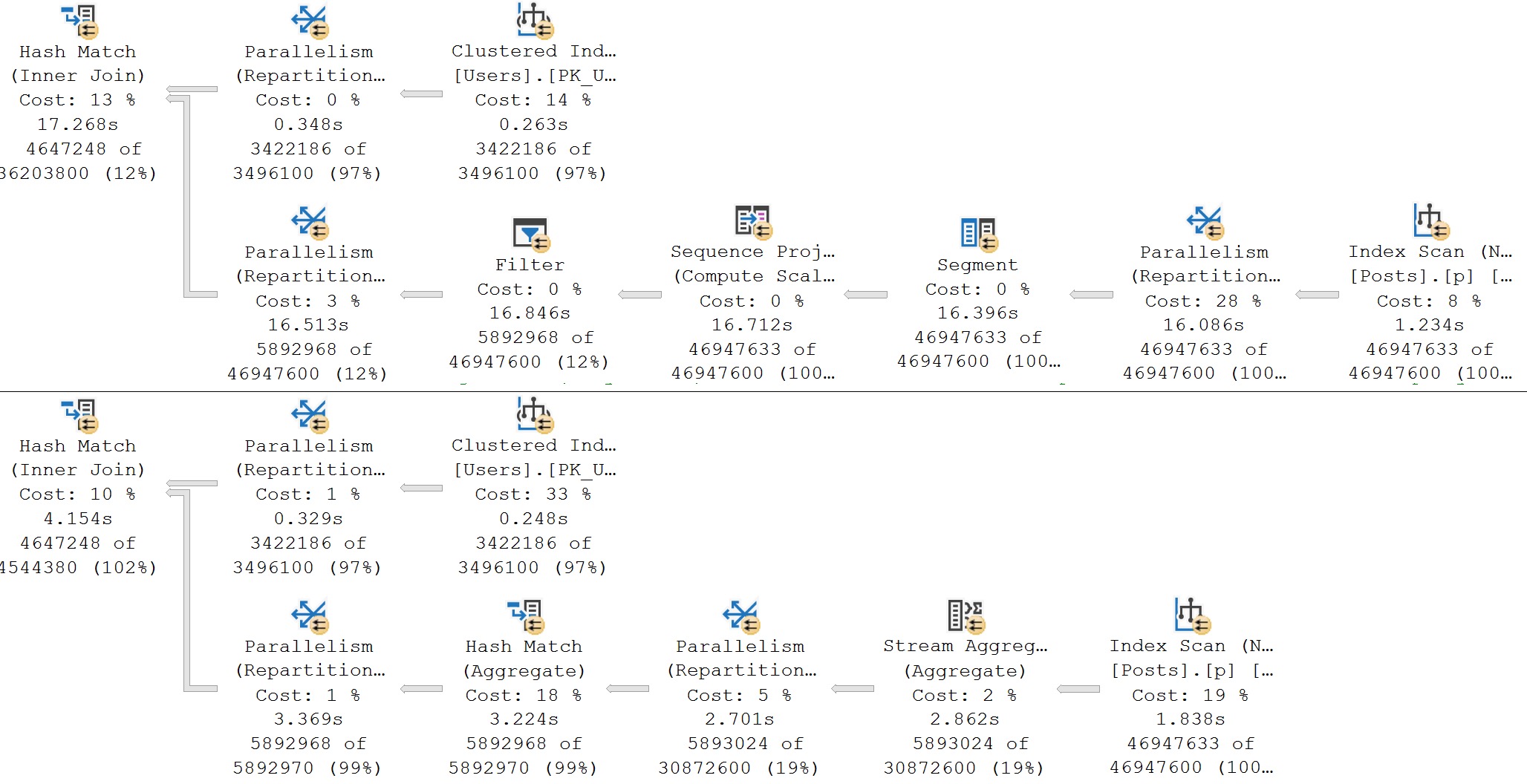
Repartition streams and I have had some problems in the past. It’s not necessarily “to blame”, it just has a tough time with some data distributions, especially, it seems, when it’s order preserving.
The cross apply with aggregation works really well. It’s kinda neat that both queries get slower by the same amount of time, but the ROW_NUMBER query is still much, much slower.
All of this is interesting and all, but you know what? We haven’t look at batch mode. Batch mode fixes everything.
Sort of. Don’t quote me on that. It’s just really helpful in the kind of BIG QUERY tuning that I end up doing.
Batch Mode
This is the only thing that makes the ROW_NUMBER query competitive in this scenario, owing to the fact that batch mode often removes Repartition Streams, and we’re eligible for the Window Aggregate operator.
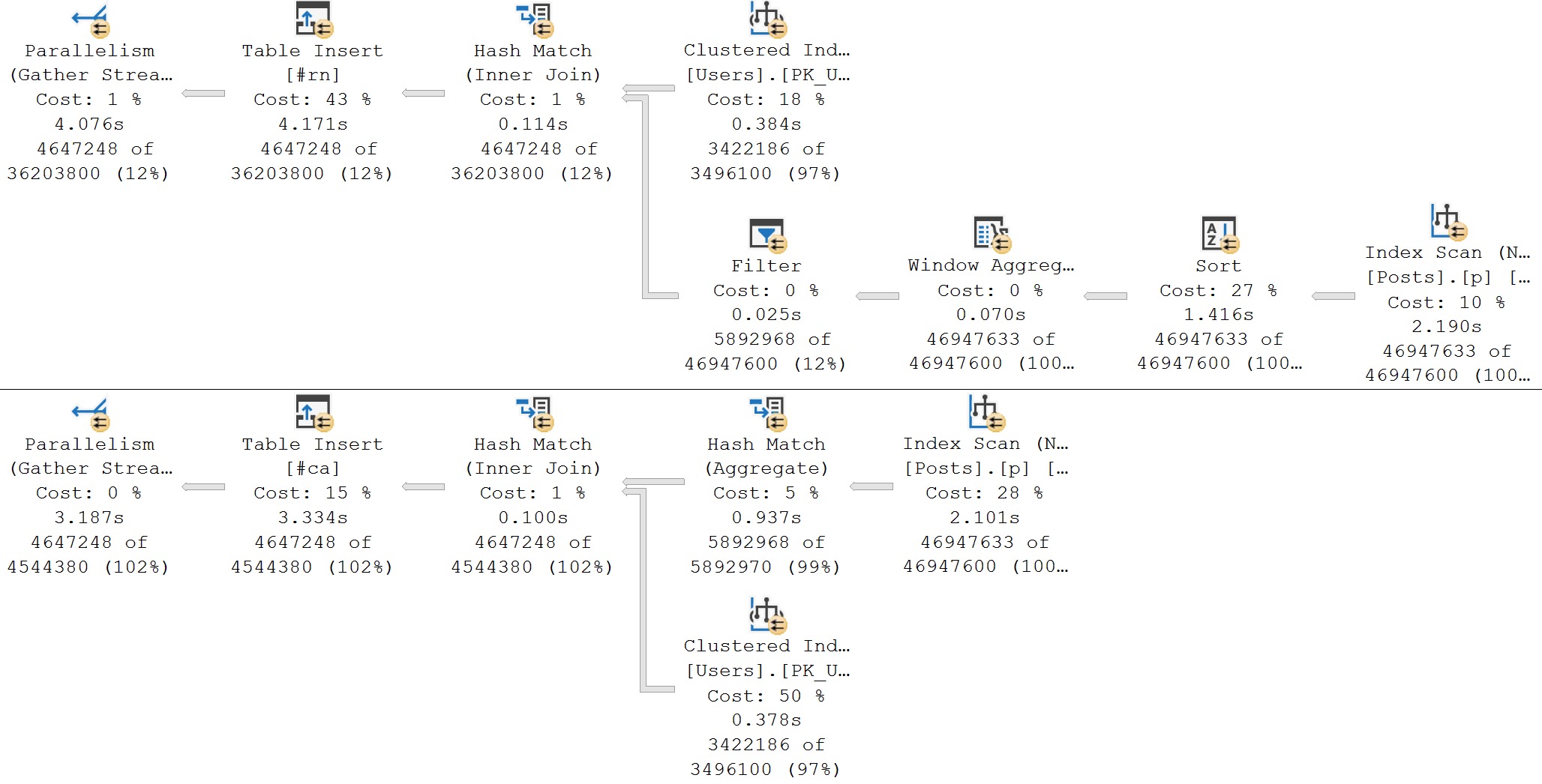
I’m dumping these results to #temp tables because I don’t want to wait for SSMS to render the large result set, but you can still see the positive overall effect.
The poorly performing ROW_NUMBER query is now very competitive with the CROSS APPLY query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.