Hot To Trot
Most of the time when the optimizer thinks an index will make a big enough difference, it’ll tell you.
Sure, it’s not perfect, but it can get you where you’re going fast enough. If you’re relying on that sort of feedback in query plans, or in the missing index DMVs, you’ll hate this.
Not only does SQL Server create an index for you, it doesn’t really tell you about it. There’s no loud warning here.
It also throws that index away when the query is done executing. It only exists in tempdb while the query executes, and it’s only available to the query that builds it.
And boy, they sure can take a long time to build.
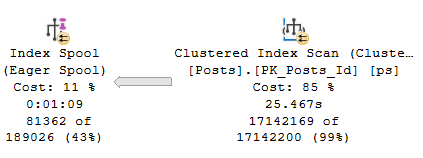
Let’s take a closer look!
Skidding Out
Eager index spools can occur on the inner side of Nested Loops joins to reduce the amount of work that needs to be done there, by creating a more opportune index for the loop to work off of.
That all sounds very good, but there are some problems:
- The index gets created single-threaded
- The way data is loaded into the spool is very inefficient
- The spool is disposed of when the query is finished,
- It’ll get built over and over again on later executions
- There’s no missing index request for the spool anywhere
I’m not suggesting that the query would be faster without the spool. Reliable sources tell me that this thing runs for over 6 hours without it. My suggestion is that when you see Eager Index spools, you should pay close attention.
Let’s talk about how you can do that.
Mountainous
In some cases, your only option is to look at the Eager Index Spool to see what it’s doing, and create an index on your own to mimic it.
If you’re the kind of person who likes free scripts, sp_BlitzCache will look for Eager Index Spools in your query plans and do that for you. You’re welcome.
If you’re a more manual type, here’s what you do: Look at the Eager Index Spool.
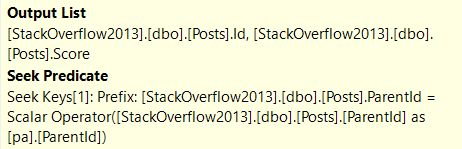
The Seek Predicate(s) are they key columns, and the Output List is the included columns.
CREATE INDEX spool_b_gone ON dbo.Posts(ParentId) INCLUDE (Score);
Since the Id column is the clustered index, we don’t explicitly need it in the index definition — remember that nonclustered indexes inherit them. It’ll end up as a “hidden” key column, after all.
Human Touch
In most cases, this will be good enough. The performance difference will be night and day, if the build source for the Eager Index Spool was fairly large, or if your query built the same Eager Index Spool multiple times.
Though just like missing index requests, Eager Index Spools don’t always come up with the *best* index.
Thinking through our query, we may want to move Score up to the key of the index.
SELECT pq.OwnerUserId, pq.Score, pq.Title, pq.CreationDate,
pa.OwnerUserId, pa.Score, pa.CreationDate
FROM dbo.Posts AS pa
INNER JOIN dbo.Posts AS pq
ON pq.Id = pa.ParentId
WHERE pq.PostTypeId = 1
AND pq.CommunityOwnedDate IS NULL
AND pq.AnswerCount > 1
AND pa.PostTypeId = 2
AND pa.OwnerUserId = 22656
AND pa.Score >
(
SELECT MAX(ps.Score)
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.Id <> pa.Id
)
ORDER BY pq.Id;
See that subquery at the very end, where we’re aggregating on Score? Having Score in the key of the index will put the data in order, which makes a Stream Aggregate pretty painless. Remember that Stream Aggregates expect sorted input.
That’s, like, how they stream.
CREATE INDEX spool_b_gone
ON dbo.Posts(ParentId, Score);
Letter To The Query Editor
There are some cases where changing a query is a lot less painful than changing or adding indexes.
You might already have a lot of indexes, or you might have a really big table, or you might be on Standard Edition, which is a lot like being on one of those airplanes where the entire thing is economy class.
In this case, we can rewrite the query in a way that avoids the Eager Index Spool entirely:
SELECT pq.OwnerUserId, pq.Score, pq.Title, pq.CreationDate,
pa.OwnerUserId, pa.Score, pa.CreationDate
FROM dbo.Posts AS pa
INNER JOIN dbo.Posts AS pq
ON pq.Id = pa.ParentId
WHERE pq.PostTypeId = 1
AND pq.CommunityOwnedDate IS NULL
AND pq.AnswerCount > 1
AND pa.PostTypeId = 2
AND pa.OwnerUserId = 22656
AND NOT EXISTS
(
SELECT 1/0
FROM dbo.Posts AS ps
WHERE ps.ParentId = pa.ParentId
AND ps.Id <> pa.Id
AND ps.Score >= pa.Score
)
ORDER BY pq.Id;
Which gets us a different plan. And you can see why we’d want one.
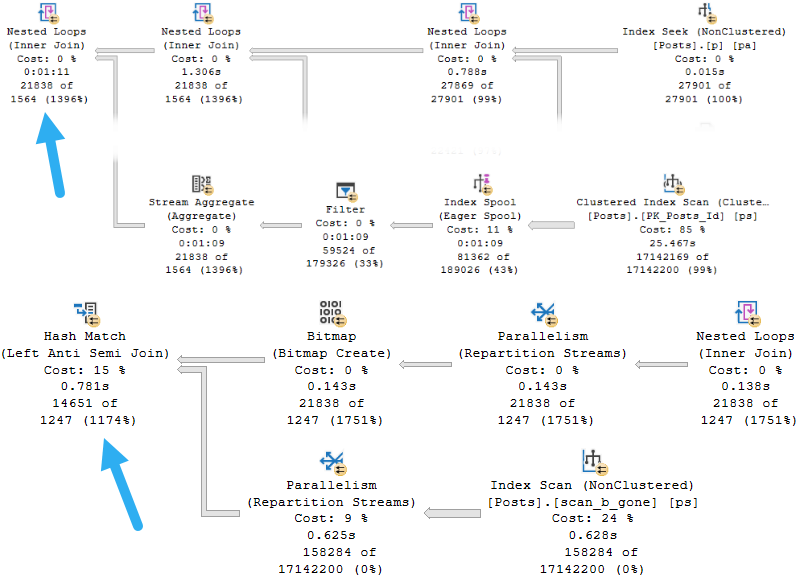
Avoiding the need for an Eager Index Spool reduces the query time from over a minute to under a second.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Starting SQL: SARGability, Or Why Some SQL Server Queries Will Never Seek
- Starting SQL: Fixing Parameter Sensitivity Problems With SQL Server Queries
- Starting SQL: How Parameters Can Change Which Indexes SQL Server Chooses
- Starting SQL: Why Is My SQL Server Query Suddenly Slower Than It Was Yesterday?
Hi Erik, thank you for the article!
By the way, having SELECT 1/0 in the subquery – does it make any special sense comparing with simple SELECT 1?
BR
Sergey
Nope, just a habit.