Will Travel
If you recall yesterday’s post, we added a couple two column indexes to the Posts table.
Each one helped a slightly different query, but either index would likely be “good enough”.
This post will focus on another common scenario I see, where people added many single column indexes over the years.
In this scenario, performance is much more variable.
Singletonary
Here are our indexes:
CREATE INDEX ix_spaces ON dbo.Posts(ParentId); CREATE INDEX ix_tabs ON dbo.Posts(Score);
Taking the same queries from yesterday:
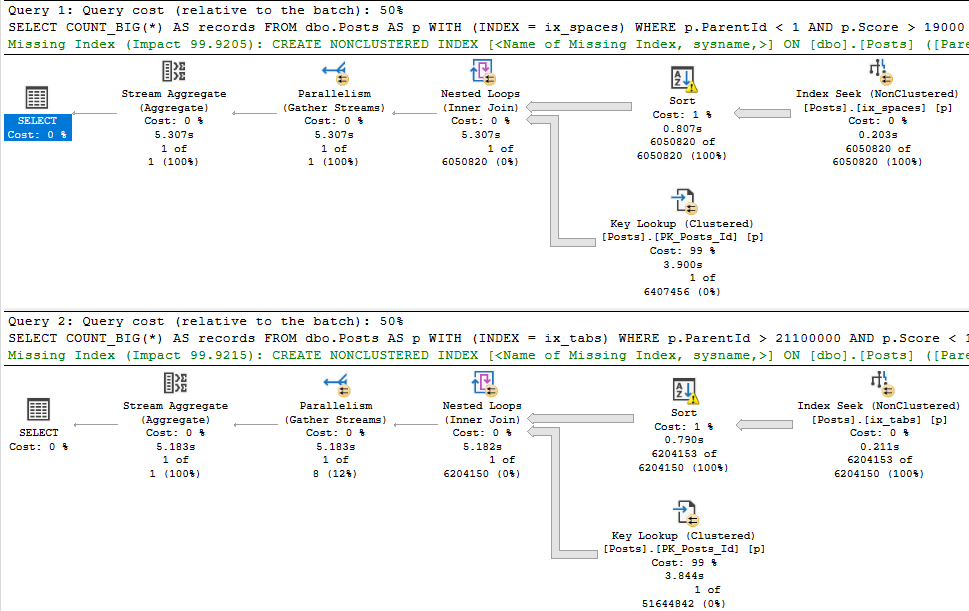
SELECT COUNT_BIG(*) AS records FROM dbo.Posts AS p WHERE p.ParentId < 1 AND p.Score > 19000 AND 1 = (SELECT 1); SELECT COUNT_BIG(*) AS records FROM dbo.Posts AS p WHERE p.ParentId > 21100000 AND p.Score < 1 AND 1 = (SELECT 1);
This is what the new plans look like:
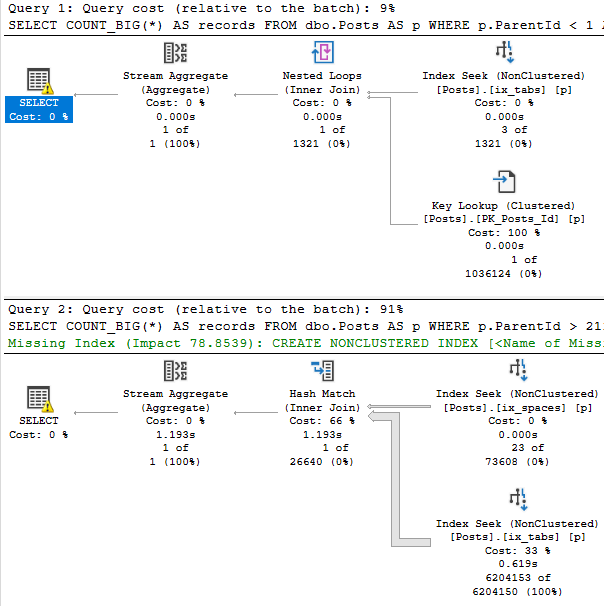
The first thing you may notice is that the top plan performs a rather traditional key lookup, and the bottom plan performs a slightly more exotic index intersection.
Both concepts are similar. Since clustered index key columns are present in nonclustered indexes, they can be used to either join a nonclustered index to the clustered index on a table, or to join two nonclustered indexes together.
It’s a nice trick, and this post definitely isn’t to say that either is bad. Index intersection just happens to be worse here.
Wait, But…
You may have noticed that both queries get pretty bad estimates. You might even be thinking about leaving me a comment to update stats.
The thing is that I created these indexes, which means they get stats built with a full scan, and it’s a demo database where nothing changes.
We just get unfortunate histograms, in this case. If I create very specific filtered statistics, both plans perform a key lookup.
CREATE STATISTICS s_orta ON dbo.Posts(ParentId) WHERE ParentId > 21100000 WITH FULLSCAN; CREATE STATISTICS s_omewhat ON dbo.Posts(Score) WHERE Score < 1 WITH FULLSCAN; CREATE STATISTICS s_emi ON dbo.Posts(ParentId) WHERE ParentId < 1 WITH FULLSCAN; CREATE STATISTICS s_lightly ON dbo.Posts(Score) WHERE Score > 19000 WITH FULLSCAN;
This is necessary with the legacy cardinality estimator, too. Rain, sleet, shine.
Bad estimates happen.
When your tables are large enough, those 200 (plus one for NULLs, I know, I know) steps often can’t do the data justice.
Filtered stats and indexes can help with that.
Something I try to teach people is that SQL Server can use whatever statistics or methods it wants for cardinality estimation, even if they’re not directly related to the indexes that it uses to access data.
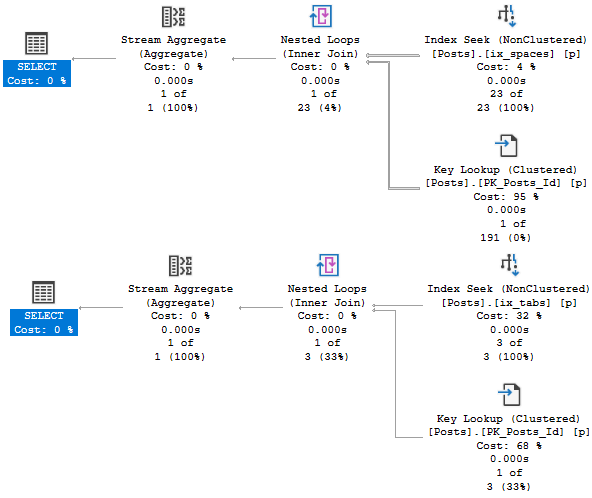
With filtered statistics, things go fine for both plans:
When Could This Cause Trouble?
Obviously, plans like this are quite sensitive to parameter sniffing. Imagine a scenario where a “bad” plan got cached.
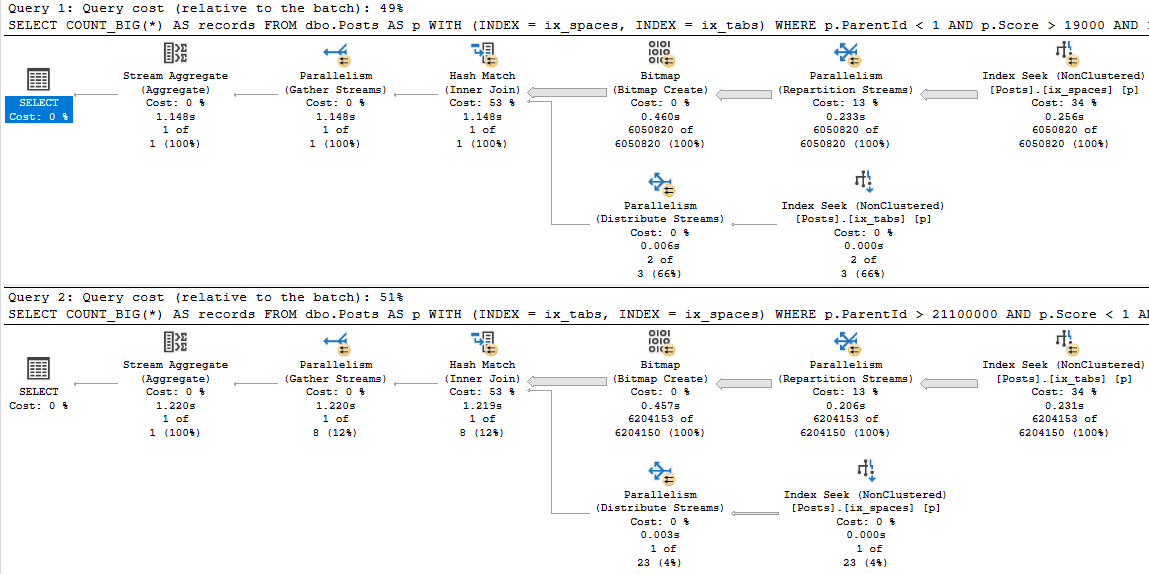
Having one instance of this query running doesn’t cause much of a CPU uptick, but if user concurrency is high then you’d notice it pretty quickly.
Parallel plans, by definition, use a lot more CPU, and more worker threads. These both reserve and use 8 threads.
Those two plans aren’t even the worst possible case from a duration perspective. Check out these:
Doubledown
When talking index design, single column indexes are rarely a good idea.
Sometimes I’ll see entire tables with an index on every column, and just that column.
That can lead to some very confusing query plans, and some very poor performance.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Never mind statistics update, go for the gusto and do, dare I say it, a rebuild/reorg.
JUST KIDDING!
Nice work on getting those plans, though. I’ve seen many tables with single-column indexes on *every* column… terrible for performance and just makes things painful all over the place. I’d not heard of the index-intersection join before, so cheers!
It’s quite a pesky habit to get people to kick. Probably the flipside of missing index requests on (one column) include (every column).