Choices, Choices
The optimizer has a lot of choices. As of SQL Server 2019, there are 420 of them.
You can see how many are available in your version of SQL Server by doing this:
SELECT
total_transformations
= COUNT_BIG(*)
FROM sys.dm_exec_query_transformation_stats;
Then you can change the query to actually select columns and view all the available rules.
Pretty neat.
Ten Hut
One thing the optimizer can do is order data to make things more efficient, like we saw with Lookups.
That choice, like nearly every optimizer choice (barring ones based on product or feature limitations), is based on costing. Those costs could be right, wrong, lucky, unlucky, or anything in between.
One of those options is to use an operator that requires sorted input, or sorts input on its own.
Why do we care about this? Because Sorts ask for memory, and memory can be a contentious subject with SQL Server. Not only because Sorts often ask for size-of-data memory grants
Here are some common examples!
Distinctly Yours
If you ask for a set of data to be distinct, or if you group by every column you’re returning, you may see a query plan that looks like this:

The details of the operator will show you some potentially scary and hairy details, particularly if you’re asking for a large number of columns to be made distinct:
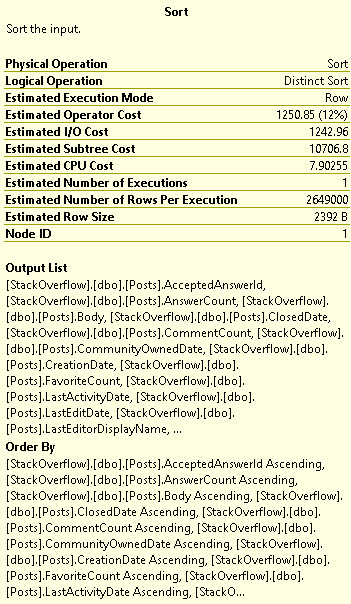
All of the column that you have in your select list (Output) will end up in the Order By portion of the Sort. That could add up to quite a large memory grant.
Ex-stream-ly Necessary
If the Almighty Optimizer thinks that a Stream Aggregate will be the least-expensive way to aggregate your data, you may see a plan like this:

Of course, not all Stream Aggregates will have a Sort in front of them. Global Aggregates will often use them.
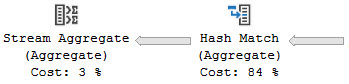
Rows from the Hash Aggregate flow into the Stream Aggregate, but order doesn’t matter here.

What is the Hash Match hashing? Apparently nothing! Good job, hash match.
Nasty Loops
Just like with Lookups (which also use Nested Loops), SQL Server may choose to Sort one input into the Nested Loops Join.
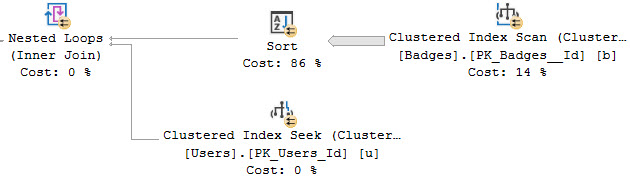
Orderly data is apparently very important to all sorts of things. If you see a lot of this in your query plans, you may want to start thinking about adding indexes to put data in required order.
And Acquisitions
Likewise, Merge joins may also show a Sort on one or both inputs to put data in the correct join order:
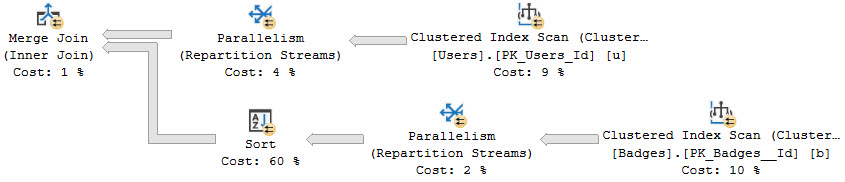
Maybe not great:

That Tree
Sometimes these Sorts are harmless, and sometimes they’re not. There are many situational things about the queries, indexes, available resources, and query plan appropriateness that will lead you to treating things differently.
Parameter sniffing, cardinality estimate accuracy, query concurrency, and physical memory are all potential reasons for these choices going great or going grog.
Of course, parallel merge joins are always a mistake.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.