What Why
Certain windowing functions allow you to specify more precise windows to perform calculations on, and many of them allow you to specify an empty OVER() clause to get a global aggregate for a result set.
The performance difference between RANGE and ROWS is fairly well-documented, and I’m mostly covering it here to show you the difference in execution plans.
There’s also some different behavior when Batch Mode shows up around memory usage, which I was amused by.
We’re going to be using this index to help our queries move along faster.
CREATE INDEX c
ON dbo.Comments
(
UserId,
CreationDate,
Score
);
RANGEr Zone
If you don’t specify the type of window you want, by default you’ll use RANGE. I’m using it here to be clear about which I’m covering.
WITH Comments AS
(
SELECT
SUM(c.Score) OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
RANGE BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n < 0
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
Even with an index to help us along, this query runs for a very long time. In fact it’s been running for the entire time I’ve been writing this particular blog post.
The longer it runs, the more space-filler I have to type, and the more post quality suffers. If this post is terrible, you can blame the above query. Or SQL Server.
Whatever.
Three minutes later:

In my experience, this is the query plan pattern that shows up when you use the RANGE/default specification.
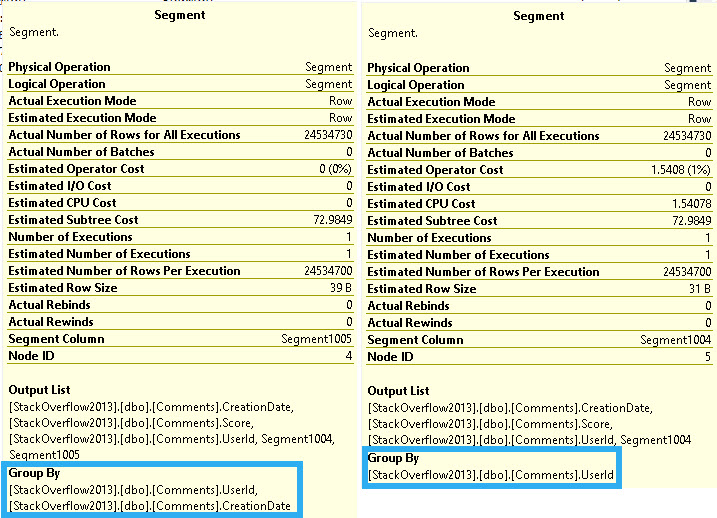
The first Segment is for the Partition By elements, and the second Segment is for both Partition By and Order By.
Depending on your ideas about our time on Earth, and the afterlife, this query could be considered a poor use of finite time.
ROW Boat
Switching over to the ROWS specification, performance is much different, and we get a different execution plan.
WITH Comments AS
(
SELECT
SUM(c.Score) OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n < 0
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
I only have to wait about 10 seconds for this one, with some efficiency gained by the query going parallel. Even if I force the query to run at DOP 1, it runs in about 25 seconds. Is 15 seconds of duration worth the 7 additional threads? I don’t know.
Again, it depends largely on your belief system. You may find this to be a good way to kill time until you end up somewhere better. You might not.

The relevant difference in the query plan here (again, based on my observations over the years) is that rather than two consecutive Segment operators, we have Segment > Sequence Project > Segment > Window Spool.
In this case, the Segment operators only list UserId in the “Group By” portion of the query plan. The Sequence Project uses ROW_NUMBER to define the frame.

The reason for the performance difference is that the RANGE/default specification uses an on-disk worktable for the Window Spool, and the ROWS specification uses one in-memory. If you were to compare memory grant details for the two query plans, you’d see the RANGE/default query had 0 for all memory grant categories, and the ROWS specification asks for a ~6GB memory grant.
There is a limit here though. If you go beyond 10,000 rows, an on-disk table will be used. This query will run for just about a minute:
WITH Comments AS
(
SELECT
SUM(c.Score) OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
ROWS BETWEEN 9999 PRECEDING
AND CURRENT ROW
) AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n < 0
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
Unfortunately, details of the Window Spool don’t indicate that any I/O was done. This seems a little bit weird, since Many to Many Merge Joins will show I/O details for the worktable.
Anyway. What about that Batch Mode?
Batcher Up
In Batch Mode, the window specification doesn’t tend to make a lot of difference when it comes to performance.
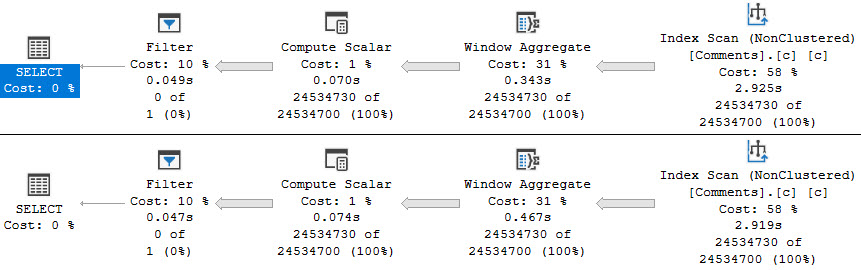
Both of these queries ask for 1MB of memory, but take ~3 seconds to scan the table single-threaded.
Again, your trade-off here will be deciding whether or not it’s worth scanning the table faster with parallel threads but incurring additional memory grant with the Sort.
Even though you’re Sorting Sorted data.
Go figure.
OVER It
If you use an empty OVER() clause, you can’t specify rows or ranges. You use the default/RANGE specification. That typically means queries using that in Row Mode vs Batch Mode will be much slower.
WITH Comments AS
(
SELECT
COUNT_BIG(*) OVER () AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n < 0
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
Also, the query plans are atrocious looking.
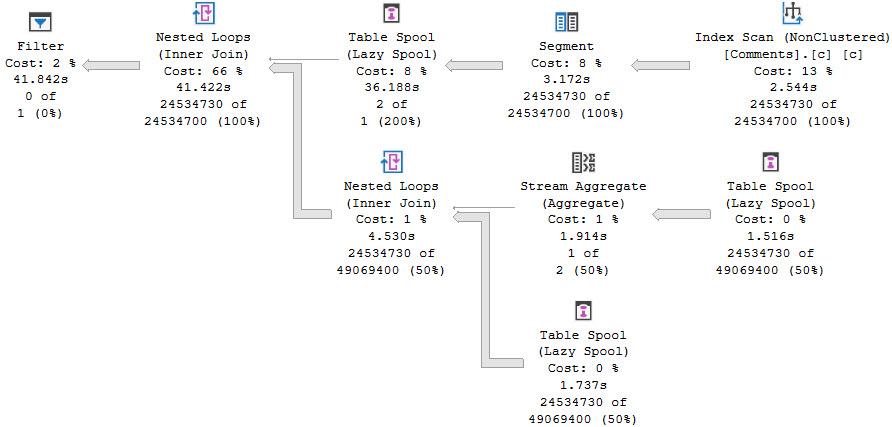
Batch Mode does solve a lot of the issues with them, but at the cost of additional memory usage, and the potential for spilling.
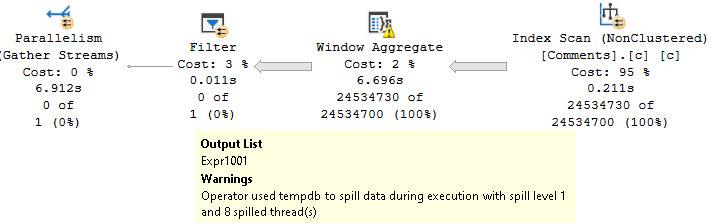
Batch Mode Memory Grant Feedback will fix the spill, and the query will run about 2-3 seconds faster.
Thanks, probably.
Some Grants Are Bigger Than Others
The non-spilling memory grant for the COUNT query is about 800MB.
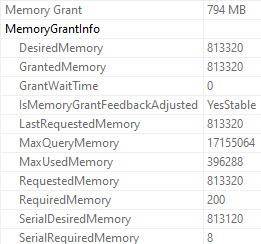
The non-spilling grant for the SUM query is about 1100MB:
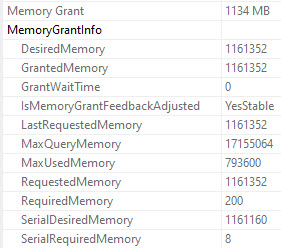
Apparently the reason for the additional memory is because behind the scenes sum also does a count, and returns NULL if it’s zero.
SELECT
SUM(x.x) AS the_sum,
COUNT_BIG(x.x) AS the_x_count,
COUNT_BIG(*) AS the_full_count
FROM
(
SELECT CONVERT(int, NULL) AS x
) AS x;
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.