Not A Doctor
All of our previous queries looked about like this:
WITH Comments AS
(
SELECT
ROW_NUMBER() OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
) AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n = 0;
The only columns that we were really selecting from the Comments table were UserId and CreationDate, which are an integer and a datetime.
Those are relatively easy columns to deal with, both from the perspective of reading and sorting.
In order to show you how column selection can muck things up, we need to create a more appropriate column store index, add columns to the select list, and use a where clause to restrict the number of rows we’re sorting. Otherwise, we’ll get a 16GB memory grant for every query.
Starting Point
Selecting no additional columns:
WITH Comments AS
(
SELECT
ROW_NUMBER() OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
) AS n
FROM dbo.Comments AS c
WHERE c.CreationDate >= '20131201'
)
SELECT
c.*
FROM Comments AS c
WHERE c.n = 0;
On a second run of the query, after a memory grant feedback correction, we end up with a plan with these details:
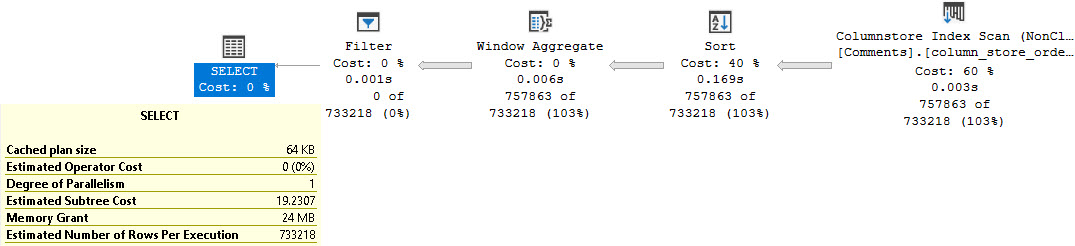
It takes us 3 milliseconds to scan the column store index, and we get a 24MB memory grant. This is good. I like this.
Darn Strings
Our second query looks like this. We’re selecting all the columns from the Comments table.
WITH Comments AS
(
SELECT
c.Id,
c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId,
ROW_NUMBER() OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
) AS n
FROM dbo.Comments AS c
WHERE c.CreationDate >= '20131201'
)
SELECT
c.*
FROM Comments AS c
WHERE c.n = 0;
A first run of the query, before memory grant feedback fixes things for us, asks for a 16GB memory grant. Without this mechanism in place, we’ll keep asking for the same unproductive grant. If you don’t have batch mode and enterprise edition, this is the scenario you’ll face over and over again.
When memory grant correction kicks in, we end up with a 456MB memory grant.
Quite an adjustment, eh?

We also end up taking 125ms to scan the table with parallel threads, up from 3 milliseconds with a single thread. Of course, the issue here is mostly the Text column.
Strings were a mistake.
No Strings Attached
If we select all the columns other than the string, we’ll end up with a very similar set of metrics as the first plan.
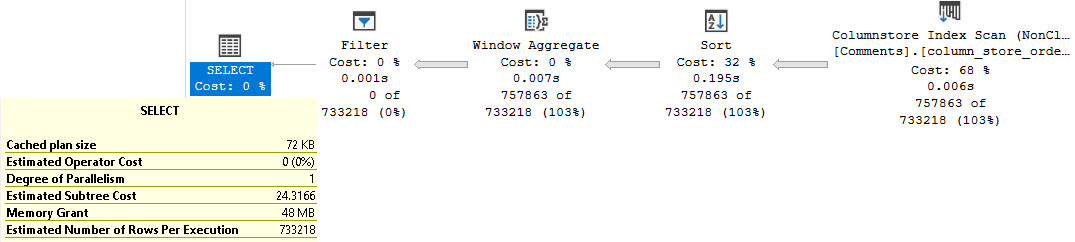
If we want to maintain those metrics, but still show the Text column, we’ll need to do something like this:
WITH Comments AS
(
SELECT
c.Id,
c.CreationDate,
c.PostId,
c.Score,
c.UserId,
ROW_NUMBER() OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
) AS n
FROM dbo.Comments AS c
WHERE c.CreationDate >= '20131201'
)
SELECT
c.*,
c2.Text
FROM Comments AS c
JOIN dbo.Comments AS c2
ON c.Id = c2.Id
WHERE c.n = 0;
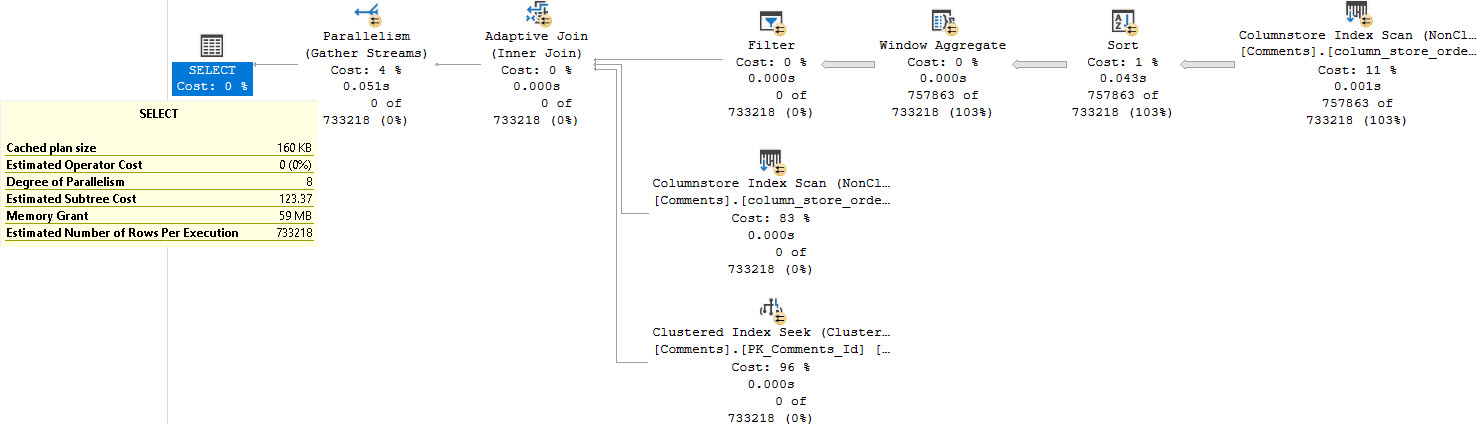
Using a self-join, and getting the initial set of columns we care about, then getting the Text column at the end means we avoid some of the the knuckle-headedness of strings in databases.
Deep Drink
This pattern applies to more than just windowing functions, but it’s a performance issue I have to tune pretty often for people using paging queries.
In tomorrow’s post, we’ll look at another rather unfortunate thing that I see people messing up with windowing functions, and how you can spot it looking at query plans.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Common Query Plan Patterns For Windowing Functions: Column Selection Matters”
Comments are closed.