I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
YouTube Days: Predicates In SQL Server Query Plans
I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Improving The Parallel Query Processing Documentation For SQL Server
I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Cardinality Estimation For Local Variables And Parameters
I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
When one thinks of effective communicators, indexes aren’t usually at the top of the list. And for good reason!
They’re more the strong, silent type. Like Gary Cooper, as a wiseguy once said. But they do need to talk to each other, sometimes.
For this post, I’m going to focus on tables with clustered indexes, but similar communication can happen with the oft-beleaguered heap tables, too.
Don’t believe me? Follow along.
Clustered
This post is going to focus on a table called Users, which has a bunch of columns in it, but the important thing to start with is that it has a clustered primary key on a column called Id.
Shocking, I know.
CONSTRAINT PK_Users_Id
PRIMARY KEY CLUSTERED
(
Id ASC
)
But what does adding that do, aside from put the table into some logical order?
The answer is: lots! Lots and lots. Big lots (please don’t sue me).
Inheritance
The first thing that comes to my mind is how nonclustered indexes inherit that clustered index key column.
Let’s take a look at a couple examples of that. First, with a couple single key column indexes. The first one is unique, the second one is not.
/*Unique*/
CREATE UNIQUE INDEX
whatever_uq
ON dbo.Users
(AccountId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
/*Not unique*/
CREATE INDEX
whatever_nuq
ON dbo.Users
(AccountId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
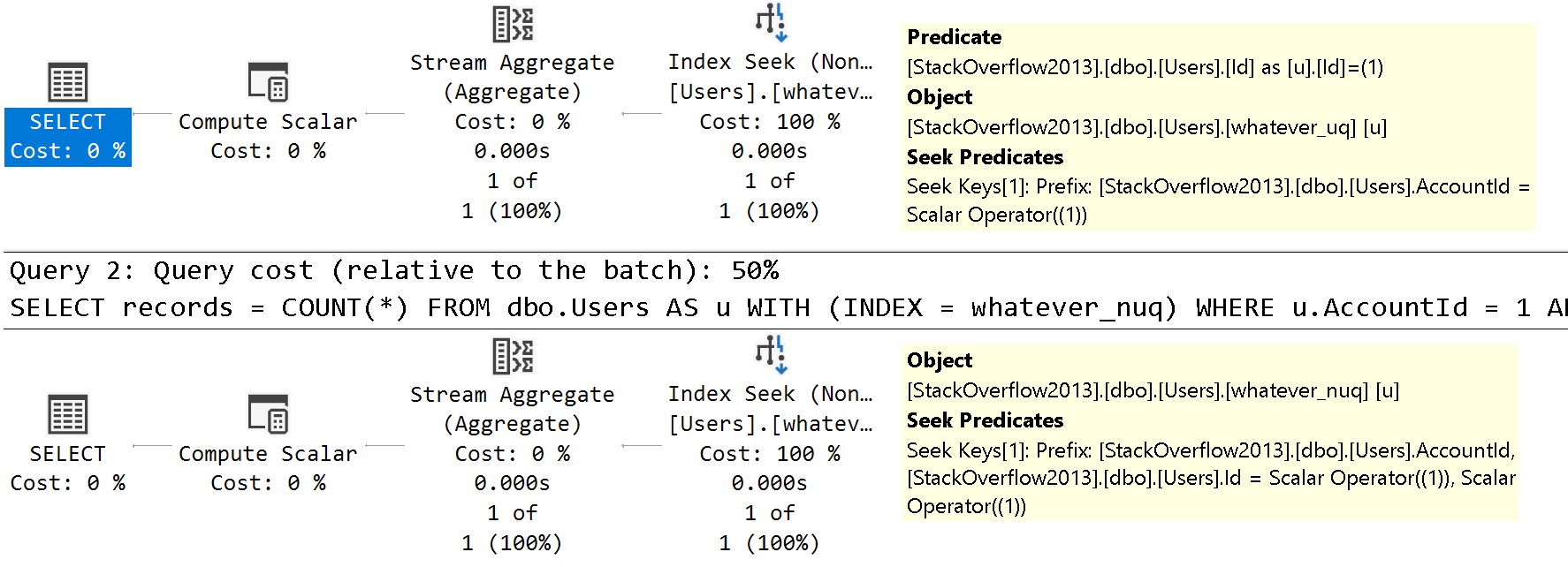
For these queries, pay close attention to the where clause. We’re searching on both the AccountId column that is the only column defined in our index, and the Id column, which is the only column in our clustered index.
SELECT
records = COUNT(*)
FROM dbo.Users AS u WITH (INDEX = whatever_uq)
WHERE u.AccountId = 1
AND u.Id = 1;
SELECT
records = COUNT(*)
FROM dbo.Users AS u WITH (INDEX = whatever_nuq)
WHERE u.AccountId = 1
AND u.Id = 1;
The query plans are slightly different in how the searches can be applied to each index.
dedicated
See the difference?
In the unique index plan, there is one seek predicate to AccountId, and one residual predicate on Id
In the non-unique index plan, there are two seeks, both to AccountId and to Id
The takeaway here is that unique nonclustered indexes inherit clustered index key column(s) are includes, and non-unique nonclustered indexes inherit them as additional key columns.
Fun!
Looky, Looky
Let’s create two nonclustered indexes on different columns. You know, like normal people. Sort of.
I don’t usually care for single key column indexes, but they’re great for simple demos. Remember that, my lovelies.
CREATE INDEX
l
ON dbo.Users
(LastAccessDate)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
c
ON dbo.Users
(CreationDate)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
How will SQL Server cope with all that big beautiful index when this query comes along?
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.CreationDate >= '20121231'
AND u.LastAccessDate < '20090101';
How about this bold and daring query plan?
indexified!
SQL Server joins two nonclustered indexes together on the clustered index column that they both inherited. Isn’t that nice?
Danes
More mundanely, this is the mechanism key lookups use to work, too. If we change the last query a little bit, we can see a great example of one.
SELECT
u.*
FROM dbo.Users AS u
WHERE u.CreationDate >= '20121231'
AND u.LastAccessDate < '20090101';
Selecting all the columns from the Users table, we get a different query plan.
uplook
The tool tip pictured above is detail from the Key Lookup operator. From the top down:
Predicate is the additional search criteria that we couldn’t satisfy with our index on Last Access Date
Object is the index being navigated (clustered primary key)
Output list is all the columns we needed from the index
Seek Predicates define the relationship between the clustered and nonclustered index, in this case the Id column
And this is how indexes talk to each other in SQL Server. Yay.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Most applications have a grace period that they’ll let queries run for before they time out. One thing that I notice people really hate is when that happens, because sometimes the effects are pretty rough.
You might have to roll back some long running modification.
Even if you have Accelerated Database Recovery enabled so that the back roll is instant, you may have have 10-30 seconds of blocking.
Or just like, unhappy users because they can’t get access to the information they want.
Monitoring for those timeouts is pretty straight forward with Extended Events.
Eventful
Here’s the event definition I used to do this. You can tweak it, and if you’re using Azure SQL DB, you’ll have to use ON DATABASE instead of ON SERVER.
CREATE EVENT SESSION
timeouts
ON SERVER
ADD EVENT
sqlserver.sql_batch_completed
(
SET collect_batch_text = 1
ACTION
(
sqlserver.database_name,
sqlserver.sql_text
)
WHERE result = 'Abort'
)
ADD
TARGET package0.event_file
(
SET filename = N'timeouts'
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = OFF
);
GO
ALTER EVENT SESSION timeouts ON SERVER STATE = START;
GO
There are a ton of other things you can add under ACTION to identify users running the queries, etc., but this is good enough to get us going.
The sql_batch_completed event is good for capturing “ad hoc” query timeouts, like you might see from Entity Framework queries that flew off the rails for some strange reason 🤔
If your problem is with stored procedures, you might want to use rpc_completed or sp_statement_completed which can additionally filter to an object_name to get you to a specific procedure as well.
Stressful
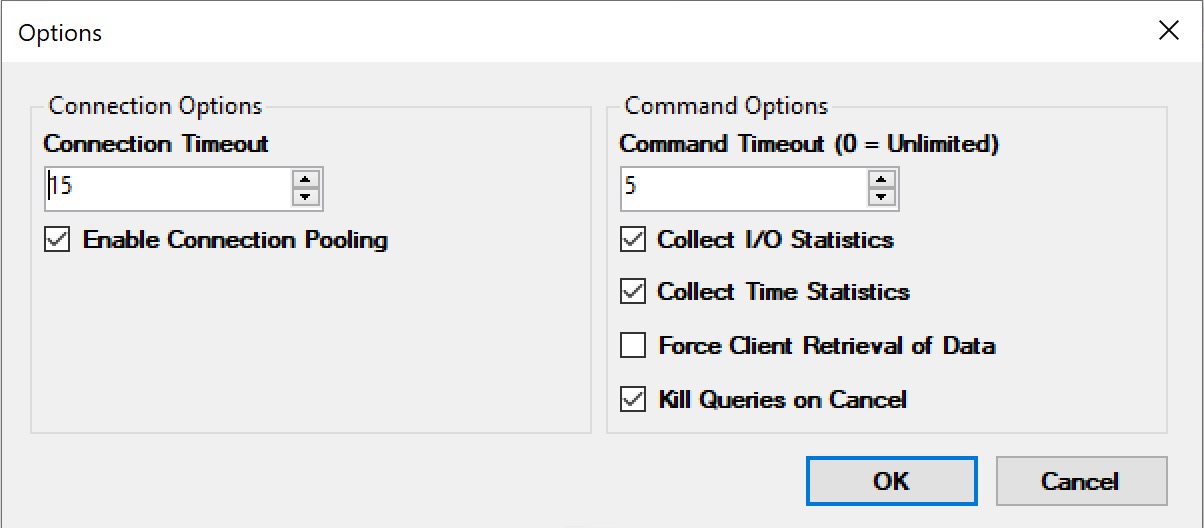
To do this, I’m going to use the lovely and talented SQL Query Stress utility, maintained by ErikEJ (b|t).
Why? Because the query timeout setting in SSMS are sort of a nightmare. In SQL Query Stress, it’s pretty simple.
command timeout
And here’s the stored procedure I’m going to use:
CREATE OR ALTER PROCEDURE
dbo.time_out_magazine
AS
BEGIN
WAITFOR DELAY '00:00:06.000';
END;
GO
Why? Because I’m lazy, and I don’t feel like writing a query that runs for 6 seconds right now.
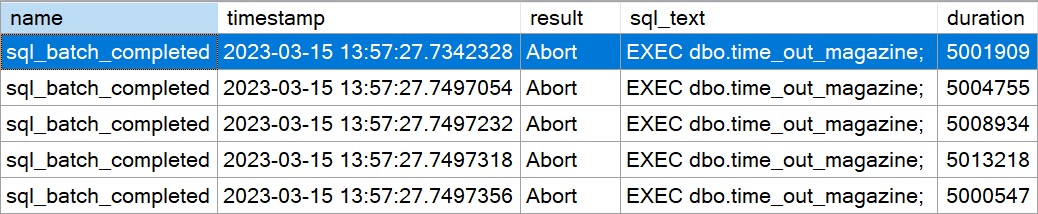
Wonderful
After a few seconds, data starts showing up in our Extended Event Session Viewer For SSMS Pro Azure Premium For Business 720.
caught!
But anyway, if you find yourself hitting query timeouts, and you want a way to capture which ones are having problems, this is one way to do that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If you take performance for your SQL Servers seriously, you should be using Query Store for your business critical databases.
I used to say this about third party monitoring tools, but the landscape for those has really tanked over the last few years. I used to really love SQL Sentry, but it has essentially become abandonware since SolarWinds bought SentryOne.
At this point, I’m happier to enable query store, and then use a couple extended events to capture blocking and deadlocks. While it would be stellar if Query Store also did that, for now life is easy enough.
To analyze blocking and deadlock Extended Events, I use:
This won’t capture absolutely everything, but that’s okay. We can usually get enough to go on with those three things. If you have bad blocking and deadlocking problems, you should start there.
But once you turn on Query Store, where do you go?
Gooey
If you’re okay with all the limitations of the GUI, you can tweak a few things to get more useful information out of it.
I usually start with the Top Resource Consuming Queries view, since, uh… those are usually good things to tune.
top resource consuming plans
But the crappy bar graph that Query Store defaults to is not what you want to see. There’s way too much jumping around and mousing over things to figure out what’s in front of you.
I like switching to the grid format with additional details view, by clicking the blue button like so:
additional details!
But we’re not done yet! Not by a long shot. The next thing we wanna do is hit the Configure button, and change what we’re looking at. See, the other crappy thing is that Query Store defaults to showing you queries by total duration.
What ends up being in here is a bunch of stuff that runs a lot, but tends to run quickly. You might get lucky and find some quick wins here, but it’s usually not where the real bangers live.
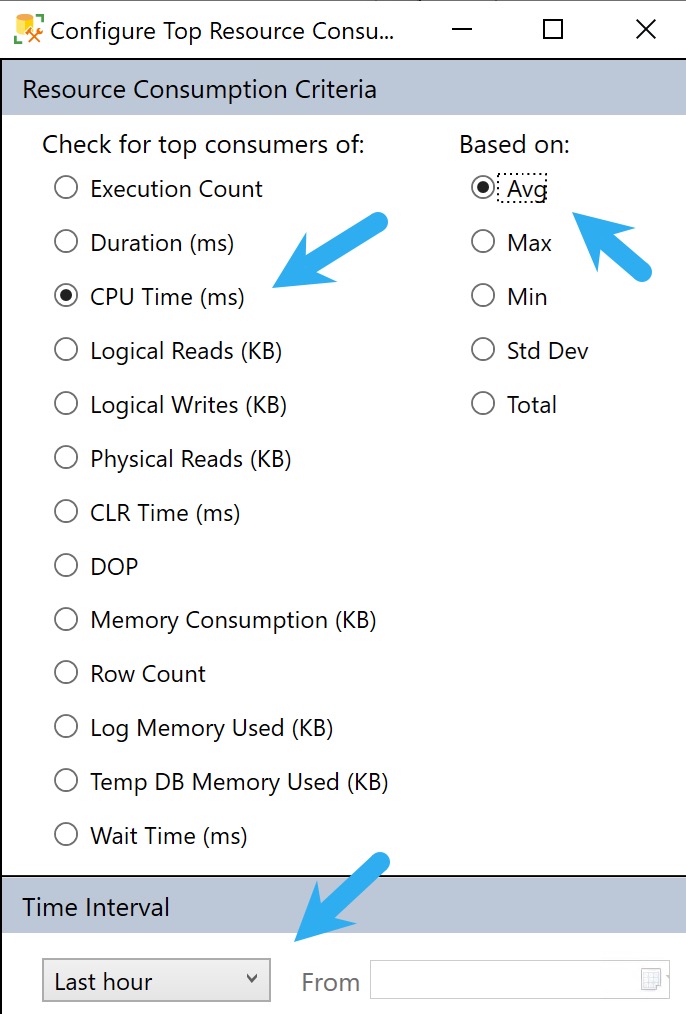
To get to those, we need to hit the Configure button and make a couple tweaks to look at queries that use a lot of CPU on average, and push the time back from only showing the last hour to the last week or so.
You can go back further, but usually the further you go back, the longer it takes to get you results.
configurator
The problem here is that you can often get back quite a bit of noise that you can’t filter out or ignore. Here’s what mine looks like:
noise noise noise
We don’t really need to know that creating indexes took a long time. Substitute those with queries you don’t necessarily care about fixing, and you get the point.
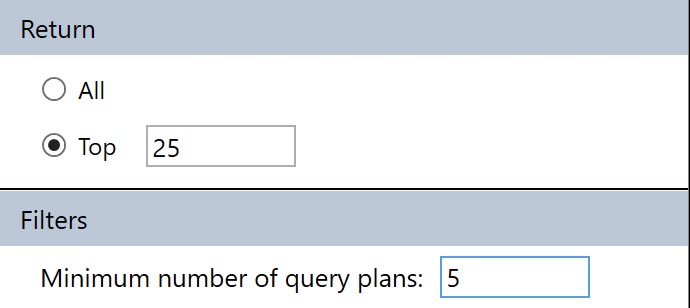
You can sort of control this by only asking for queries with a certain number of plans to come back, but if your queries aren’t parameterized and you have a lot of “single use” execution plans, you’ll miss out on those in the results.
min-maxing
This filter is available under the Configuration settings where we changes the CPU/Average/Dates before.
The major limitation of Query Store’s GUI is that you can’t search through it for specific problems. It totally could and should be in there, but as of this writing, it’s not in there.
The nice thing about sp_QuickieStore is that it gets rid of a lot of the click-clacking around to get things set up. You can’t save your Query Store GUI layout to open up and show you what you want every time, you have to redo it.
To get us to where we were with the settings above, all we have to do is this:
EXEC sp_QuickieStore
@execution_count = 5;
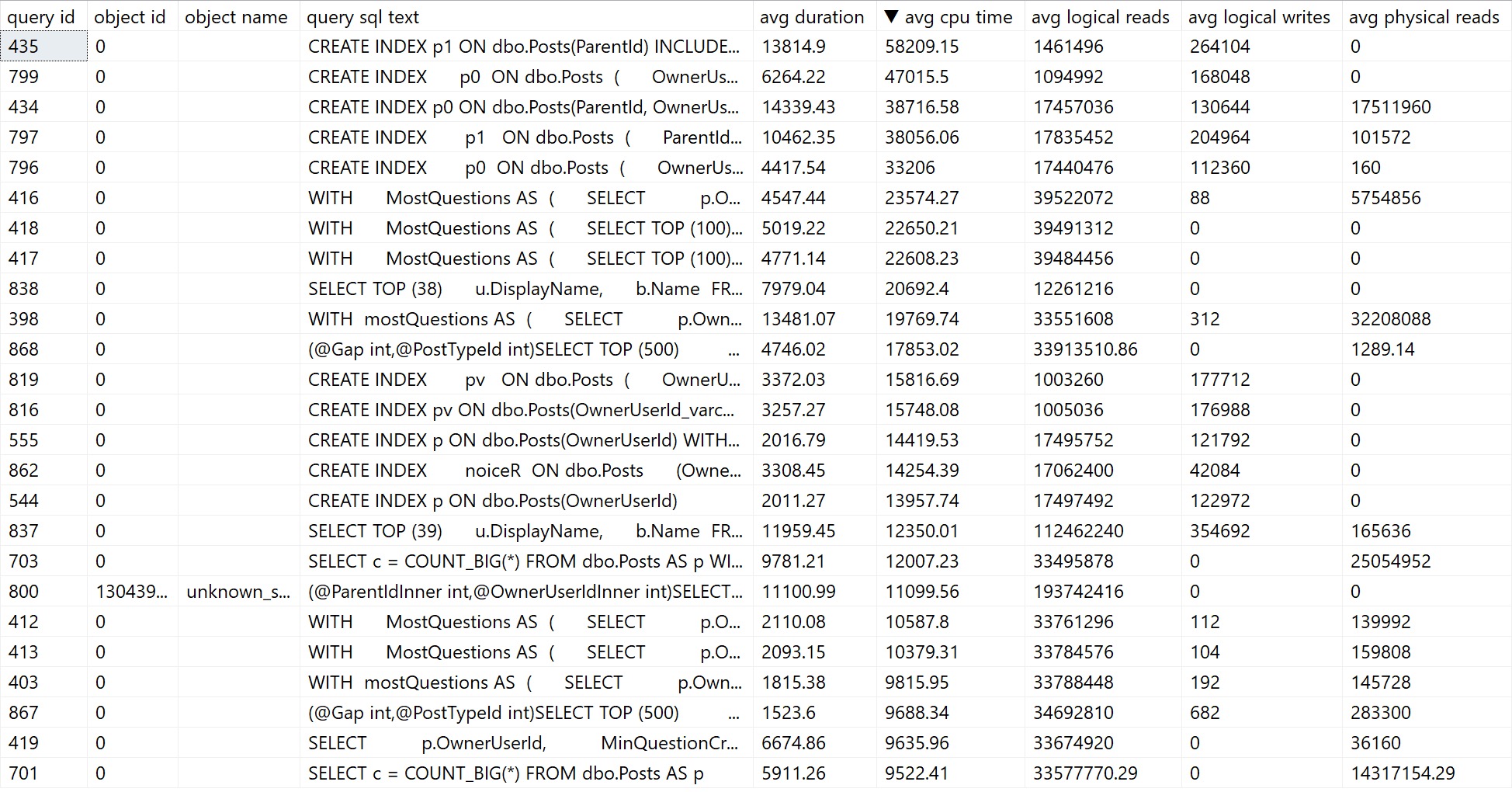
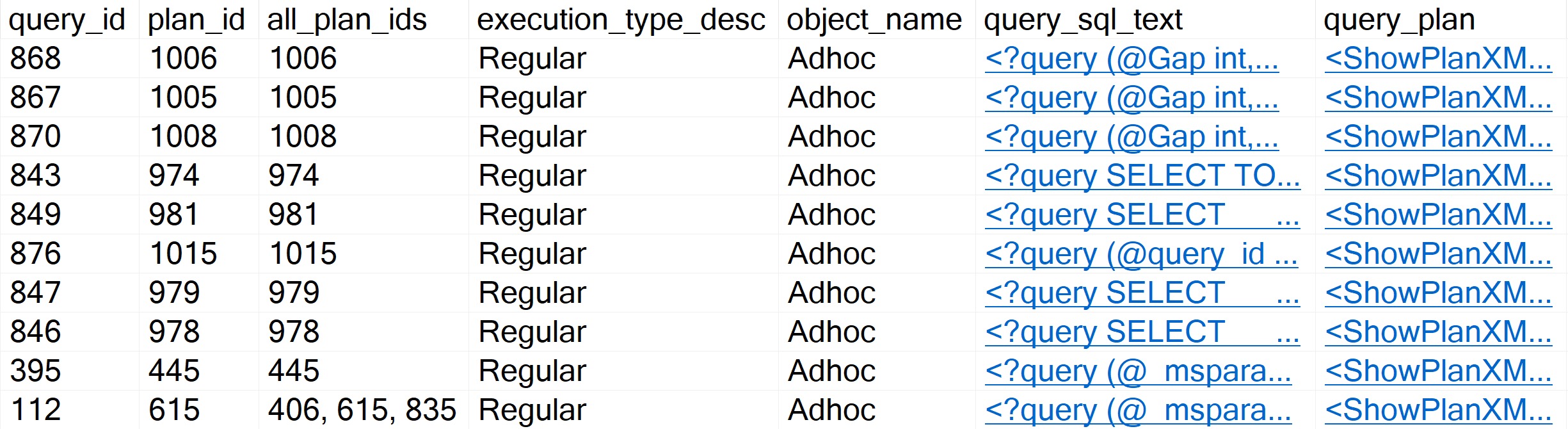
By default, sp_QuickieStore will already sort results by average CPU for queries executed over the last week of Query Store data. It will also filter out plans for stuff we can’t really tune, like creating indexes, updating statistics, and waste of time index maintenance.
You’ll get results that look somewhat like so:
to the rescue!
There are a number of things you can do with to include or ignore only certain information, too:
@execution_count: the minimum number of executions a query must have
@duration_ms: the minimum duration a query must have
@execution_type_desc: the type of execution you want to filter
@procedure_schema: the schema of the procedure you’re searching for
@procedure_name: the name of the programmable object you’re searching for
@include_plan_ids: a list of plan ids to search for
@include_query_ids: a list of query ids to search for
@ignore_plan_ids: a list of plan ids to ignore
@ignore_query_ids: a list of query ids to ignore
@include_query_hashes: a list of query hashes to search for
@include_plan_hashes: a list of query plan hashes to search for
@include_sql_handles: a list of sql handles to search for
@ignore_query_hashes: a list of query hashes to ignore
@ignore_plan_hashes: a list of query plan hashes to ignore
@ignore_sql_handles: a list of sql handles to ignore
@query_text_search: query text to search for
You straight up can’t do any of that with Query Store’s GUI. I love being able to focus in on all the plans for a specific stored procedure.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.