Yelling and Screaming

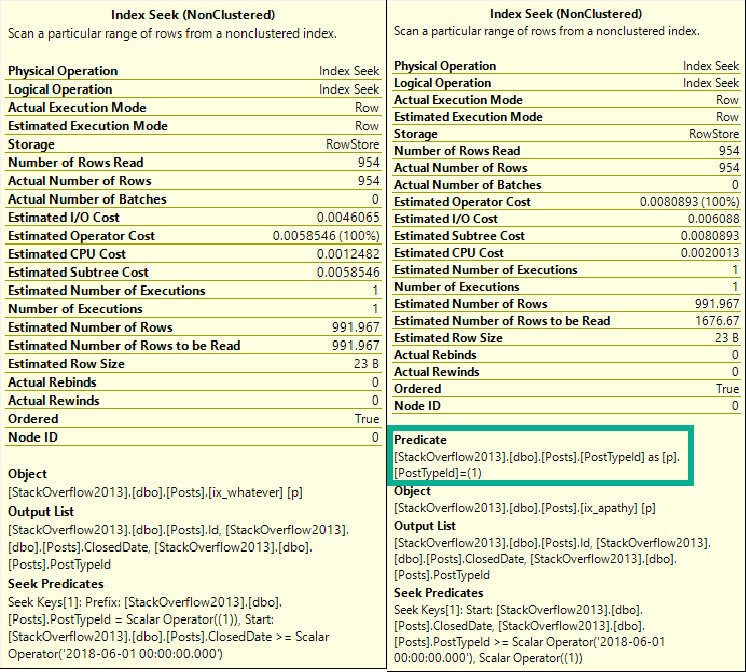
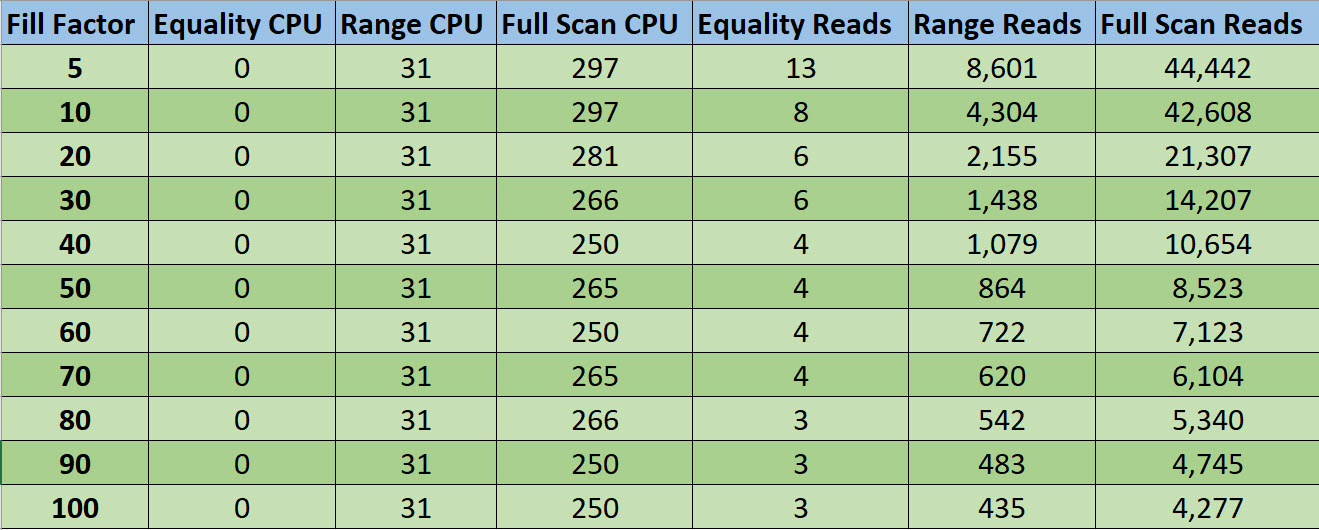
If you saw my post about parameterized TOPs, one thing you may have immediately hated is the index I created.
And rightfully so — it was a terrible index for reasons we’ll discuss in this post.
If that index made you mad, congratulations, you’re a smart cookie.
CREATE INDEX whatever ON dbo.Votes(CreationDate DESC, VoteTypeId) GO
Yes, my friends, this index is wrong.
It’s not just wrong because we’ve got the column we’re filtering on second, but because there’s no reason for it to be second.
Nothing in our query lends itself to this particular indexing scenrio.
CREATE OR ALTER PROCEDURE dbo.top_sniffer (@top INT, @vtid INT)
AS
BEGIN
SELECT TOP (@top)
v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
We Index Pretty
The reason I sometimes see columns appear first in an index is to avoid having to physically sort data.
If I run the stored procedure without any nonclustered indexes, this is our query plan:
EXEC dbo.top_sniffer @top = 1, @vtid = 1;

A sort, a spill, kablooey. We’re not having any fun, here.
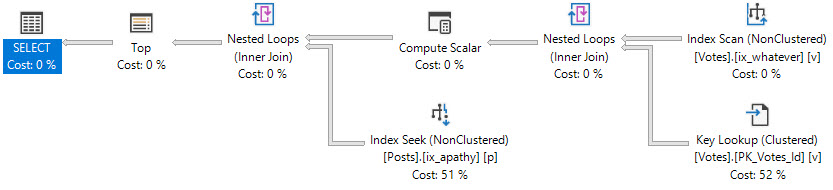
With the original index, our data is organized in the order that we’re asking for it to be returned in the ORDER BY.
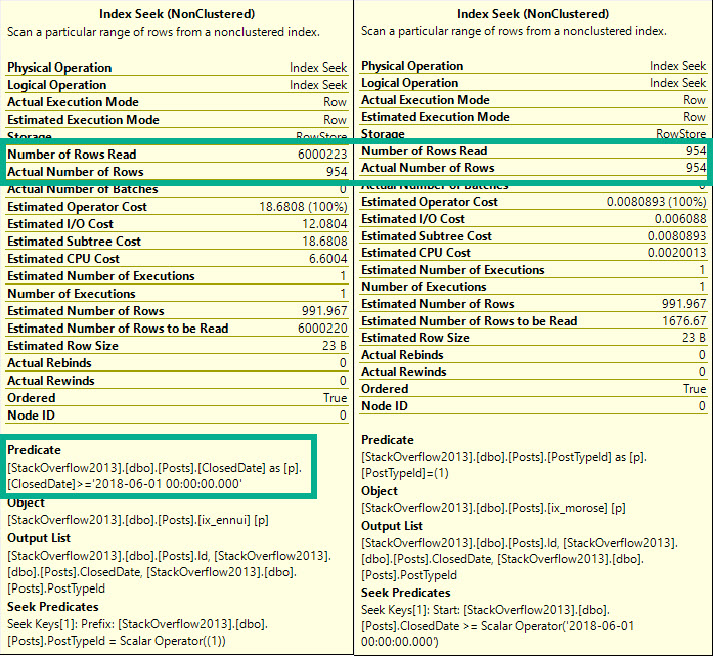
This caused all sorts of issues when we were looking for VoteTypeIds that were spread throughout the index, where we couldn’t satisfy the TOP quickly.
There was no Sort in the plan when we had the “wrong” index added.
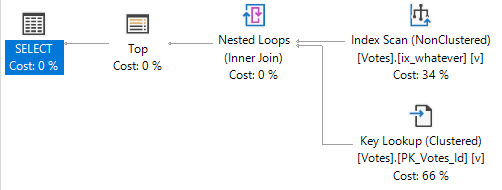
B-Tree Equality
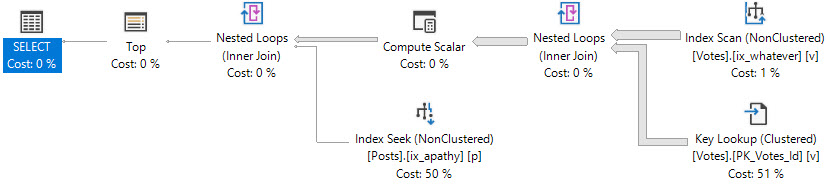
We can also avoid having to sort data by having the ORDER BY column(s) second in the key of the index, because our filter is an equality.
CREATE INDEX whatever ON dbo.Votes(VoteTypeId, CreationDate DESC) GO
Having the filter column first also helps us avoid the longer running query issue when we look for VoteTypeId 4.
EXEC dbo.top_sniffer @top = 5000, @vtid = 4;
Table 'Votes'. Scan count 1, logical reads 2262 SQL Server Execution Times: CPU time = 0 ms, elapsed time = 148 ms.
Solving for Sorts
If you’ve been following my blogging for a while, you’ve likely seen me say this stuff before, because Sorts have some issues.
- They’re locally blocking, in that every row has to arrive before they can run
- They require additional memory space to order data the way you want
- They may spill to disk if they don’t get enough memory
- They may ask for quite a bit of extra memory if estimations are incorrect
- They may end up in a query plan even when you don’t explicitly ask for them
There are plenty of times when these things aren’t problems, but it’s good to know when they are, or when they might turn into a problem.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.