If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Why is IS NULL (not to be confused with ISNULL, the function) considered an equality predicate, and IS NOT NULL considered an inequality (or range) predicate?
It seems like they should be fairly equivalent, though opposite. One tests for a lack of values, and one tests for the presence of values, with no further examination of what those values are.
The trickier thing is that we can seek to either condition, but what happens next WILL SHOCK YOU.
Ze Index
The leading column in this index is NULLable, and has a bunch of NULLs in it.
CREATE INDEX nully_baby
ON dbo.Posts(LastEditDate, Score DESC);
Knowing what we know about what indexes do to data, and since the LastEditDate column is sorted ascending, all of the NULL values will be first, and then within the population of NULLs values for Score will be sorted in descending order.
But once we get to non-NULL values, Score is sorted in descending order only within any duplicate date values. For example, there are 4000 some odd posts with a LastEditDate of “2018-07-09 19:34:03.733”.
Why? I don’t know.
But within that and any other duplicate values in LastEditDate, Score will be in descending order.
Proving It
Let’s take two queries!
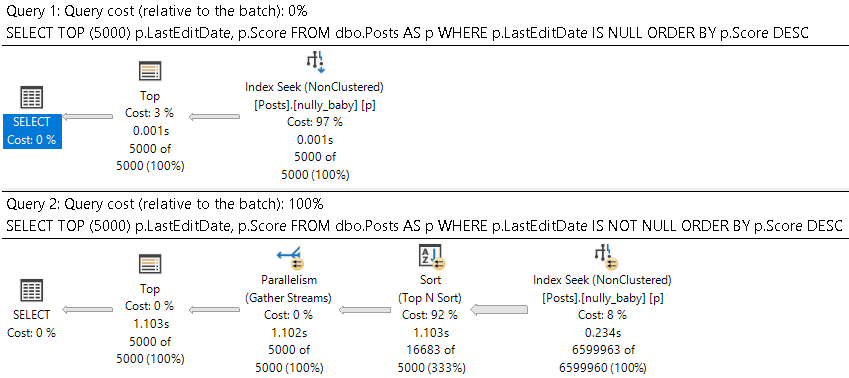
SELECT TOP (5000)
p.LastEditDate,
p.Score
FROM dbo.Posts AS p
WHERE p.LastEditDate IS NULL
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.LastEditDate,
p.Score
FROM dbo.Posts AS p
WHERE p.LastEditDate IS NOT NULL
ORDER BY p.Score DESC;
Which get very different execution plans.
you can’t get it
But Why?
I know, I know. The sort is technically non-deterministic, because Score has duplicates in it. Forget about that for a second.
For the NULL values though, Score is at least persisted in the correct order.
For the NOT NULL values, Score is not guaranteed to be in a consistent order across different date values. The ordering will reset within each group.
We’ll talk about how that works tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In this class, I’ll teach you about my strategy for tuning horrible queries, and show you practical examples for dealing with a variety of performance issues. It’s a full day of learning with no fluff.
I’ll be covering topics that you’ll face day to day, like dealing with parameter sniffing, functions, temporary objects, complex queries, and more. You’ll learn how to get to the bottom of query performance issues like a pro by getting the right information and learning how to interpret it.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Right now, the optimizer’s costing algorithm’s cost lookups as being pretty expensive.
Why? Because it’s stuck in the 90s, and it thinks that random I/O means mechanical doo-dads hopping about on a spinning platter to fetch data.
And look, I get why changes like this would be really hard. Not only would it represent a change to how costs are estimated, which could throw off a whole lot of things, but you also open potentially more queries up to parameter sniffing issues.
Neither of those prospects are great, but I hear from reliable sources that Microsoft “hope[s] to make parameter sniffing less of a problem for customers” in the future.
In the meantime, what do I mean?
Kiss of Death
Scanning clustered indexes can be painful. Not always, of course, but often enough that it’s certainly something to ask questions about in OLTP-ish queries.
Let’s use the example query from yesterday’s blog post again, with a couple minor changes, and an index.
CREATE INDEX unusable
ON dbo.Posts(OwnerUserId, Score DESC, CreationDate, LastActivityDate)
INCLUDE(PostTypeId);
Let’s run this hyper-realistic query, with slightly different dates in the where clause.
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130927'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130928'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
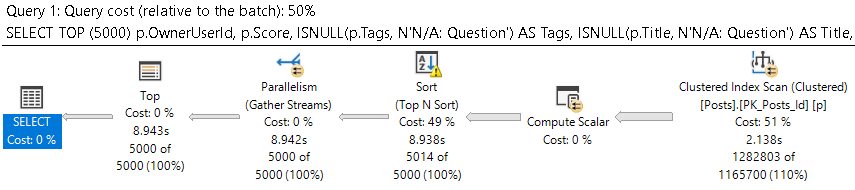
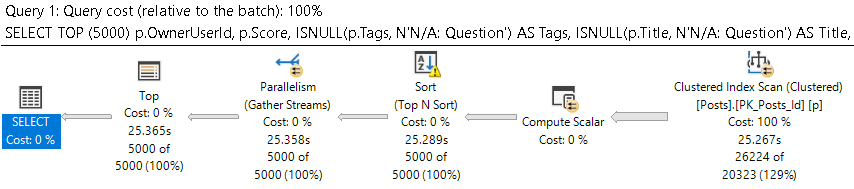
The query plan for the first query looks like this:
optimal, sub
We scan the clustered index, and the query as a whole takes around 9 seconds.
Well, okay.
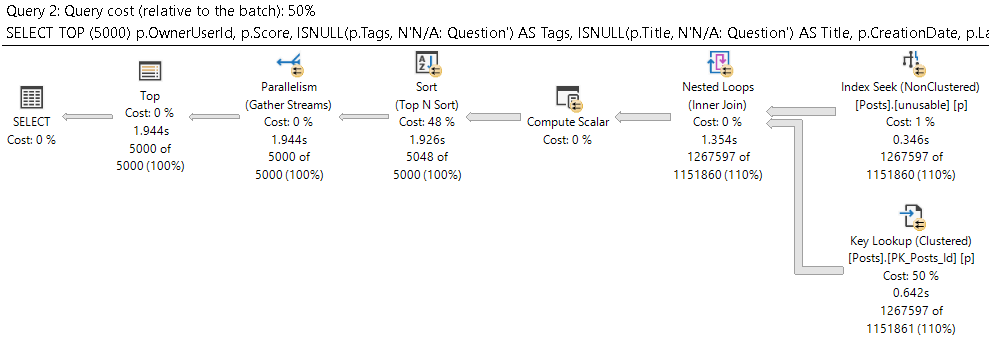
What about the other query plan?
mwah
That runs about 7 seconds faster. But why?
Come Clean
There’s one of those ✌tipping points✌ you may have heard about. One day. What a difference, huh?
Let’s back up to the first query.
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130927'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p WITH(INDEX = unusable)
WHERE p.OwnerUserId IS NOT NULL
AND p.CreationDate >= '20130927'
AND p.LastActivityDate < '20140101'
ORDER BY p.Score DESC;
There’s no way one day should make this thing 7 seconds slower, so we’re going to hint one copy of it to the use nonclustered index.
How do we do there?
i’m lyin’
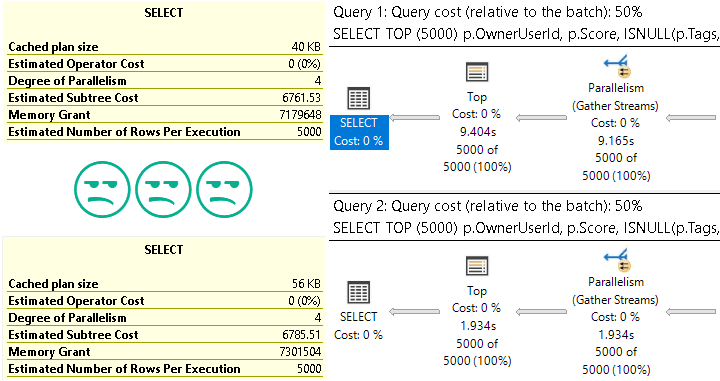
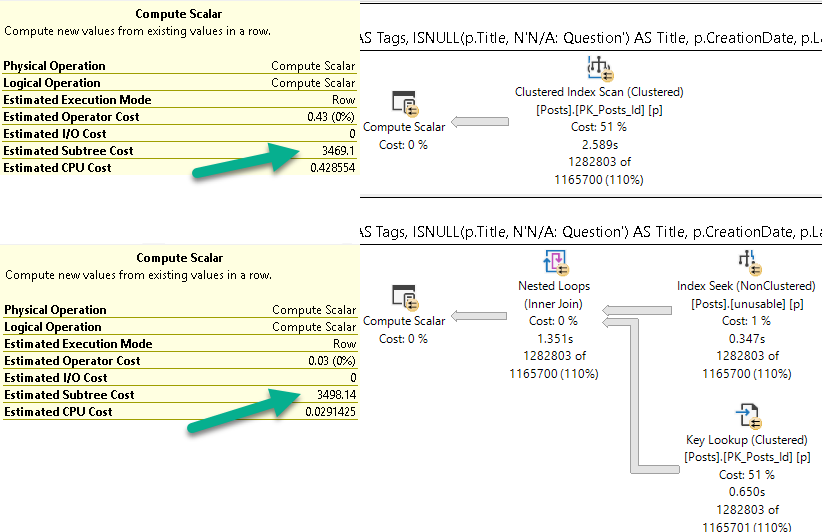
The much slower plan has a lower cost. The optimizer gave the seek + lookup a higher cost than the scan.
If we look at the subtree cost of the first operator, you’ll see what I mean.
pina colada
Zone Out
You may hear people talk about costs, either of query plans, or of operators, that indicate what took the most time. This is unfortunately not quite the case.
Note that there are no “actual cost” metrics that get calculated and added to the plan later. The estimates remain with no counterparts.
You can answer some common questions this way:
Why didn’t my index get chosen? The optimizer thought it’d be more work
How did it make that choice? Estimated costs of different potential plans
Why was the optimizer wrong? Because it’s biased against random I/O.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The problem with relying on any data point is that when it’s not there, it can look like there’s nothing to see.
Missing indexes requests are one of those data points. Even though there are many reasons why they might not be there, sometimes it’s not terribly clear why one might not surface.
That can be annoying if you’re trying to do a general round of tuning on a server, because you can miss some easy opportunities to make improvements.
Here’s an example of a query that, with no indexes in place, probably should generate a missing index request.
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate,
p.Body
FROM dbo.Posts AS p
WHERE 1 = 1
AND p.CreationDate >= '20131230'
AND p.CreationDate < '20140101'
ORDER BY p.Score DESC;
Big Ol’ Blank
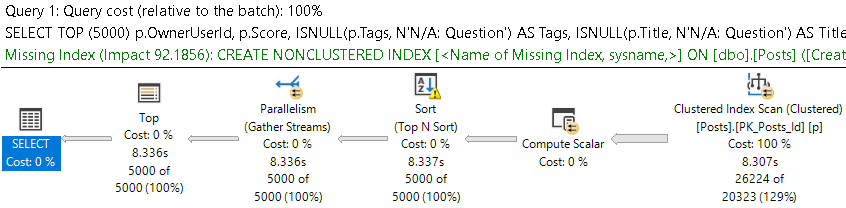
Here’s the query plan! It’s like uh. Why wouldn’t you want this to take less than 25 seconds?
clap your hands
The posts table is a little over 17 million rows. The optimizer expects around 20k rows to qualify, but doesn’t think an easier way to find those rows would be helpful.
At least not the way we’ve written the query.
Let’s make a small change
Five and Dime
If we quote out the Body column, which is an NVARCHAR(MAX), we get our green text.
SELECT TOP (5000)
p.OwnerUserId,
p.Score,
ISNULL(p.Tags, N'N/A: Question') AS Tags,
ISNULL(p.Title, N'N/A: Question') AS Title,
p.CreationDate,
p.LastActivityDate--,
--p.Body
FROM dbo.Posts AS p
WHERE 1 = 1
AND p.CreationDate >= '20131230'
AND p.CreationDate < '20140101'
ORDER BY p.Score DESC;
Who’d want that in an index?
Which is interesting, because the optimizer isn’t always that smart. It’s much easier to tempt it into bad ideas with equality predicates.
Good and Hard
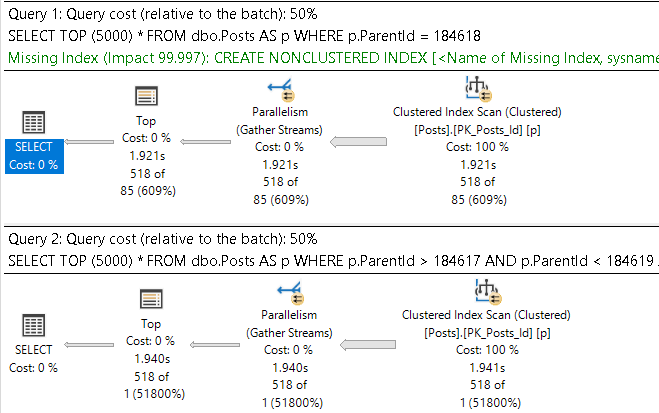
Check this out!
SELECT TOP (5000) *
FROM dbo.Posts AS p
WHERE p.ParentId = 184618;
SELECT TOP (5000) *
FROM dbo.Posts AS p
WHERE p.ParentId > 184617
AND p.ParentId < 184619;
hot cars
The missing index for this is a mistake.
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Posts] ([ParentId])
INCLUDE ([AcceptedAnswerId],[AnswerCount],[Body],[ClosedDate],[CommentCount],[CommunityOwnedDate],[CreationDate],[FavoriteCount],[LastActivityDate],[LastEditDate],[LastEditorDisplayName],[LastEditorUserId],[OwnerUserId],[PostTypeId],[Score],[Tags],[Title],[ViewCount])
What Did We Learn?
How we write queries (and design tables) can change how the optimizer feels about our queries. If you’re the kind of person who relies on missing index requests to fix things, you could be missing pretty big parts of the picture.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In this class, I’ll teach you about my strategy for tuning horrible queries, and show you practical examples for dealing with a variety of performance issues. It’s a full day of learning with no fluff.
I’ll be covering topics that you’ll face day to day, like dealing with parameter sniffing, functions, temporary objects, complex queries, and more. You’ll learn how to get to the bottom of query performance issues like a pro by getting the right information and learning how to interpret it.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I was investigating a query slowdown recently, and came across something kind of odd with windowing functions and order by.
Let’s talk about these three queries:
SELECT u.DisplayName,
ROW_NUMBER() OVER (ORDER BY u.UpVotes) AS UpVotesWhatever, --UpVotes first
ROW_NUMBER() OVER (ORDER BY u.DownVotes) AS DownVotesWhatever --DownVotes second
FROM dbo.Users AS u
WHERE u.Reputation > 100000
ORDER BY UpVotes; --Order by UpVotes
SELECT u.DisplayName,
ROW_NUMBER() OVER (ORDER BY u.UpVotes) AS UpVotesWhatever, --UpVotes first
ROW_NUMBER() OVER (ORDER BY u.DownVotes) AS DownVotesWhatever --DownVotes second
FROM dbo.Users AS u
WHERE u.Reputation > 100000
ORDER BY u.DownVotes; --Order by DownVotes
SELECT u.DisplayName,
ROW_NUMBER() OVER (ORDER BY u.DownVotes) AS DownVotesWhatever, --DownVotes first
ROW_NUMBER() OVER (ORDER BY u.UpVotes) AS UpVotesWhatever --UpVotes second
FROM dbo.Users AS u
WHERE u.Reputation > 100000
ORDER BY UpVotes; --Order by UpVotes
Goings On
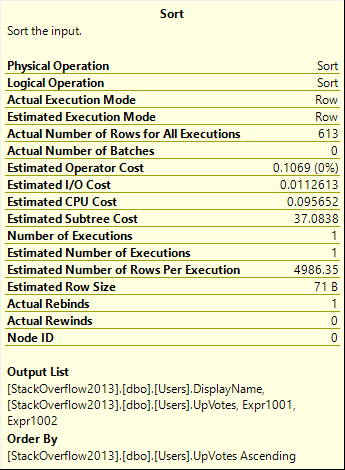
If we’re going to generate row numbers on these columns, we need to sort them.
I know and you know, we can add indexes to put column data in the order we want it in, and that’ll cut down on the amount of work Our Server™ has to do to execute this query. But we can’t just index everything, that’d be insane. I know because I’ve seen your servers, and I’ve seen you try to do that.
Plus, they just get fragmented anyway.
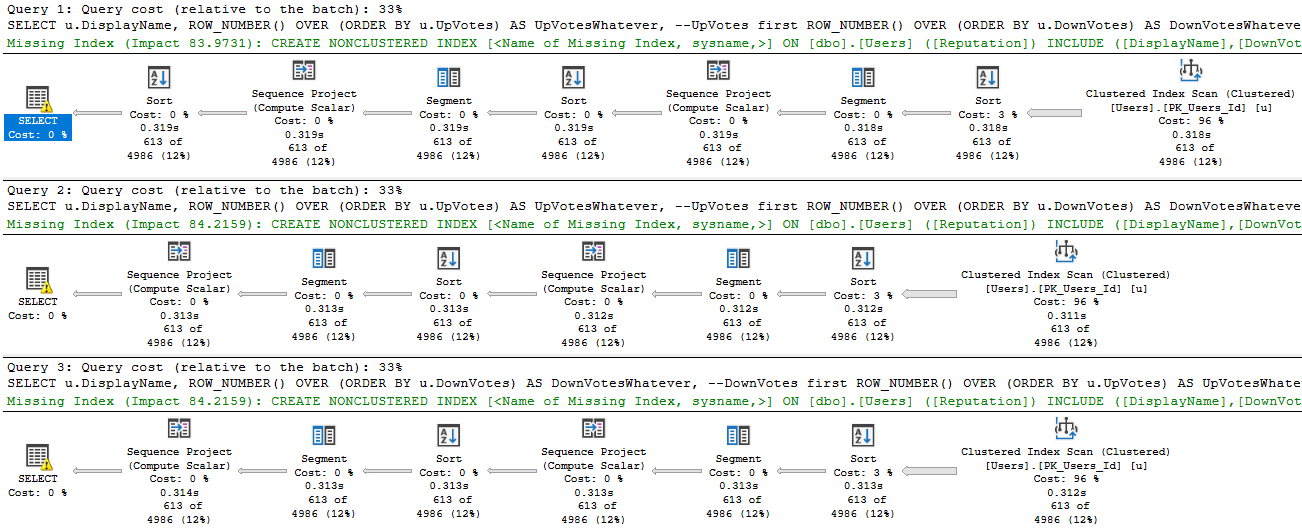
Here are the execution plans. This is a big picture, because I want you to spot the difference.
get big
Fascination Street
That first plan has an extra Sort operator in it. See it up there? Right next to the Select operator?
shame on you
That sort is ordering by UpVotes ascending, which is a shame because we’ve already done that once. That sort doesn’t occur in the second two plans, because the row number function has already sorted data by them. If the optimizer were a little smarter here, it could reorder the sequence it generates row numbers in to avoid that, but it doesn’t.
If we rewrite the query to do that on our own, the data ends up in the right order. In case you’re wondering, we get the same results referencing the row numbers in the order by instead of the underlying column:
SELECT u.DisplayName,
ROW_NUMBER() OVER (ORDER BY u.UpVotes) AS UpVotesWhatever, --UpVotes first
ROW_NUMBER() OVER (ORDER BY u.DownVotes) AS DownVotesWhatever --DownVotes second
FROM dbo.Users AS u
WHERE u.Reputation > 100000
ORDER BY UpVotesWhatever; --Order by UpVotesWhatever
SELECT u.DisplayName,
ROW_NUMBER() OVER (ORDER BY u.UpVotes) AS UpVotesWhatever, --UpVotes first
ROW_NUMBER() OVER (ORDER BY u.DownVotes) AS DownVotesWhatever --DownVotes second
FROM dbo.Users AS u
WHERE u.Reputation > 100000
ORDER BY DownVotesWhatever; --Order by DownVotesWhatever
SELECT u.DisplayName,
ROW_NUMBER() OVER (ORDER BY u.DownVotes) AS DownVotesWhatever, --DownVotes first
ROW_NUMBER() OVER (ORDER BY u.UpVotes) AS UpVotesWhatever --UpVotes second
FROM dbo.Users AS u
WHERE u.Reputation > 100000
ORDER BY UpVotesWhatever; --Order by UpVotesWhatever
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
WHAT DO YOU MEAN YOU’RE NOT ON SQL SERVER 2019 YET.
Oh. Right.
That.
Regressed
Look, whenever you make changes to the optimizer, you’re gonna hit some regressions.
And it’s not just upgrading versions, either. You can have regressions from rebuilding or restarting or recompiling or a long list of things.
Databases are terribly fragile places. You have to be nuts to work with them.
I’m not mad at 2019 or Batch Mode On Rowstore (BMOR) or anything.
But if I’m gonna get into it, I’m gonna document issues I run into so that hopefully they help you out, too.
One thing I ran into recently was where BMOR kicked in for a query and made it slow down.
Repro
Here’s my index:
CREATE INDEX mailbag ON dbo.Posts(PostTypeId, OwnerUserId) WITH(DATA_COMPRESSION = ROW);
And here’s my query:
SELECT u.Id, u.DisplayName, u.Reputation,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pq WHERE pq.OwnerUserId = u.Id AND pq.PostTypeId = 1) AS q_count,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pa WHERE pa.OwnerUserId = u.Id AND pa.PostTypeId = 2) AS a_count
FROM dbo.Users AS u
WHERE u.Reputation >= 25000
ORDER BY u.Id;
It’s simplified a bit from what I ran into, but it does the job.
Batchy
This is the batch mode query plan. It runs for about 2.6 seconds.
who would complain?
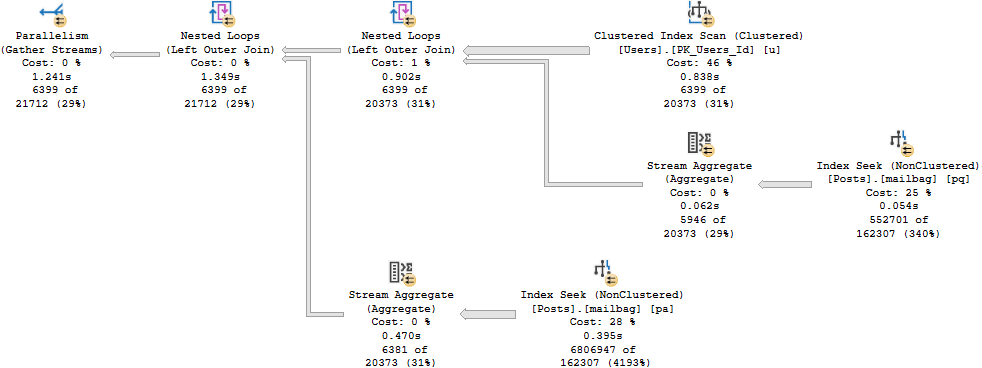
Rowy
And here’s the row mode query plan. It runs for about 1.3 seconds.
oh that’s why.
What Happened?
Just when you think the future is always faster, life comes at you like this.
So why is the oldmode query more than 2x faster than the newhotmode query?
There are a reason, and it’s not very sexy.
Batch Like That
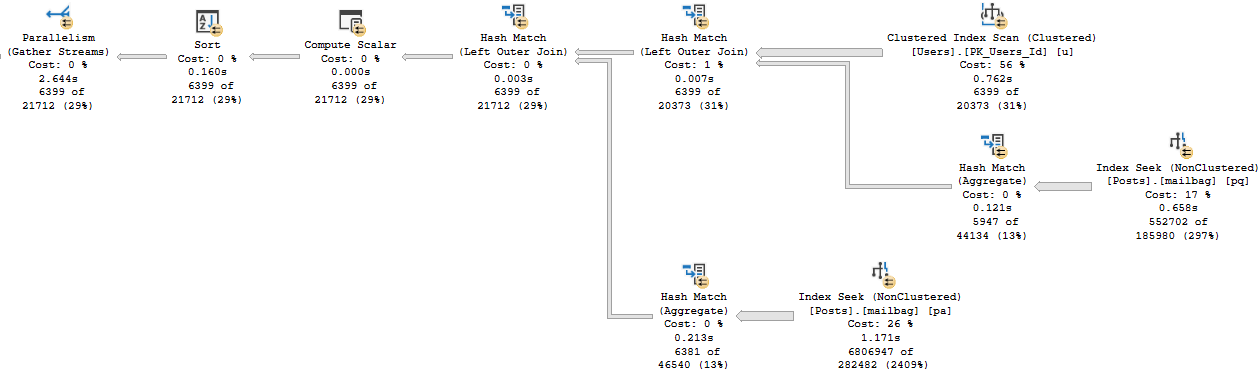
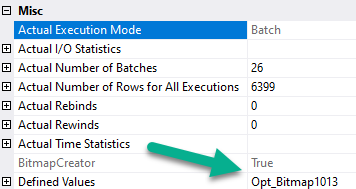
First, the hash joins produce Bitmaps.
bitted
You don’t see Bitmaps in Batch Mode plans as operators like you’re used to in Row Mode plans. You have to look at the properties (not the tool tip) of the Hash Join operator.
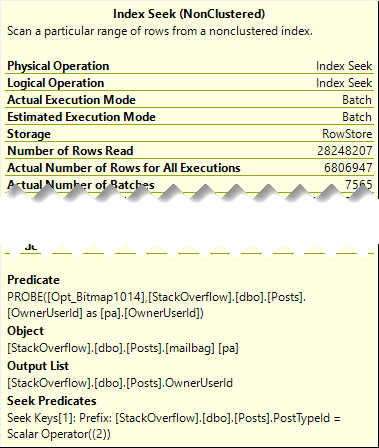
Even though both plans seek into the index on Posts, it’s only for the PostTypeId in the Batch Mode plan.
It would be boring to show you both, so I’m just going to use the details from the branch where we find PostTypeId = 2.
buck fifty
Remember this pattern: we seek to all the values where PostTypeId = 2, and then apply the Bitmap as a residual predicate.
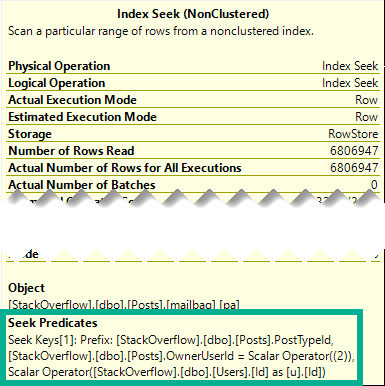
Which means on the inner side of the join, both the PostTypeId and the OwnerUserId qualify as seek predicates:
oh yeah that
Reading Rainbow
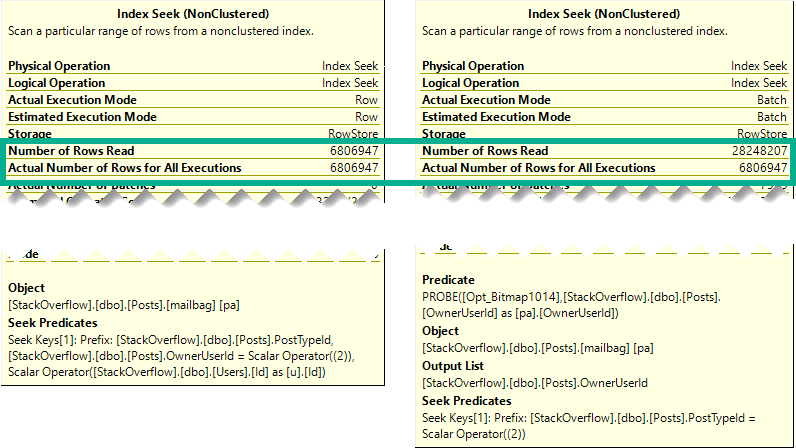
The better performance comes from doing fewer reads when indexes are accessed.
psychic tv
Though both produce the same number of rows, the Hash Join plan in Batch Mode reads 28 million rows, or about 21 million more rows than the Nested Loop Join plan in row mode. In this case, the double seek does far fewer reads, and even Batch Mode can’t cover that up.
Part of the problem is that the optimizer isn’t psychic.
Fixing It
There are two ways I found to get the Nested Loop Join plan back.
The boring one, using a compat level hint:
SELECT u.Id, u.DisplayName, u.Reputation,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pq WHERE pq.OwnerUserId = u.Id AND pq.PostTypeId = 1) AS q_count,
(SELECT COUNT_BIG(*) FROM dbo.Posts AS pa WHERE pa.OwnerUserId = u.Id AND pa.PostTypeId = 2) AS a_count
FROM dbo.Users AS u
WHERE u.Reputation >= 25000
ORDER BY u.Id
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
And the more fun one, rewriting the correlated subqueries as outer apply:
SELECT u.Id, u.DisplayName, u.Reputation, q_count, a_count
FROM dbo.Users AS u
OUTER APPLY(SELECT COUNT_BIG(*) AS q_count FROM dbo.Posts AS pq WHERE pq.OwnerUserId = u.Id AND pq.PostTypeId = 1) AS q_count
OUTER APPLY(SELECT COUNT_BIG(*) AS a_count FROM dbo.Posts AS pa WHERE pa.OwnerUserId = u.Id AND pa.PostTypeId = 2) AS a_count
WHERE u.Reputation >= 25000
ORDER BY u.Id;
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’m often frustrated by things that are either not implemented well, or at all, in SQL Server. I don’t want to make a list here, because I don’t want to dissuade anyone from commenting, but here’s a picture of me reading it.
AND THEN
And yes, the grass may always be greener on other platforms. Oracle and Postgres have some pretty amazing things in them that I think could solve some pretty big problems, and fill some pretty big holes for developers.
Anyway, this post is about you, dear reader.
If you could design your ideal database to work with, what would you do differently than what SQL Server does?
Thanks for reading (and hopefully commenting)!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.