Without fail, I seem to have this conversation every week:
Why is this a heap?
The vendor doesn’t like clustered indexes.
Ah, okay, why?
I don’t know.
There’s a nonclustered primary key, though…
Isn’t that the default?
No, you have to go out of your way to choose that.
Wann Ist Es
Heaps aren’t always bad, but you have to be careful when you choose to use them, because the problems that sneak up with them are tricky to detect and annoying to fix. If you never run into them, great.
But if you do, try to keep an open mind. Clustered indexes work wonderfully for a great many people, and it’s unlikely that you fall far out of that category, especially if you have anything within a horseshoe or hand grenade from an OLTP workload.
When I look at client workloads that have problems with heaps, the main things that I call out are either:
Forwarded fetches that result in uneven I/O patterns
Captive pages from tiny deletes that don’t remove empty pages
Rather than go on and on about this stuff, here are a couple videos where I discuss the downsides and upsides of heaps. Normally they’re part of my paid training, but I’m making them available here to you for free:
To find tables that might need clustered indexes, a good, free tool is sp_BlitzIndex. It’s part of an open source project that I’ve spent a lot of time on. It’ll warn you about heaps that have forwarded records in them, and that have been deleted from. From there, it’s up to you to figure out if the table is big and critical enough to warrant adding a clustered index to.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Like many things, applications tend to evolve over time. New and improved functionality, Bug Fixed And Performance Improvements™, and ever expanding schema usually lead to new queries or tweaks to existing ones.
When designing new queries, creating or tweaking indexes to help them along is perhaps a bit more intuitive, depending on how comfortable you are with such things. If you’re starting from near-zero there, check the link at the end of my post for 75% off of my video training. I’ll teach you how to design effective indexes.
One of the more common issues I see is that someone tweaked a query to support new functionality, and it just happened to use indexes well-enough in a development environment that’s much smaller than real customer deployments.
In these cases, a better index may not be recommended by SQL Server. If it’s not obvious to the optimizer, it may also not be obvious to you, either. No offense.
All Devils
Let’s say we have this query. It’s nothing magnificent, but it’s enough to prove a couple points.
CREATE INDEX c ON dbo.Comments(CreationDate, UserId);
SELECT TOP (1000)
C.CreationDate,
C.Score,
C.Text,
DisplayName =
(
SELECT
U.DisplayName
FROM dbo.Users AS U
WHERE U.Id = C.UserId
)
FROM dbo.Comments AS C
WHERE C.CreationDate >= '20131215'
ORDER BY C.CreationDate DESC;
Our index serves three purposes:
The predicate on CreationDate
The order by on CreationDate
The correlated subquery on UserId
It’s important to keep things like this in mind, that sorted data is useful for making more efficient.
Let’s Go
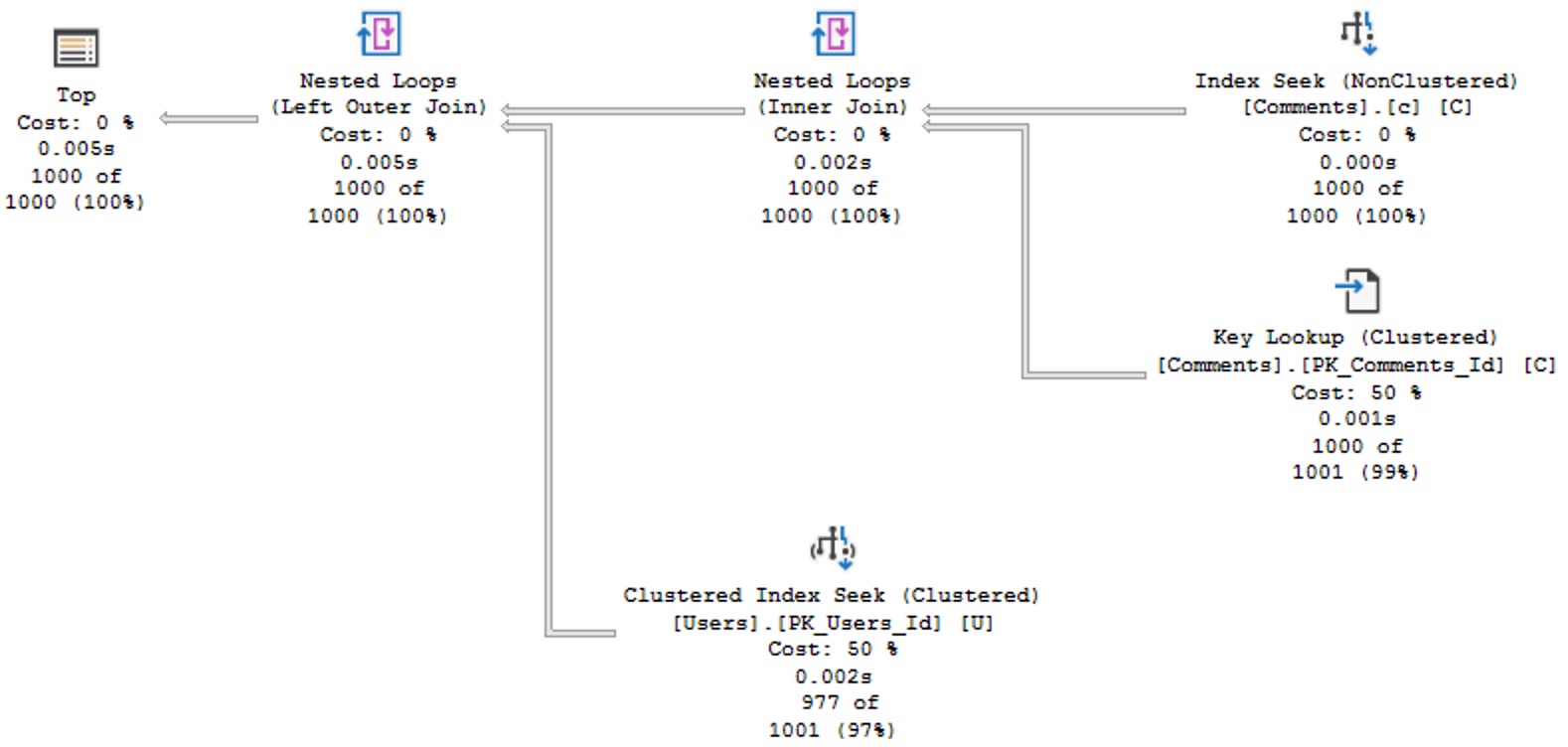
The query plan for this is quite simple and efficient.
no problems
It’s hard to ask for anything faster, here, even if I am running on a VM. Two seeks, a small lookup, and everything done in 5 milliseconds.
Wolves At
But then one day a pull request comes along that changes the query slightly, to let us also filter and order by the Score column.
It looks like this now:
SELECT TOP (1000)
C.CreationDate,
C.Score,
C.Text,
DisplayName =
(
SELECT
U.DisplayName
FROM dbo.Users AS U
WHERE u.Id = C.UserId
)
FROM dbo.Comments AS C
WHERE C.CreationDate >= '20131215'
AND C.Score >= 8
ORDER BY
C.CreationDate DESC,
C.Score DESC;
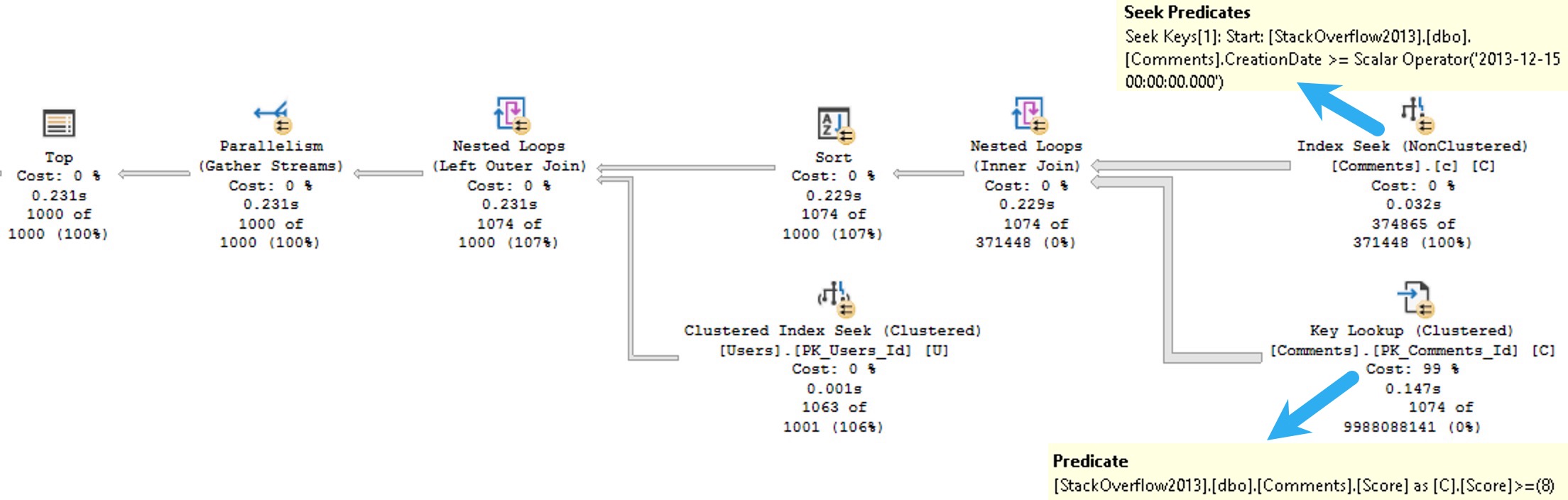
In real life, if you’re smart, your queries will be parameterized. In this blog post, these values are to show you what can happen even with small changes to a query. The query plan looks like this now:
MPR
Arf Arf
We still seek into our nonclustered index to search for CreationDates that pass our predicate, but now we need to evaluate the Score predicate when we do our key lookup.
Rather than just get 1000 rows out immediately, we need to keep findings rows that pass the CreationDate predicate, but that also pass the Score predicate.
Since that’s judged by the optimizer to be a much more “expensive” task, and a parallel plan is chosen. Despite that, it still takes 231 milliseconds of duration, with 844 milliseconds of CPU time.
This could have many effects on the workload, depending on how frequently a query executes within the workload. Parallel queries use more CPU threads, which can get tricky under high concurrency, since they’re a finite resource based on CPU count.
We can save a lot of the problems here with a slightly adjusted index, like this:
CREATE INDEX c ON dbo.Comments(CreationDate, Score, UserId);
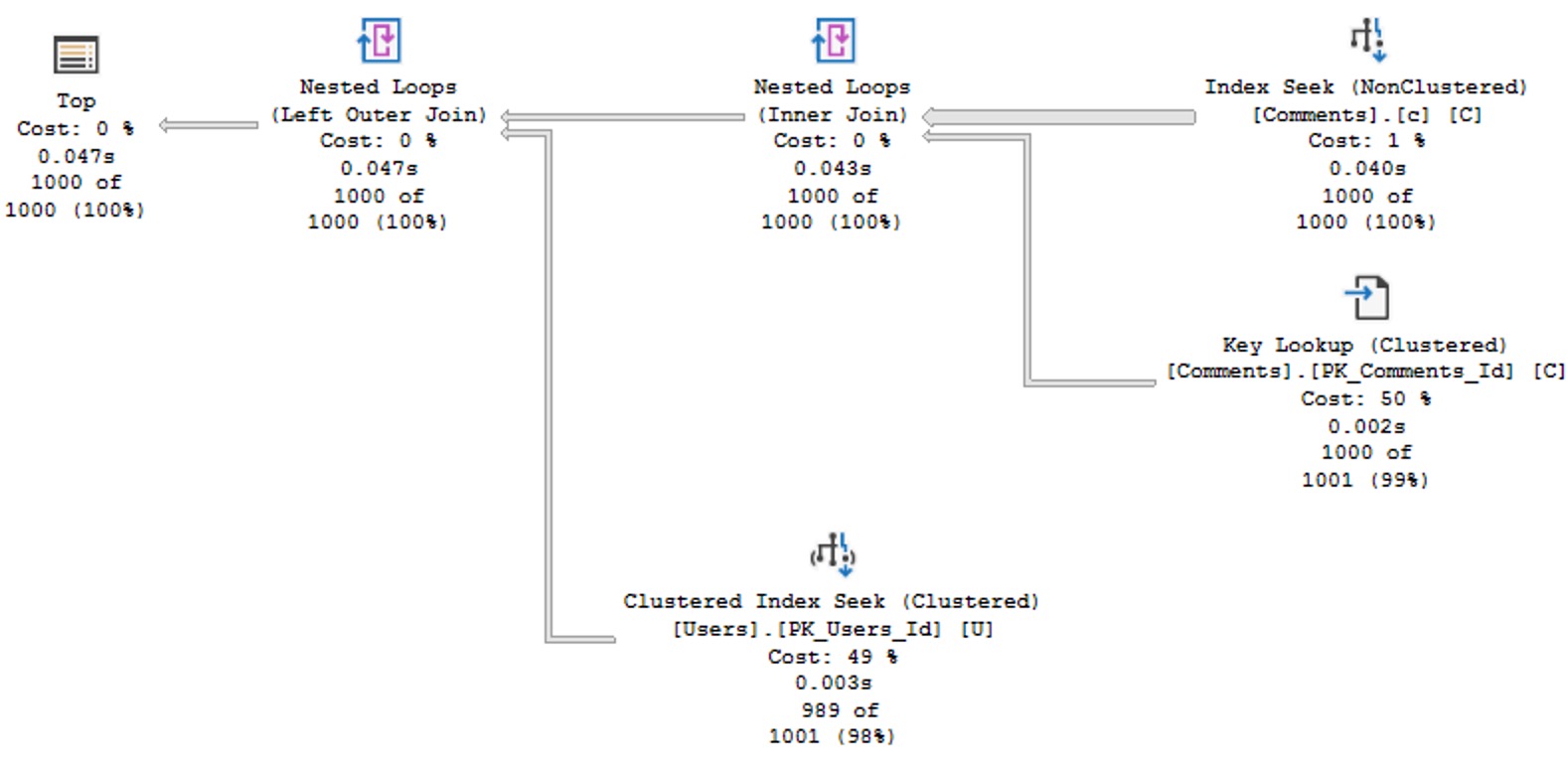
Delicious
With that index in place, we get a much more efficient plan back, that doesn’t need to go parallel to stay competitively fast. It’s not quite as fast as the original query, but it’s Good Enough™.
get bomb
Cheese Wants
I know you’re all smart folks out there, and you’re going to have questions about the index I created, and why the columns are in the order they’re in.
If you have a copy of the StackOverflow2013 database, you might do some poking around and find that there are 374,865 rows that pass our CreationDate predicate, and only 122,402 that pass our Score filter, making Score more selective for this version of the query.
But that’s just this one execution, and things could be a lot different depending on what users filter on. The big advantage to keeping the columns in this order is that the order by remains supported. Without that, the optimizer goes back to choosing a parallel plan, and asking for a memory grant.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Building on yesterday’s post about cleaning up old indexes: Once you’ve gotten rid of indexes that aren’t used anymore, you’re gonna have some more work to do. I know, it sucks, but hopefully it won’t be too difficult or confusing. If it is, hit the link at the end of the post to drop me a line for some consulting help.
The next thing I usually do is look for nonclustered indexes that have overlapping columns in the key to merge together.
Here are two basic patterns to look at, in order of how useful they are to us currently:
Key columns are an exact match
Key columns are super/sub-sets of other indexes
Key columns match to a point, but then differ
Key columns are the same, but in a different order
For the second two, I put those aside at first. Remember that we already got rid of indexes that aren’t used at all to make queries go faster, so now we’re left with indexes that do get used (though how much will vary dramatically from database to database).
Order Is Everything
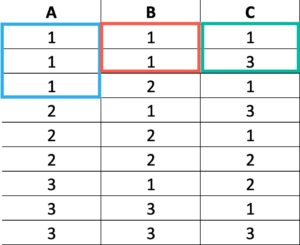
Key column order matters to us, because it defines how queries can access data in the index. Let’s take an imaginary index keyed on columns (A, B, C).
If you want to search on:
A: Fast
A, B: Fast:
A, B, C: Fast
B: Slower
B, C: Slower
C: Slower
Column A being the leading key column in the index means that index data is sorter first by column A. If there are any duplicates in there, then column B will be sorted within that group.
One way to visualize that is like this:
toughen up
Finding any value(s) in column A is easy, because they’re in sorted order. But finding values in any combination of B/C means we have to scan through all the values to find ones we care about, if we’re not also searching on A.
If we have indexes on
A, B, C
B, A C
Are they identical? Maybe sorta kinda. This is where domain knowledge about your application comes into play, and knowing if queries most often filter on A or B, and which queries are more important to the workload. If you’re not sure, leave’em both alone for now.
Definitional
Let’s say you have a bunch of indexes from the first two categories, where the key columns might look something like this:
Duplicates:
Key: A, B Includes (D, E)
Key: A, B Includes (D, E, F, G)
Super/sub-sets:
Key: D, E Includes (A, B)
Key: D, E, F Includes (A, B, C)
There are some other things we need to consider about the indexes:
Included columns: Can be merged safely; order doesn’t mater
Only stored at the leaf level, not ordered
Uniqueness: Can only be preserved for exact key matches
Unique D, E is different from D, E, F
Filters: Look at usage metrics to figure out these
A filtered may not be useful to all queries, especially when parameterized
Practical
In theory, wider indexes are better indexes, because they’re more useful to more queries.
With indexes that fully cover all the columns our queries reference, we don’t need to worry about the optimizer sometimes choosing our index and sometimes choosing the clustered index depending on how many rows it thinks it’s going to have to deal with.
That’s generally a positive, but there are some caveats:
Indexing columns that are updated frequently can exacerbate locking and deadlocking
Indexing max columns over and over again can really bloat out our database
Indexing to include every column in the table creates whole copies of the table
You have to strike a careful balance with indexes. Enough, but not too many. Covering, but not in a counterproductive way.
To find indexes that can be removed because they’re overlapping, a good, free tool is sp_BlitzIndex. It’s part of an open source project that I’ve spent a lot of time on. It’ll warn you about indexes that are exact and borderline duplicates, so that you can start looking at which are safe to merge together.
In some posts to follow, we’ll cover index design strategies that work, and how you can improve on SQL Server’s missing index requests.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The longer your application has been around, the more developers and queries it has seen. There are a lot of ways the indexes could look, depending on how you approach performance issues with customers.
If you’re the type of shop that:
Creates specific indexes for clients experiencing problems or
Packages indexes into patches that everyone gets or
Allows clients to manage indexes on their own
You could be dealing with a lot of stray indexes depending on which path you’ve chosen. If no one is going back and looking at how all those indexes get used, you could be missing a lot of performance optimizations.
Three Ways
Let’s talk about the three ways that not cleaning up indexes can hurt performance that I see most often while working with clients:
SQL Server doesn’t work with pages while they’re stored on disk. It’s architected to work with pages that are stored in RAM, called the buffer pool, and that’s that. The more data you have by way of rows stored in tables, and indexes that make copies of data (except the clustered index, which is the base copy of your table), the more objects you have contending for space in the buffer pool.
It doesn’t matter if an index hasn’t been used in 10 years to help a query go faster, if you need to load or modify data in the base table, the relevant index pages need to be read into memory for those to occur. If your data is larger than memory, or if you’re on a version of SQL Server with a cap on the buffer pool, you could be hitting serious performance problems going out to disk all the time to fetch data into memory.
How to tell if this is a problem you’re having: Lots of waiting on PAGEIOLATCH_XX
Transaction Logging
The transaction log is SQL Server’s primitive blockchain. It keeps track of all the changes that happen in your database so they can be rolled back or committed during a transaction. It doesn’t keep track of things like who did it, or other things that Change Tracking, Change Data Capture, or Auditing get for you.
It also doesn’t matter (for the most part) which recovery model you’re in. Aside from a narrow scope of minimally logged activities like inserts and index rebuilds, everything gets fully logged. The big difference is who takes a log backup. Under FULL and BULK LOGGED, it’s you. Under SIMPLE, it’s SQL Server.
Just like with the buffer pool needing to read objects in from disk to make changes, the changes to those various objects need to be written to the transaction log, too. The larger those changes are, and the more objects get involved in those changes, the more you have to write to the log file.
There’s a whole layer of complication here that is way more than I can cover in this post — entire books are written about it — but the idea I want you to understand is that SQL Server is a good dog, and it’ll keep all your indexes up to date, whether queries use them to go faster or not.
How to tell if this is a problem you’re having: Lots of waiting on WRITELOG
Lock Escalation
The more indexes you have, the more locking you’ll likely have to do in order to complete a write. For inserts and deletes, you’ll have to hit every index (unless they’re filtered to not include the data you’re modifying). For updates, you’ll only have to lock indexes that have columns being changed in them. The story gets a little more complicated under other circumstances where things like foreign keys, indexed views, and key lookups get involved, but for now let’s get the basics under control.
When you start making changes to a table, SQL Server has a few different strategies:
Row locks, with a Seek plan
Page locks, with a Scan plan
Object locks with a Scan plan
Because SQL Server has a set amount of memory set for managing locks, it’ll attempt to make the most of it by taking a bunch of row or page locks and converting them to object locks. That number is around the 5000 mark. The number of indexes you have, and if the plan is parallel, will contribute to that threshold.
How to tell if this is a problem you’re having: Lots of waiting on LCK_XX
Sprung Cleaner
In this video, which is normally part of my paid training, I discuss how over-indexing can hurt you:
To find indexes that can be removed because they’re not used, a good, free tool is sp_BlitzIndex. It’s part of an open source project that I’ve spent a lot of time on. It’ll warn you about indexes that are unused by read queries, and even ones that have a really lopsided ratio of writes to reads.
Those are a great place to start your clean up efforts, because they’re relatively low-risk changes. If you have indexes that are sitting around taking hits from modifications queries and not helping read queries go faster, they’re part of the problem, not part of the solution.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If your developers could intuit every possible way that your application could be used, and were really good at performance turning SQL Server, you probably wouldn’t be reading things like this.
But here I am, and here you are, and here we are, staring at each other desperately searching for a reason to go on.
Many times when I’m trying to help people achieve better performance, indexes are a big part of my analysis. Unless you have a brood of queries that are just so awful they’d thwart any and every index you could possibly throw under them, you can’t avoid this inevitability.
At the end of these calls, what I often get met with is: This is great, we just have to run it by our vendor.
Lemme explain why this is wrong, because I’ve seen that end result. Things don’t get better when you make then wait.
Sycamore Tree
You are a vendor. You vend software. The way clients use that software is up to them. They may customize it in some weird way, or they may have way more data stuck in their local site than other people.
It’s sort of like being a parent: you vend life to your kids, and you can teach them how you think they should use it, but there’s a really good chance they’re gonna make different choices.
When this happens, you need to be okay with the fact that your definition of how the software gets used is no longer applicable. This goes double for vendors who don’t bring much SQL Server performance tuning expertise to the table to begin with, because the indexes you had for your ideal usage pattern probably weren’t great either.
Running the new indexes they need by you for their usage of the software is a lot like you running what you wanna have for breakfast by me. I have no idea how you plan to spend your day. A feedbag of eggs and bacon might be totally reasonable.
The one exception to this is that the vendor might be able to take my suggestions and apply them to other installations — but this stinks of a different problem than hyper-specific customization — it means you have a lot of unhappy customers out there and you just got lucky that one was willing to pay for real help.
Plastic Surgeon
I’m going to spend a number of post talking about index follies I see all the time when looking at software vendor design patterns. For now, watch this video from my paid training to learn more about why you need nonclustered indexes:
Things like not cleaning up old indexes, not adding sufficient new indexes, general index design patterns, clustered indexes, and all the silly index settings I see people changing hoping to make a difference.
This post is to prepare you for the fact that indexes need to change over time, as your application grows. Index tuning is something you need to stay actively engaged with, otherwise you’re leaving a lot of performance on the table.
Especially for folks in the cloud, where hardware size is a monthly bill, this can be an expensive situation to end up in.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Triggers can be quite useful to perform functions that cascading foreign keys are too simple for, but you can very easily overload them. I’ve run into cases where people had written what looked like an entire application worth of business logic into triggers.
Triggers that hit tables that fire other triggers that call stored procedures across servers in a while loop. You know. Developers 🐿
One very important thing to understand is that triggers always happen in a transaction, and will roll everything back unless you explicitly SET XACT_ABORT OFF; inside them. I’m not saying you should do that, at all; just that it’s an option.
Bail Reform
There are a few things you should do early on in your triggers to let them bail out as soon as possible.
Check if ROWCOUNT_BIG() = 0
Check if there are rows in the inserted pseudo-table
Check if there are rows in the deleted psuedo-table
You’ll wanna do the check against ROWCOUNT_BIG() before any SET statements, because they’ll reset the counter to 0.
DECLARE @i int;
SELECT @i = COUNT_BIG(*) FROM (SELECT x = 1) AS x;
PRINT ROWCOUNT_BIG();
SET NOCOUNT ON;
PRINT ROWCOUNT_BIG();
The first will print 1, the second will print 0. Though I suppose messing that up would be an interesting performance tuning bug for your triggers.
One bug I see in plenty of triggers, though…
Multiplicity
Make sure your triggers are set up to handle multiple rows. Triggers don’t fire per-row, unless your modifications occur for a single row. So like, if your modification query is run in a cursor or loop and updates based on a single unique value, then sure, your trigger will fire for each of those.
But if your modifications might hit multiple rows, then your trigger needs to be designed to handle them. And I don’t mean with a cursor or while loop. I mean by joining to the inserted or deleted pseudo-tables, depending on what your trigger needs to do.
Note that if your trigger is for an update or merge, you may need to check both inserted and deleted. Complicated things are complicated.
One more thing to ponder as we drift along through our trigger-writing extravaganza, is that we need to be careful where we OUTPUT rows to. If you return them to a table variable or directly to the client, you’ll end up with a fully single-threaded execution plan.
You’ll wanna dump them to a #temp table or a real table to avoid that, if your triggers are being asked to handle a deluge of rows. For smaller numbers of rows, you’re unlikely to notice that being an issue.
Know When To Say END;
The longer and more complicated your trigger becomes, the harder it will be to troubleshoot performance issues with it. Since triggers are “part” of whatever your modification queries do, you can end up with locks being taken and held for far longer than intended if there’s a lot of busy work done in them.
In much the same way Bloggers Of The World™ will warn you to index your foreign keys appropriately, you need to make sure that any actions performed in your triggers are appropriately indexed for, too. They’re not so different, in that regard.
Separating triggers into specific functions and duties can be helpful, but make sure that you set the correct order of execution, if you need them to happen in a specific order.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’ve had far too many clients get stuck running out of identity values for a table that grew a lot faster than they thought it would. The change is an ugly one for many reasons.
Though you can setup a process to make the change easier, and some changes are available as metadata-only, most people either have way more complications involved (foreign keys, triggers, etc.) or aren’t practically set up to use the metadata-only solution by having compressed indexes, and all the whatnot outlined in the linked post.
The integer maximum is, of course, 2,147,483,647 (2147483647). The big integer maximum is, of course 9,223,372,036,854,775,807 (9223372036854775807). The big integer maximum is around 4294967298 times larger. That gives you a lot more runway before you run out.
Of course, it comes with a trade off: you’re storing 8 bytes instead of 4. But my favorite way of explaining why that’s worth it is this: by the time you notice that 4 extra bytes of storage space, you’re probably about to run out of integers anyway.
Masters Of My Domain Knowledge
You don’t need to do this for static lists, or for things with an otherwise limited population. For example, if you were going to make a table of every one in your country, you could still use an integer. Even in the most populous countries on earth, you could probably survive a while with an integer.
The problem comes when you start tracking many to one relations.
An easy thing to imagine is transactions, where each user will likely have many credits and debits. Or if you’re more keen on the Stack Overflow database, each user will ask many questions and post many answers.
Hopefully, anyway. In reality, most users ask one terrible question and never come back, even if their terrible questions gets a really good answer.
The point is that once enough users have some degree of frequent activity, that identity column/sequence object will start racking up some pretty high scores. Forget the last page contention issues, there are much easier ways of dealing with those. Your problem is hitting that integer wall.
Aside from using a big integer, you could fiddle with resetting the identity or sequence value to the negative max value, but that makes people queasy for an entirely different set of reasons.
Wizzed’em
Any table in your database that’s set to represent individual actions by your users should use a big integer as an identity value, assuming you’re going the surrogate key route that utilizes an identity column, or a column based on a sequence object.
If you use a regular integer, you’re asking for problems later. Choose the form of your destructor:
Recycling identity values
Changing to a big integer
Deforming your table to use a GUID
Let’s call the whole thing off
It’s not easy making data layer changes once things have grown to the point where you’re starting to hit hard limits and boundaries. Anything you can do to protect yourself from the get-go is a must.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In this post we’re going to look at a couple other issues with them:
You can’t put them in the key of an index
You can’t push predicated down to them
I know what you’re thinking, here. You’d never do that; you’re much smarter. But someday you might have to explain to someone all the reasons why they shouldn’t do that, and you might want some more in-depth reasons other than “it’s bad”.
Trust me, I have to explain this to people all the time, and I wish I had a few great resources for it.
Like these posts, I guess.
Maxamonium
First, we have have this Very Useful™ query.
SELECT c = COUNT_BIG(*) FROM dbo.Posts AS P WHERE P.Body LIKE N'SQL%';
grouch
The plan stinks and it’s slow as all get out, so we try to create an index.
CREATE INDEX not_gonna_happen
ON dbo.Posts(Body);
But SQL Server denies us, because the Body column is nvarchar(max).
Msg 1919, Level 16, State 1, Line 7
Column 'Body' in table 'dbo.Posts' is of a type that is invalid for use as a key column in an index.
Second Chances
Our backup idea is to create this index, which still won’t make things much better:
CREATE INDEX not_so_helpful
ON dbo.Posts(Id) INCLUDE(Body);
MAX columns can be in the includes list, but includes aren’t very effective for searching, unless they’re part of a filtered index. Since we don’t know what people will search for, we can’t create an explicit filter on the index either.
ehh no
Even with a smaller index to read from, we spend a full two minutes filtering data out, because searching for N'SQL%' in our where clause can’t be pushed to when we scan the index.
And Sensibility
Let’s contrast that with a similar index and search of a column that’s only nvarchar(150). Sure, it’s not gonna find the same things. I just want you to see the difference in the query plan and time when we’re not hitting a (max) column.
This isn’t gonna help you if you genuinely do need to store data up to ~2GB in size in a single column, but it might help people who used a max length “just to be safe”.
CREATE INDEX different_world
ON dbo.Posts(Id) INCLUDE(Title);
SELECT c = COUNT_BIG(*) FROM dbo.Posts AS P WHERE P.Title LIKE N'SQL%';
helicopter team
But if you fumbled around and found out, you might be able to downsize your columns to a byte length that actually fits the data, and do a lot better performance-wise. This search only takes about 460 milliseconds, even if we scan the entire index.
You may not like it, but this is what better performance looks like.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In yesterday’s post, I taught you about the good things that come from using computed columns. In today’s post, I want to show you something terrible that can happen if you put scalar UDFs in them. The same issues arise if you use scalar UDFs in check constraints, so you can apply anything you see here to those as well.
To make things quick and easy for you to digest, here’s a training video that’s normally part of my paid classes available for free.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One of the most common things I see when working with vendor apps are queries that need to filter or join on some expression that traditional indexing can’t make efficient.
B-tree indexes only organize the data as it currently exists. As soon as you perform a runtime manipulation on it in a join or where clause, SQL Server’s optimizer and storage engine have far fewer good choices to make.
This comes back to a couple rules I have when it comes to performance:
Anything that makes your job easier makes the optimizer’s job harder
Store data the way you query it, and query data the way you store it
Presentation Is Everything
SQL Server has many built in functions that help you easily manipulate data for presentation. It also lets you write a variety of user defined functions if the existing set don’t do exactly what you want, or you have different needs.
None of these functions have any relational meaning. The built in ones don’t generally have any additional side effects, but user defined functions (scalar and multi-statement) have many additional performance side effects that we’ll discuss later in the series.
This practice violates both of the above rules, because you did something out of convenience that manipulated data at runtime.
You will be punished accordingly.
Snakes
These are the situations you want to avoid:
function(column) = something
column + column = something
column + value = something
value + column = something
column = @something or @something IS NULL
column like ‘%something’
column = case when …
value = case when column…
Mismatching data types
For a lot of these things, though, you can use a computed column to materialize the expression you want to use. They’ve been around forever, and I still barely see anyone using them.
There are a lot of misconceptions around them, usually that:
They cause blocking when you add them (only sometimes)
You can’t index them unless you persist them (you totally can!)
Known
There are some interesting things you can do with computed columns to make queries that would otherwise have a tough time go way faster. To make it quick and easy for you to learn about them, I’m making videos from my paid training available here for you to watch.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.