Nein Nein Nein
I know, I said we’d talk about indexes, and heaps are basically the opposite of indexes.
Even if you have a heap with a nonclustered primary key, or nonclustered indexes hanging around, the base table is still a heap.
Why? It’s all about that clustered index.
Do you always need a clustered index? Sometimes not. But if you’re running an OLTP workload, you probably do.
It’s not that heaps can’t be useful, it’s just that their best use-case is still loading the big datas.
Downsides Of Heaps
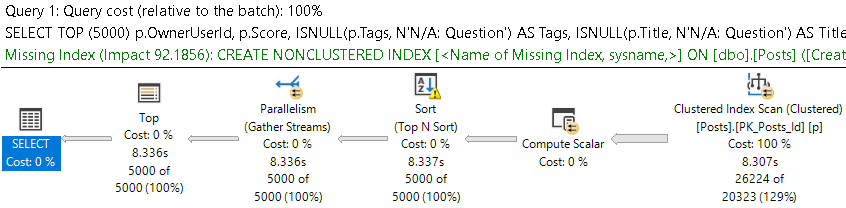
Heaps have a couple issues that are going to sound a lot like index fragmentation. In fact, they’re a lot like index fragmentation.
- Forwarded fetches from updates
- Empty pages from deletes
Forwarded Fetches
Forwarded fetches are a lot like logical fragmentation, which is when pages are out of order. Instead of having clustered index keys to follow, we have pointers from where the row used to be to where it got moved to.
This happens because updates change a value that makes a row not fit on a page anymore.
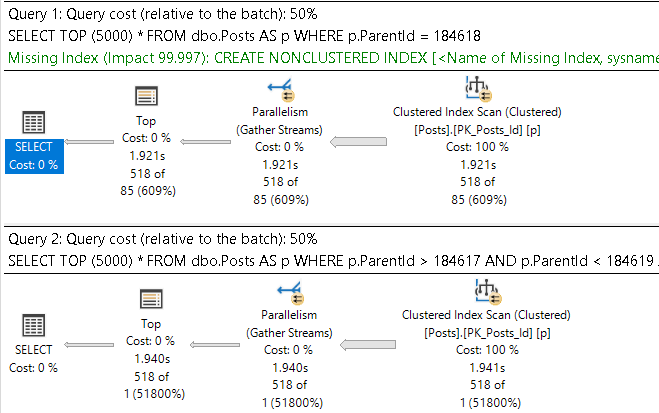
Heaps compound the issue a little bit though, because you can’t seek into a heap to avoid forwarded fetches (though you can seek into any index created on top of a heap). You can seek into a clustered index to avoid logical fragmentation.
Empty Space
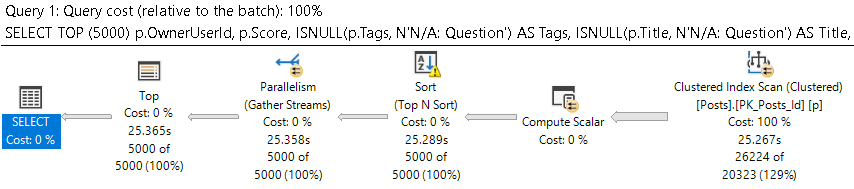
Empty space from deletes goes a little bit further, too. You can end up with entire pages being empty, if queries that delete data don’t successfully escalate locks to the table level. Worse, those empty pages get read when the heap is scanned.
Sure, clustered indexes can end up with a bunch of empty space on pages, but when pages are totally emptied out they will get deallocated. Heaps don’t do that without a table level lock during the delete.
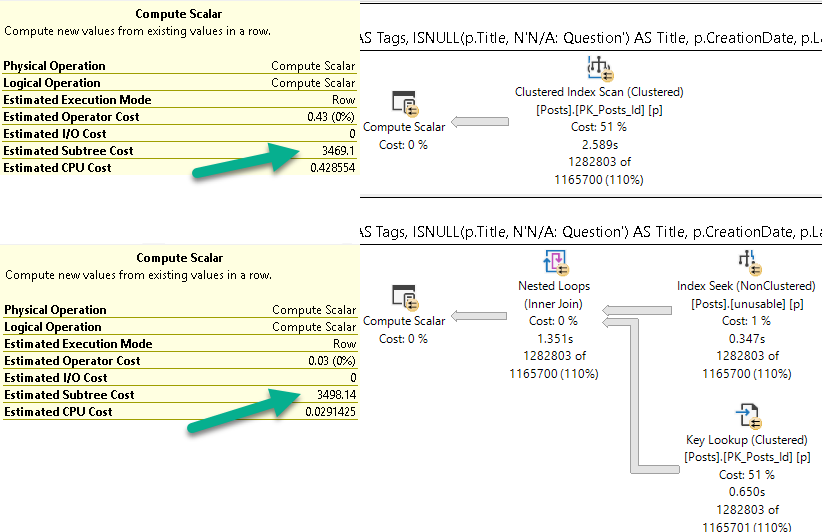
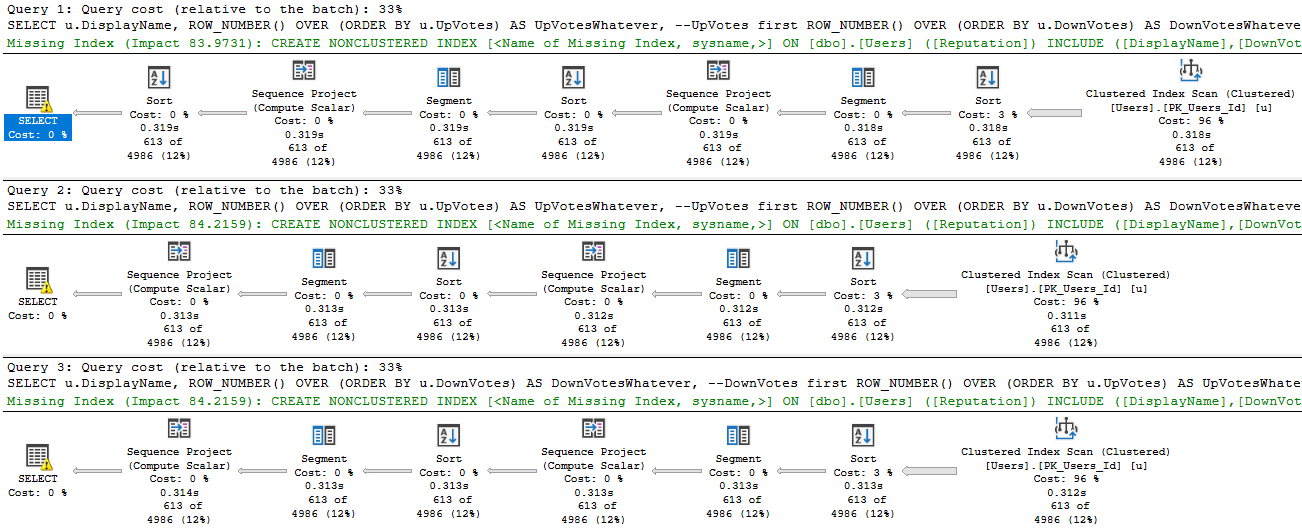
The thing is that both of these only happen to the heap itself. If you’ve got nonclustered indexes on the heap and queries mostly use those, you may not notice either of these problems. Perhaps a little bit if you do bookmark lookups.
When They Might Matter
This is largely a size thing. The bigger your heaps are, the more pronounced these problems can be.
It also depends a bit on what heap tables get used for. Or more importantly, who uses them.
If they’re staging tables that end users don’t touch, fixing them probably won’t solve a big problem for you outside of ETL.
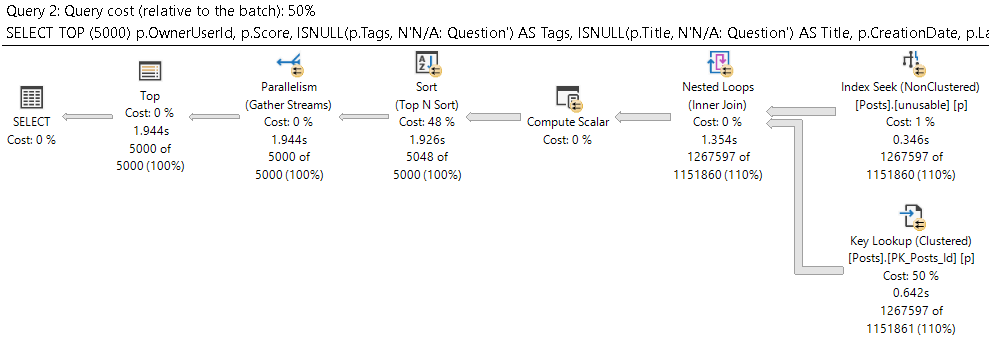
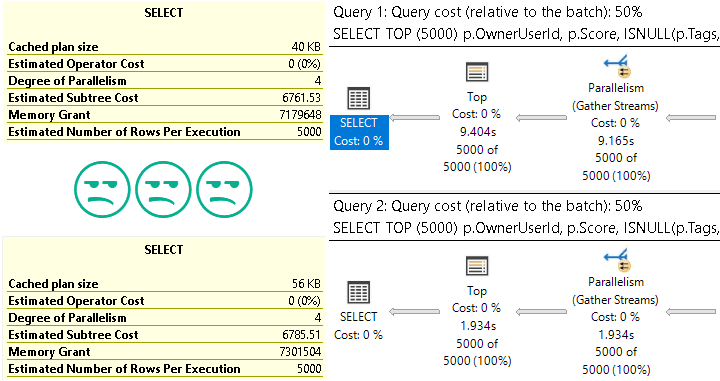
But if they’re transactional tables where end users are complaining about performance, you need to do two things: check the query plans for table scans, and then check the heaps for forwarded fetches and deletes.
To fix them, you can rebuild the heap, or create a clustered index. In either case, be very careful if you’ve got nonclustered indexes on the table, because they’ll need to all get rebuilt to either fix the RIDs in a heap, or add the clustered index keys.
Your next question is: Erik, how do I pick a clustered index? We’ll talk about that tomorrow!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.