Least Favorite
This is one of my least favorite query patterns, because even with appropriate indexes, performance often isn’t very good without additional interventions.
Without indexes in place, or when “indexes aren’t used”, then the query plans will often look like one of these.
Maybe not always, but there are pretty common.
Merge Interval
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON (p.OwnerUserId = u.Id
OR p.LastEditorUserId = u.Id);
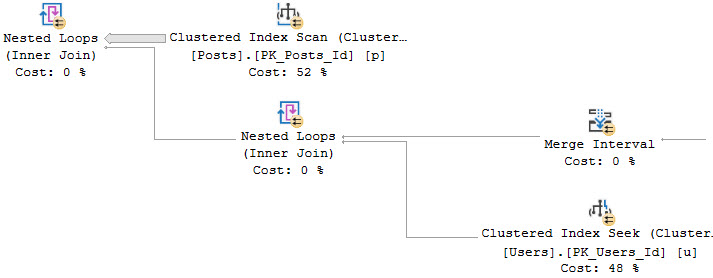
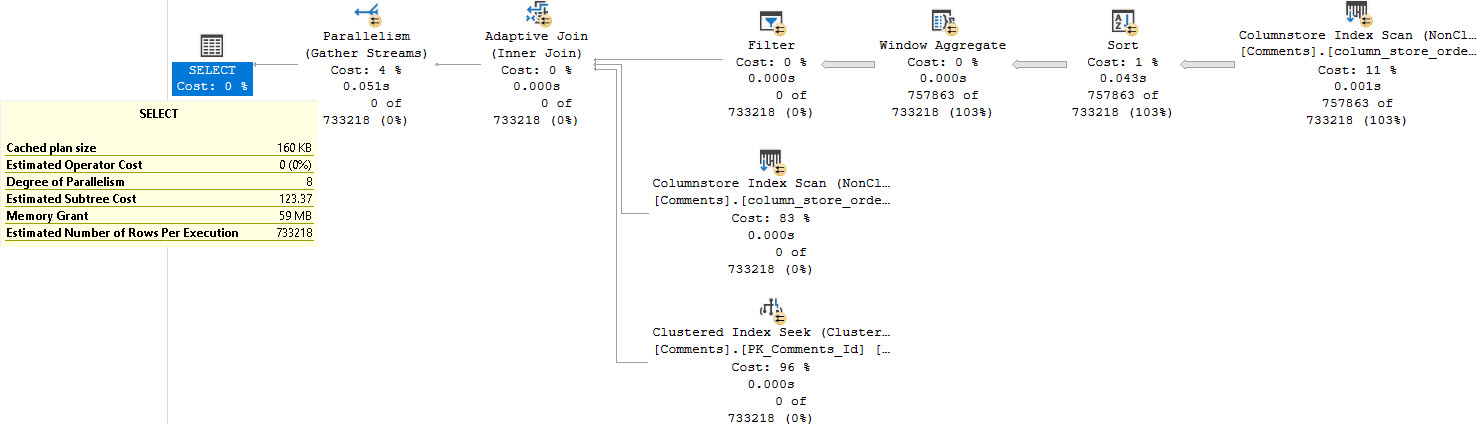
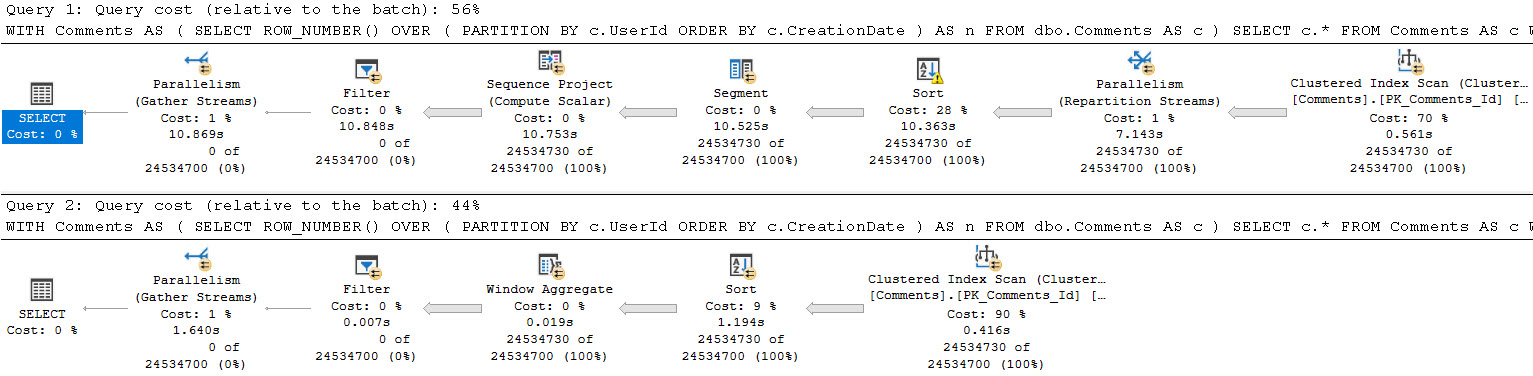
We start off with a scan of the Posts table, and a Nested Loops Join to a… Nested Loops Join? That’s weird.

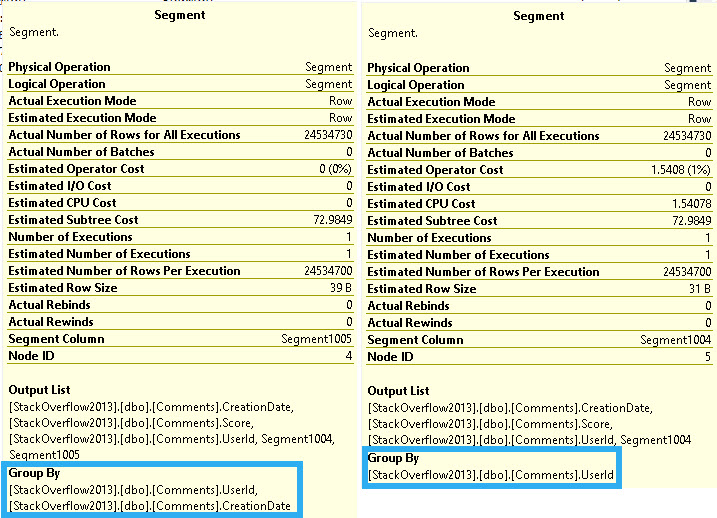
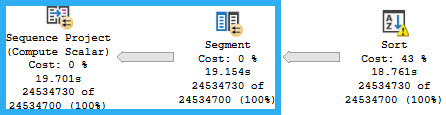
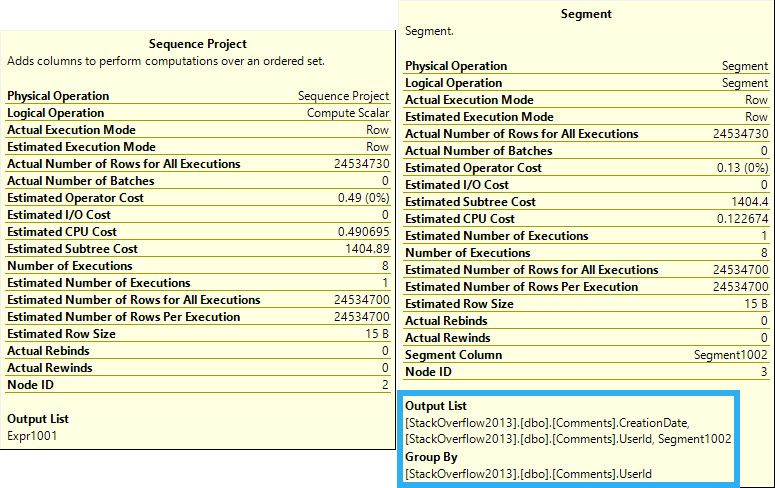
From the Merge Interval to the right, there’s a lot of additional operators. Those two Constant Scan operators represent virtual tables containing the two columns from Posts being used in the join.
One for OwnerUserId, and one for LastEditorUserId. The Sort and Merge interval are a pseudo-attempt at ordering the concatenated results and removing duplicate ranges. I don’t think I’ve ever seen them be terribly effective.
This plan takes on this shape because the Users table has a seekable index on the Users table on the Id column.
Loops and Lazy Spools
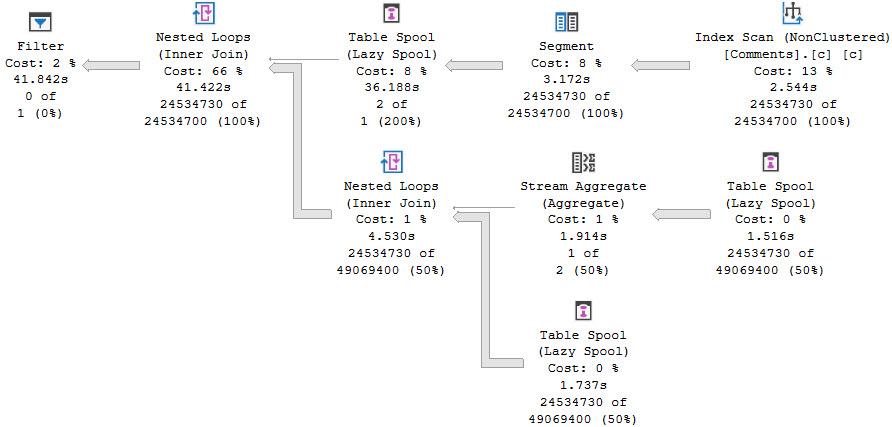
With no usable indexes on either side, the plan will often take on a shape like this.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Comments AS c
JOIN dbo.Posts AS p
ON (p.OwnerUserId = c.UserId
OR p.LastEditorUserId = c.UserId);

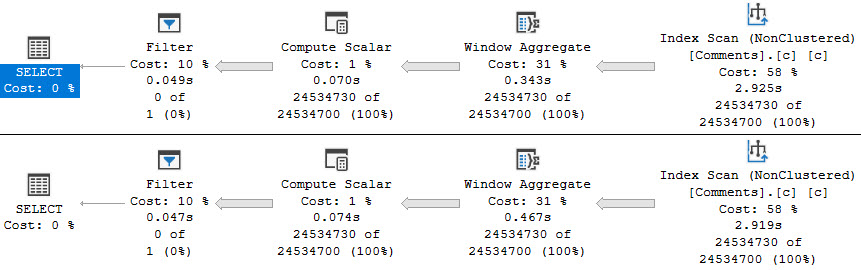
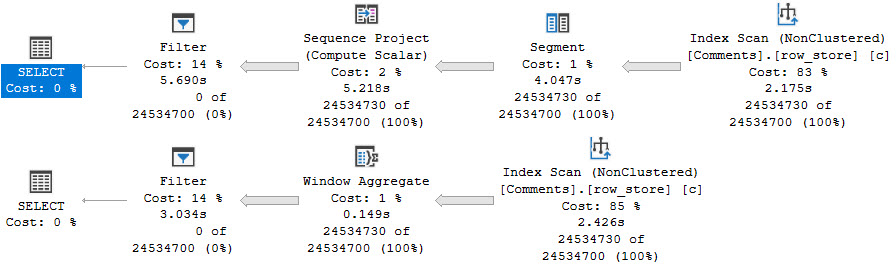
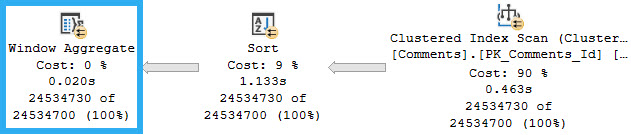
This is an admittedly weird plan. Weird because usually when there’s a Lazy Spool on the inner side of a Nested Loops Join, there’s some Sorting of data on the outer side.
The Nested Loops Join here is not Optimized, and does not do an Ordered Prefetch. It’s odd to me that the Hash Match Aggregate on the outer side isn’t a Sort > Stream Aggregate.
This is usually done to maximize the Spool’s efficiency, and cut down on the Spool needing to execute child operators.
For example, let’s say the numbers 1 through 10 came out of the Comments table, and there were 10 of each. If they were in order, the Spool would initially fill with the values from Posts for 1, and then the contents of the Spool would get used for the next 9 duplicate values of 1.
The process would repeat for the rest of the numbers, with the Spool truncating itself when it sees a new value.
Let’s Add Indexes
You may have noticed that I’ve only been using estimated plans up until now. That’s because both of these queries run way too slowly to deal with actual plans for.
The optimal indexes we need to make that not the case any more look like this:
CREATE INDEX po
ON dbo.Posts
(OwnerUserId);
CREATE INDEX pl
ON dbo.Posts
(LastEditorUserId);
CREATE INDEX cu
ON dbo.Comments
(UserId);
ORnery
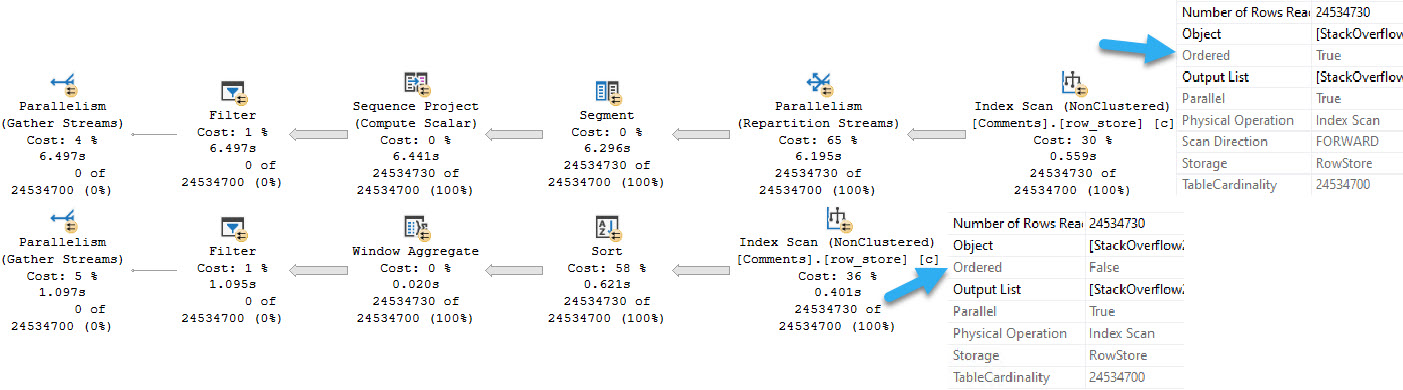
If we don’t change the queries at all, both plans will use the Merge Interval shape. It’s only somewhat beneficial to the Users/Posts query, which now finishes in about 40 seconds. The Comments/Posts query runs for… I dunno. I let it go for three hours and my CPUs were maxed out the whole time and things got unusable.
If you’re going to leave the OR in, you need to use a FORCESEEK hint. More specifically, you need to use the hint on the table that has different columns in the OR clause. Otherwise, the plan shape goes all to crap (Merge Interval).
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p WITH(FORCESEEK)
ON (p.OwnerUserId = u.Id
OR p.LastEditorUserId = u.Id);
GO
SELECT
COUNT_BIG(*) AS records
FROM dbo.Comments AS c
JOIN dbo.Posts AS p WITH(FORCESEEK)
ON (p.OwnerUserId = c.UserId
OR p.LastEditorUserId = c.UserId);
GO
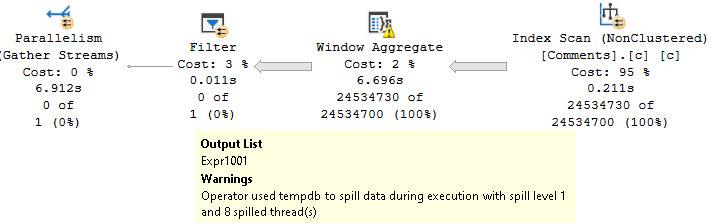
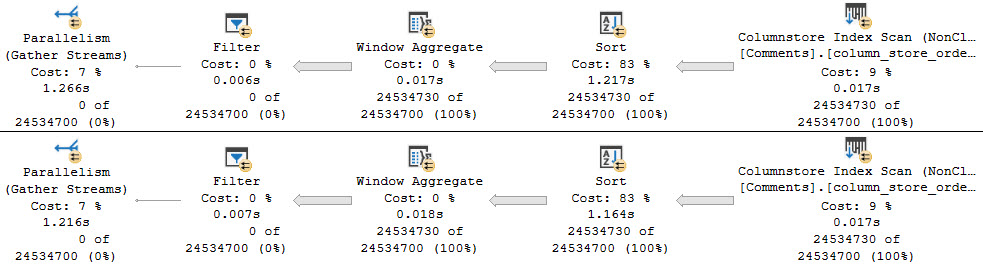
With that hint in place, both queries will take on a similar, non-disastrous shape.
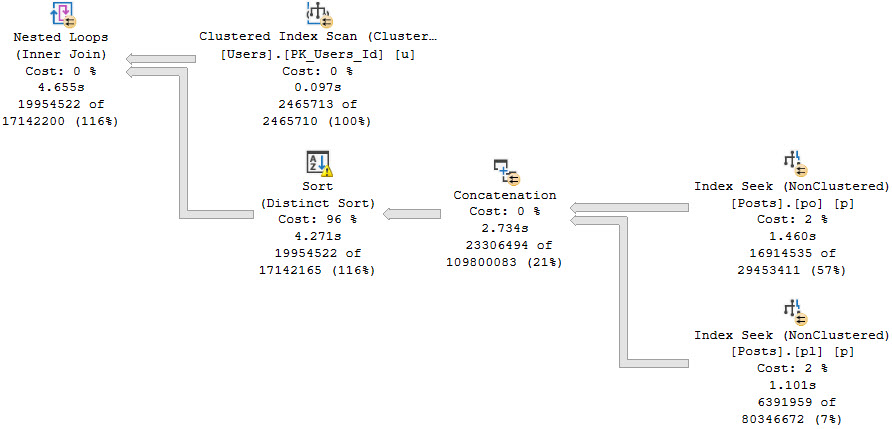
Both queries will take around 5 seconds.
Leaving The Or Out
The usually-better rewrite is to use UNION ALL to separate the OR out, especially if you don’t have good indexes in place.
With good indexes in place (like above), both benefit from the FORCESEEK hint as well
SELECT
SUM(x.x) AS records
FROM
(
SELECT
COUNT_BIG(*) AS x
FROM dbo.Comments AS c
JOIN dbo.Posts AS p WITH(FORCESEEK)
ON p.OwnerUserId = c.UserId
UNION ALL
SELECT
COUNT_BIG(*) AS x
FROM dbo.Comments AS c
JOIN dbo.Posts AS p WITH(FORCESEEK)
ON p.LastEditorUserId = c.UserId
AND p.OwnerUserId <> c.UserId
) AS x;
SELECT
SUM(x.x) AS records
FROM
(
SELECT
COUNT_BIG(*) AS x
FROM dbo.Users AS u
JOIN dbo.Posts AS p WITH(FORCESEEK)
ON p.OwnerUserId = u.Id
UNION ALL
SELECT
COUNT_BIG(*) AS x
FROM dbo.Users AS u
JOIN dbo.Posts AS p WITH(FORCESEEK)
ON p.LastEditorUserId = u.Id
AND p.OwnerUserId <> u.Id
) AS x;
Not All ORs
I am usually not a fan of OR predicates in JOINs. There often isn’t great indexing in place to make things fast, or support the FORCESEEK hints.
If you see query plans with these patterns in them, you should keep an eye out for them. You may have a pretty easy performance win on your hands, either via indexing and hints, or rewriting to a UNION ALL.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.