This post is about a slightly different set of things that I want you to be aware of.
Not So Fast
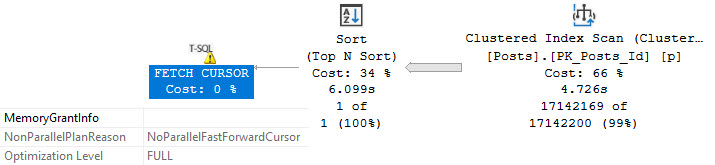
First, FAST_FORWARD cursors force your queries to run serially, and plan quality may suffer if a dynamic cursor is chosen.
Take this query for example:
SELECT TOP (1)
p.OwnerUserId
FROM dbo.Posts AS p
ORDER BY p.Score DESC;
By itself in the wilderness it gets a parallel plan and runs for under 1 second.
thanks, parallel
But in the grips of a fast forward cursor, we’re not so lucky.
DECLARE @i int;
DECLARE c CURSOR
LOCAL
FAST_FORWARD
FOR
SELECT TOP (1)
p.OwnerUserId
FROM dbo.Posts AS p
ORDER BY p.Score DESC;
OPEN c;
FETCH NEXT
FROM c INTO @i;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @i;
BREAK;
END;
CLOSE c;
DEALLOCATE c;
n4u
Other Problems
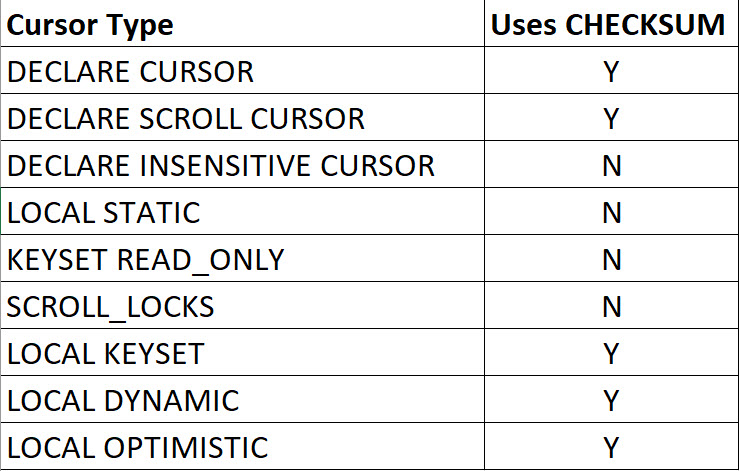
Sometimes, the default cursor, along with several other cursor types, will lead to a CHECKSUM being generated.
This can happen when you:
Declare a cursor that will do writes
Declare a cursor for a select but don’t define it as read only
Here’s a breakdown of how that works if you don’t have a rowversion column in the table(s) that your cursor is touching
options, please
Son Of A Check
What can happen to performance if you use one of these types of cursors that does require a checksum?
Well, remember the query up there that took about a second with no cursor?
charlie
You could put together a query that resembles what happens here by doing something like this:
SELECT TOP (1)
p.OwnerUserId,
unfair =
CHECKSUM(*)
FROM dbo.Posts AS p
ORDER BY p.Score DESC;
But as all non-Australians agree, this is unfair because when the cursor does it in the query above, it’s the storage engine computing the checksum and the row data is all there locally. When the optimizer does it, it has to go through extra steps.
But Why?
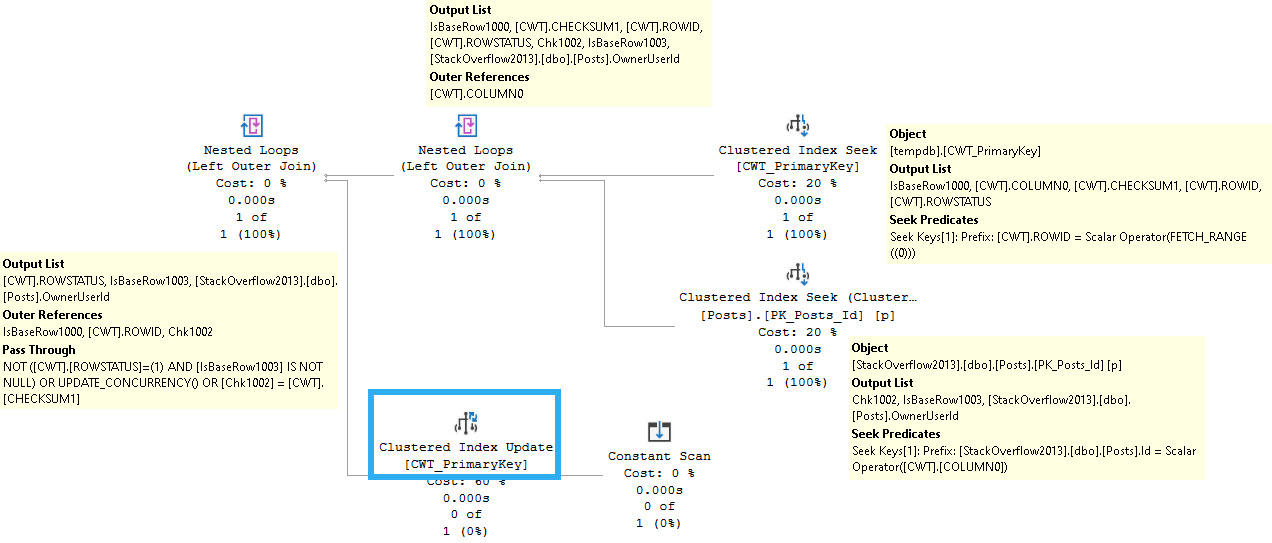
When you don’t tell SQL Server that your cursor query is read only, it will generate row version checksums to compare on subsequent to assess if rows changed. If your cursor query contains multiple table references, each table will receive a row checksum that doesn’t have a rowversion column already in it.
For example, this is what the next fetch looks like after the poorly-performing query:
complicated game
You can see the cursor snapshot table joining back to the Posts table, along with an update of the cursor snapshot table.
The fetch query from the cursor query that performs well looks only like this:
simple times
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The optimizer has a lot of choices. As of SQL Server 2019, there are 420 of them.
You can see how many are available in your version of SQL Server by doing this:
SELECT
total_transformations
= COUNT_BIG(*)
FROM sys.dm_exec_query_transformation_stats;
Then you can change the query to actually select columns and view all the available rules.
Pretty neat.
Ten Hut
One thing the optimizer can do is order data to make things more efficient, like we saw with Lookups.
That choice, like nearly every optimizer choice (barring ones based on product or feature limitations), is based on costing. Those costs could be right, wrong, lucky, unlucky, or anything in between.
One of those options is to use an operator that requires sorted input, or sorts input on its own.
Why do we care about this? Because Sorts ask for memory, and memory can be a contentious subject with SQL Server. Not only because Sorts often ask for size-of-data memory grants
Here are some common examples!
Distinctly Yours
If you ask for a set of data to be distinct, or if you group by every column you’re returning, you may see a query plan that looks like this:
this is it
The details of the operator will show you some potentially scary and hairy details, particularly if you’re asking for a large number of columns to be made distinct:
ouchies
All of the column that you have in your select list (Output) will end up in the Order By portion of the Sort. That could add up to quite a large memory grant.
Ex-stream-ly Necessary
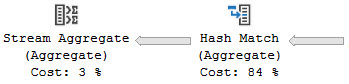
If the Almighty Optimizer thinks that a Stream Aggregate will be the least-expensive way to aggregate your data, you may see a plan like this:
windy
Of course, not all Stream Aggregates will have a Sort in front of them. Global Aggregates will often use them.
you’re great
Rows from the Hash Aggregate flow into the Stream Aggregate, but order doesn’t matter here.
double saturday
What is the Hash Match hashing? Apparently nothing! Good job, hash match.
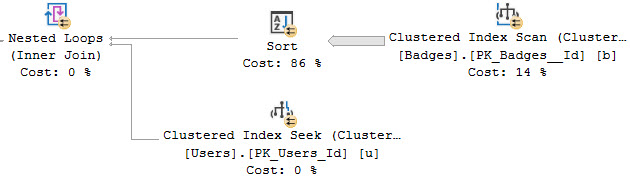
Nasty Loops
Just like with Lookups (which also use Nested Loops), SQL Server may choose to Sort one input into the Nested Loops Join.
beef smells
Orderly data is apparently very important to all sorts of things. If you see a lot of this in your query plans, you may want to start thinking about adding indexes to put data in required order.
And Acquisitions
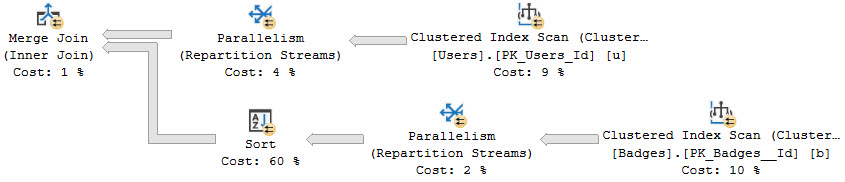
Likewise, Merge joins may also show a Sort on one or both inputs to put data in the correct join order:
cutting
Maybe not great:
bartender
That Tree
Sometimes these Sorts are harmless, and sometimes they’re not. There are many situational things about the queries, indexes, available resources, and query plan appropriateness that will lead you to treating things differently.
Parameter sniffing, cardinality estimate accuracy, query concurrency, and physical memory are all potential reasons for these choices going great or going grog.
Of course, parallel merge joins are always a mistake.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The first time I heard the term “common subexpression spool” my brain went numb for a week.
It’s not a particularly mellifluous phrase, but it is helpful to understand what it is.
One easy way to think about it is a temporary cache for the result of a query, like a temp table inside your execution plan:
SELECT
*
INTO #a_temporary_table
FROM dbo.a_really_complicated_query AS a
WHERE a.thing = 'stuff';
If you were to do this, and then use that temp table to feed other queries later on, you’d be doing nearly the same thing.
Let’s look at some common-ish examples of when you might see one.
Modifications
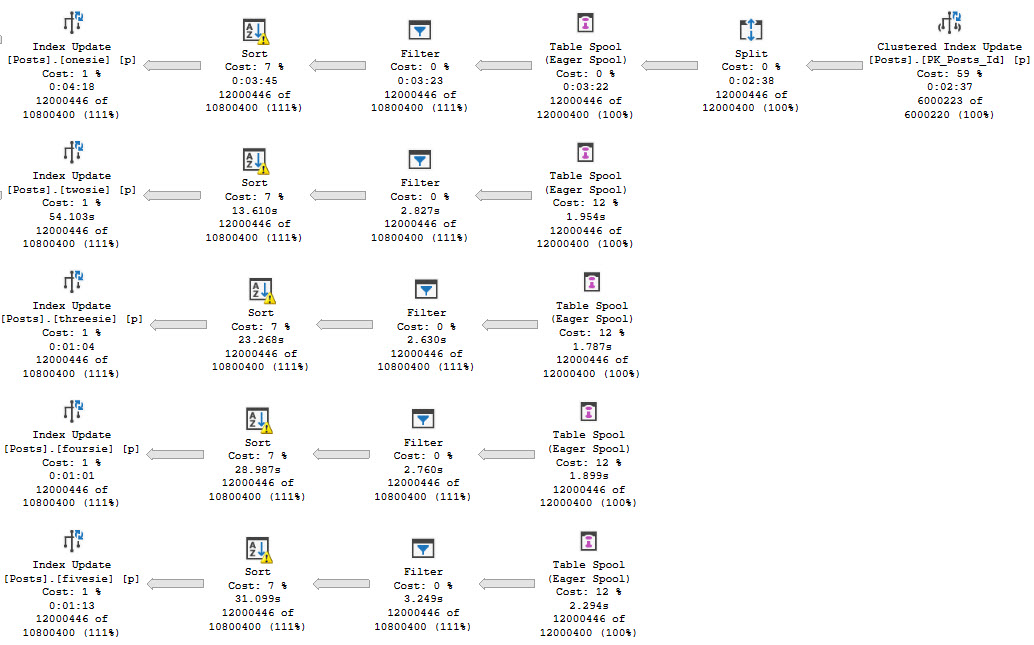
This is the most common one, and you’ll see it in “wide” modification query plans. Or as they’re sometimes called “per index” plans.
This screenshot is highly abridged to focus in on the part I care about.
pretty though
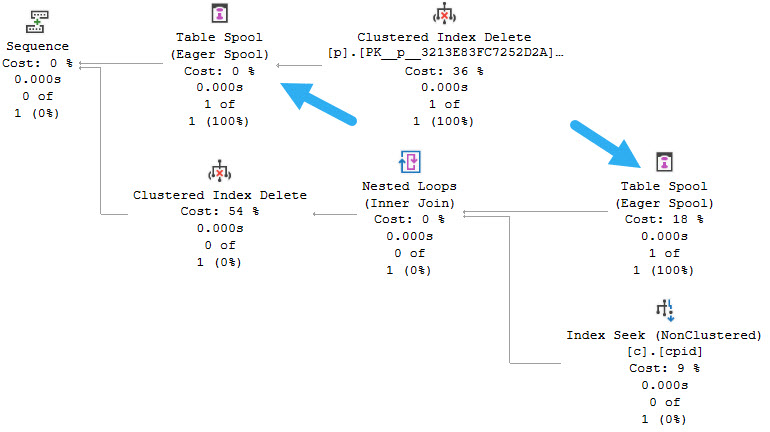
There’s a clustered index update, a Split operator, and then an Eager Table Spool. There’s also four more Eager Table Spools underneath it, but none of them have child (preceding) operators. Each one of those Spools is really the same Spool being read from over again.
Cascades
If you have foreign keys that enforce cascading actions, you’re likely to see a query plan that looks like this:
coach
The clustered index delete feeds into an Eager Table Spool, and that Spool is read from in the child portion of the plan to track rows to be deleted from the child table.
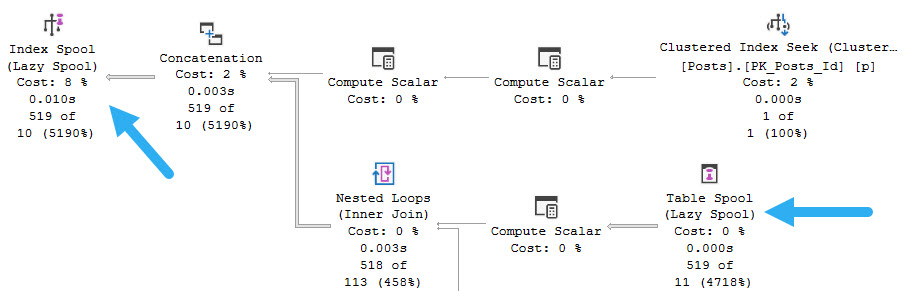
Though this time the Spool is Lazy rather than Eager, there’s something else interesting. They’re Stack Spools!
defenses
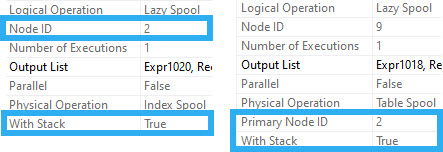
The Lazy Index Spool has a Node ID of 2, and With Stack set to True.
The Lazy Table Spool is linked to the Lazy Index Spool by its Primary Node ID.
The actual Node ID of the Lazy Table Spool is 9. It also has the With Stack property set to True.
The description of a Stack Spool from the linked post above:
Unlike ordinary common subexpression spools which eagerly load all rows into the worktable before returning any rows, a stack spool is a lazy spool which means that it begins returning rows immediately. The primary spool (the topmost operator in the plan) is fairly mundane. Like any other lazy spool, it reads each input row, inserts the row into the spool, and returns the row to the client. The secondary spool (below the nested loops join) is where all the interesting action is. Each time the nested loops join requests a row from the secondary spool, the spool reads the last row from the spool, returns it, and then deletes it to ensure that it is not returned more than once. Note that the term stack spool comes from this last in first out behavior. The primary spool pushes rows onto the stack and the secondary spool pops rows off of the stack.
Dones
There are other places where you might see this happen, like in row mode execution plans with multiple DISTINCT aggregates.
You might also see them for queries that use CUBE in them, like so:
SELECT
b.UserId,
b.Name,
COUNT_BIG(*) AS records
FROM dbo.Badges AS b
WHERE b.Date >= '20131201'
GROUP BY
b.UserId,
b.Name
WITH CUBE;
These Spools are often necessary to not get incorrect results or corrupt your database. You’d probably not enjoy that very much at all.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One sort of interesting point about prefetching is that it’s sensitive to parameter sniffing. Perhaps someday we’ll get Adaptive Prefetching.
Until then, let’s marvel at at this underappreciated feature.
Neckline
The difference between getting ordered and unordered prefetch typically comes down to the data needing to be ordered for one reason or another.
It might be an order by, or some other operator that expects or preserves ordered input.
The easiest way to see that is just to use order by, like so:
/*Unordered prefetch*/
SELECT TOP (1000)
p.*
FROM dbo.Posts AS p
WHERE p.CreationDate < '20100801';
GO
/*Ordered prefetch*/
SELECT TOP (1000)
p.*
FROM dbo.Posts AS p
WHERE p.CreationDate < '20100801'
ORDER BY p.CreationDate;
GO
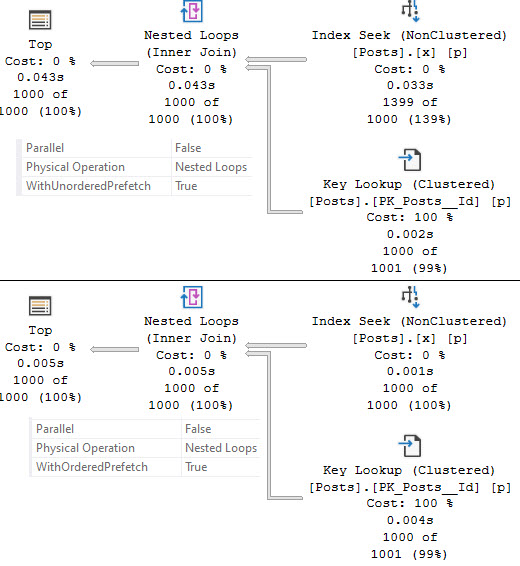
Here’s what we get from the nested loops properties:
meating
You may notice that the top query that uses unordered prefetch read 1399 rows from the seek, and takes 43ms vs the ordered prefetch query’s 1000 rows and 5ms runtime.
That tends to happen with a cold cache (DBCC DROPCLEANBUFFERS;) , and it exacerbated in parallel plans:
worsened
In this case, both queries read additional rows from the index seek.
Shopkeep
But what about all that parameter sniffing stuff? Check this out.
CREATE OR ALTER PROCEDURE dbo.Dated
(
@date datetime
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
DBCC DROPCLEANBUFFERS;
SELECT TOP (1000)
p.*
FROM dbo.Posts AS p WITH(INDEX = x)
WHERE p.CreationDate < @date
ORDER BY p.Score DESC
OPTION(MAXDOP 1);
END;
I have an index and MAXDOP hint in there so we do an equal comparison across executions.
EXEC dbo.Dated
@date = '20080731';
GO
EXEC dbo.Dated
@date = '20190801';
GO
If we run the “small” version first, we won’t get the benefit of readaheads. This query runs for a very long time — nearly 2 hours — but most of the problem there is the spill at the end. If we run the “big” version first, we get unordered prefetch, and the time is significantly improved.
editorial
Thanks, parameter sniffing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Most people see a lookup and think “add a covering index”, regardless of any further details. Then there they go, adding an index with 40 included columns to solve something that isn’t a problem.
You’ve got a bright future in government, kiddo.
In today’s post, we’re going to look at a few different things that might be going on with a lookup on the inside.
But first, we need to talk about how they’re possible.
Storage Wars
When you have a table with a clustered index, the key columns of it will be stored in all of your nonclustered indexes.
Where they get stored depends on if you define the nonclustered index as unique or not.
So you can play along at home:
DROP TABLE IF EXISTS #tabs, #spaces;
CREATE TABLE #tabs
(
id int NOT NULL PRIMARY KEY,
next_id int NOT NULL,
INDEX t (next_id)
);
CREATE TABLE #spaces
(
id int NOT NULL PRIMARY KEY,
next_id int NOT NULL,
INDEX s UNIQUE (next_id)
);
INSERT
#tabs (id, next_id)
VALUES (1, 2);
INSERT
#spaces (id, next_id)
VALUES (1, 2);
Here are two tables. Both definitions are identical, with the exception of the nonclustered index on #spaces. It is unique.
Like you.
You’re so special.
Findings
These queries are special, too.
SELECT
t.*
FROM #tabs AS t WITH(INDEX = t)
WHERE t.id = 1
AND t.next_id = 2;
SELECT
s.*
FROM #spaces AS s WITH(INDEX = s)
WHERE s.id = 1
AND s.next_id = 2;
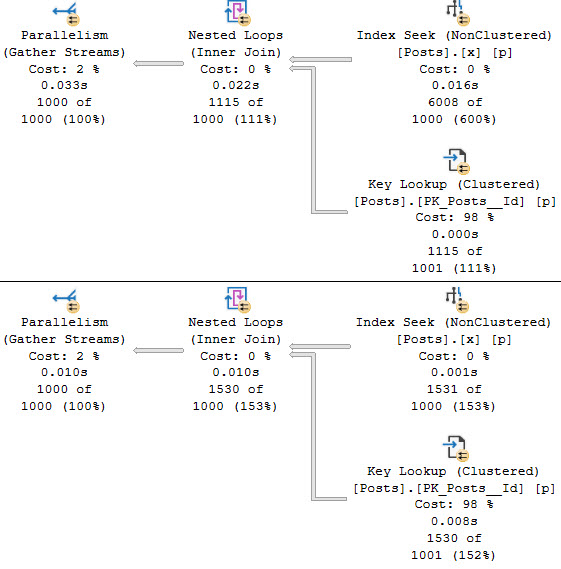
The query plans for these queries have a slight difference, too.
trust us
The non-unique index supports two seek predicates. The unique index has one seek plus a residual predicate.
No lookup is necessary here, because in both cases the clustered index key columns are in the nonclustered index. But this is also how lookups are made possible.
We can locate matching rows between clustered and nonclustered indexes.
Unfortunately, we’re all out of columns in this table, so we’re gonna have to abandon our faithful friends to the wilds of tempdb.
Garbaggio
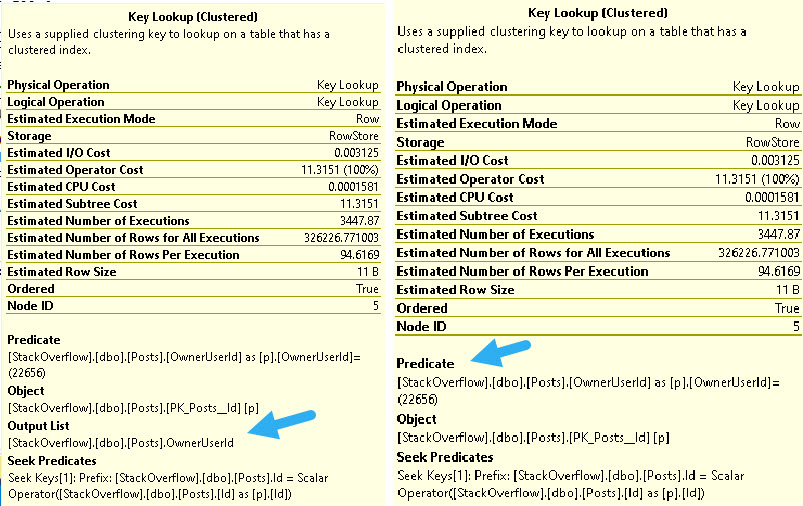
I’m sure I’ve talked about this point before, but lookups can be used to both to output columns and to evaluate predicates in the where clause. Output columns can be from any part of the query that asks for columns that aren’t in our nonclustered index.
got’em
The Seek predicate you see at the bottom of both of these tool tips is the relationship between the two indexes, which will be the clustered index key columns.
Big More
We’re going to start and end with this index:
CREATE INDEX x
ON dbo.Posts(CreationDate);
It’s just that good. Not only did it provide us with the screenshots up above, but it will also drive all the rest of the queries we’re going to look at.
Stupendous.
The clustered index on the Posts table is called Id. Since we have a non-unique index, that column will be stored and ordered in the key of the index.
The things we’re going to look at occurring in the context of lookups are:
Explicit Sorts
Implicit Sorts
Ordered Prefetch
Unordered Prefetch
You’ll have to wait until tomorrow for the prefetch stuff.
Banned In The USA
Let’s start with this query!
SELECT
AverageWhiteBand =
AVG(p.Score)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20190323';
Since we have an inequality predicate on CreationDate, the order of the Id column is no longer preserved on output.
bucky
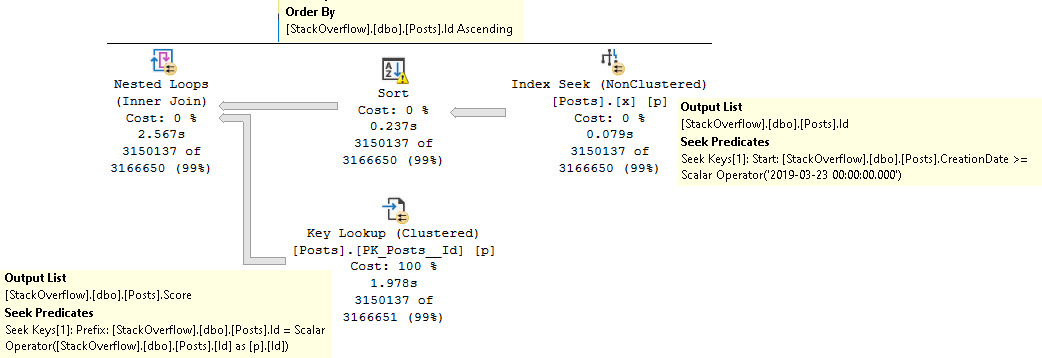
The query plan, from right to left:
Seeks into our magnificent index
Sorts the output Id column
Seeks back into the clustered index to get the Score column
The sort is there to put the Id column in a friendlier order for the join back to the clustered index.
Implicit Lyrics
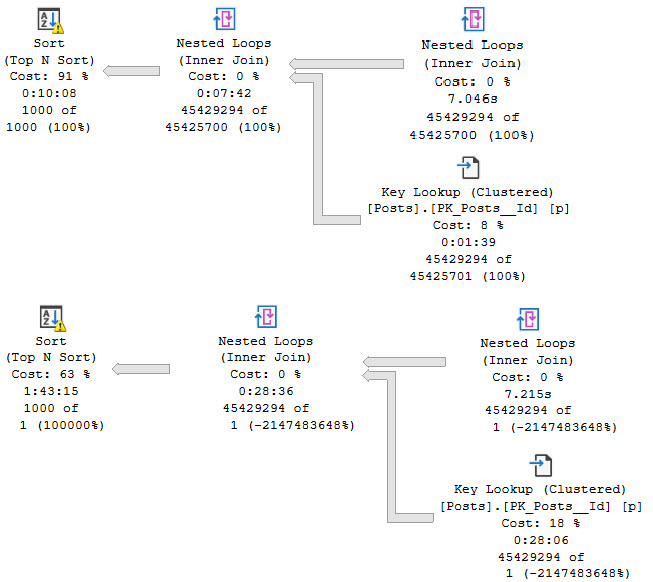
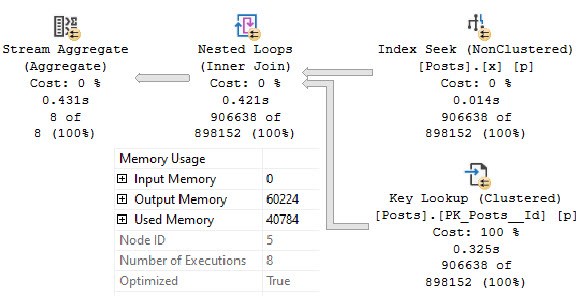
If we change the where clause slightly, we’ll get a slightly different execution plan, with a hidden sort.
SELECT
AverageWhiteBand =
AVG(p.Score)
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20190923'
In the properties of the nested loops join, we’ll see that it has consumed a memory grant, and that the Optimized property is set to True.
long gone
Much more common memory grants are for Sorts and Hashes. The details are available on Craig Freedman’s blog:
Notice that the nested loops join includes an extra keyword: OPTIMIZED. This keyword indicates that the nested loops join may try to reorder the input rows to improve I/O performance. This behavior is similar to the explicit sorts that we saw in my two previous posts, but unlike a full sort it is more of a best effort. That is, the results from an optimized nested loops join may not be (and in fact are highly unlikely to be) fully sorted.
SQL Server only uses an optimized nested loops join when the optimizer concludes based on its cardinality and cost estimates that a sort is most likely not required, but where there is still a possibility that a sort could be helpful in the event that the cardinality or cost estimates are incorrect. In other words, an optimized nested loops join may be thought of as a “safety net” for those cases where SQL Server chooses a nested loops join but would have done better to have chosen an alternative plan such as a full scan or a nested loops join with an explicit sort. For the above query which only joins a few rows, the optimization is unlikely to have any impact at all.
The reason I’m fully quoting it here rather than just linking is because when I went to go find this post, I realized that I have four bookmarks to Craig’s blog, and only one of them works currently. Microsoft’s constant moving and removing of content is a really frustrating, to say the least.
Looky Looky
Lookups have a lot of different aspects to them that make them interesting. This post has some additional interesting points to me because of the memory grant aspect. I spend a lot of time tinkering with query performance issues related to how SQL Server uses and balances memory.
In tomorrow’s post, we’ll take a high-level look at prefetching. I don’t want to get too technical on the 20th day of the 4th month of the calendar year.
It may not be the best time to require thinking.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
CREATE INDEX po ON dbo.Posts
(OwnerUserId);
CREATE INDEX ps ON dbo.Posts
(Score);
Let’s jump right in!
Big Run
The main difference between when you’re likely to get index union vs index intersection is if your predicates use AND or OR. Index intersection is typically from AND predicates, and index union is typically from OR predicates. So let’s write some OR predicates, shall we?
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 0
OR p.Score > 10;
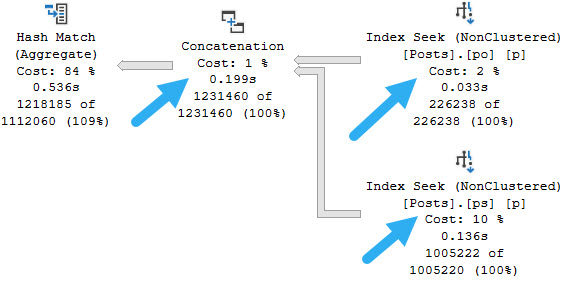
First, using one equality and one inequality predicate:
concaturday
Since we lose the ordering on the inequality predicate, this is our plan. Note he hash match aggregate after the concatenation, too.
No arrow for that, though.
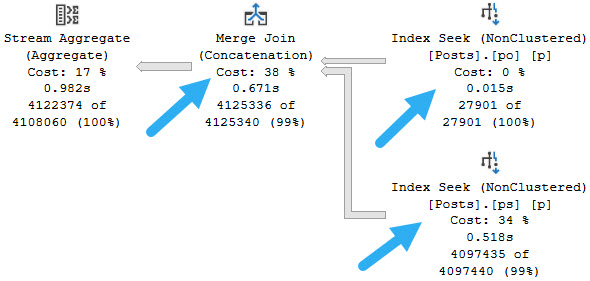
More Wedding
If we use two equality predicates, we’ll get more orderly operations, like merge join concatenation and a stream aggregate.
delancey
What a nice plan.
Wafting
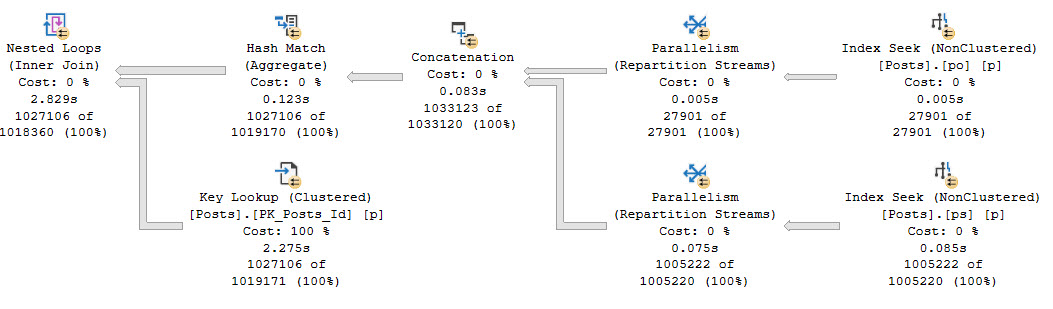
If we add in a column that’s not in either index, we’ll see a similar lookup plan as yesterday’s query.
SELECT
p.PostTypeId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
OR p.Score > 10
GROUP BY p.PostTypeId;
Woah baby look at all that sweet parallelism.
boing boing boing
Big Time
Both index intersection and index union are underappreciated query plan shapes, and represent some pretty cool optimizer strategies to make your queries not stink.
Of course, there are cases where it might make more sense to have one index that covers all necessary key columns, but it’s not always possible to have every index we’d like.
Tomorrow we’ll look at lookups, and some of the finer details of them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The optimizer has a few different strategies for using multiple indexes on the same table:
Lookups (Key or Bookmark)
Index Intersection (Join)
Index Union (Concatenation)
Lookups are between a nonclustered index and either the clustered index or heap, and index intersection and union are between two nonclustered indexes.
Some plans may even have both! How exciting. How very exciting.
Today we’re going to look at index intersection.
Intervals
First, we need a couple useful-ish indexes.
CREATE INDEX pc ON dbo.Posts
(CreationDate);
CREATE INDEX pl ON dbo.Posts
(LastActivityDate);
Next, we’ll need a query with AND predicates on both of those columns:
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20130101'
AND p.LastActivityDate <= '20180101';
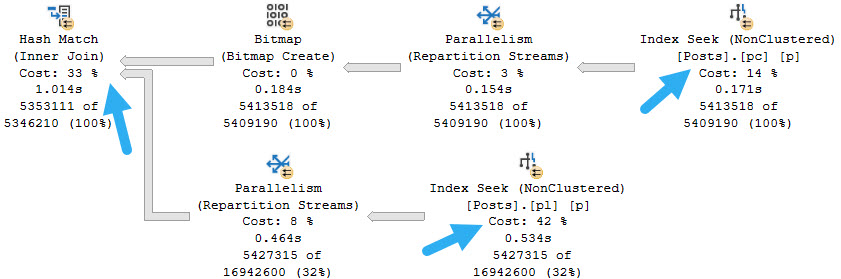
The query plan looks like this:
harsh join
Notice! Both of our nonclustered indexes get used, and without a lookup are joined together.
Because the predicates are of the inequality variety, the join columns are not ordered after each seek. That makes a hash join the most likely join type.
Other Joins
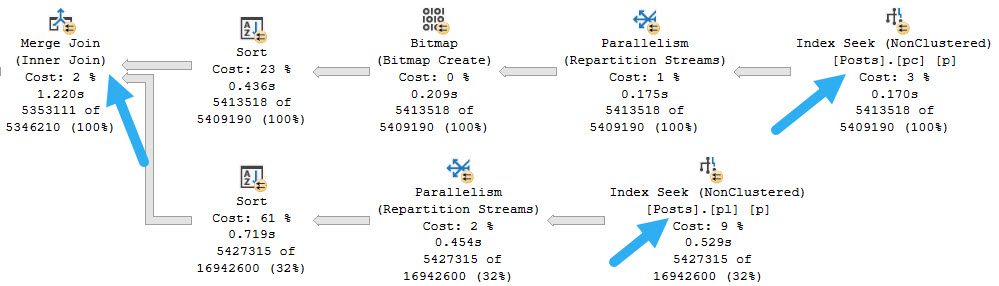
You are unlikely to see a merge join here, because it would require sorting both inputs. You can force one to see for yourself:
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20130101'
AND p.LastActivityDate <= '20180101'
OPTION(MERGE JOIN);
murders and executions
If you attempt to hint a loop join without hinting to use the nonclustered indexes, you will just get one scan of the clustered index.
If you attempt a loop join hint with both indexes hinted, you will get a query processor error.
Serves you right.
Equality Predicates
If you have equality predicates, you may see a merge join naturally.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p WITH(INDEX (pc, pl))
WHERE p.CreationDate = '2010-08-05 10:04:10.137'
AND p.LastActivityDate = '2008-12-25 02:01:25.533';
Look at that sweet double index hint, eh?
no arrows here
Since equality predicates preserve ordering, we don’t need to sort anything here.
You’re welcome.
Plus Lookups
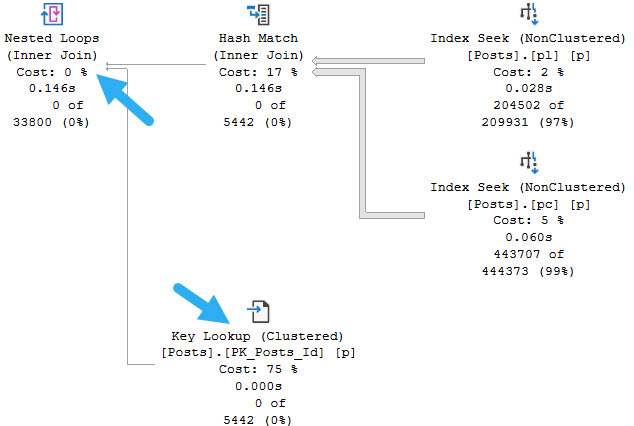
If we request a column that is not present in either index, we’ll get a likely more familiar query plan element.
SELECT
p.PostTypeId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131201'
AND p.LastActivityDate <= '20090101'
GROUP BY p.PostTypeId;
Hooray.
arrows are back
We’re able to use a lookup to retrieve the PostTypeId column from the clustered index. Pretty neat.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The longer you work with data, the more weird stuff you see. I remember the first time I saw a join on a LIKE I immediately felt revolted.
But not every query has an available equality join predicate. For various reasons, like poor normalization choices, or just the requirements of the query, you may run into things like I’m about to show you.
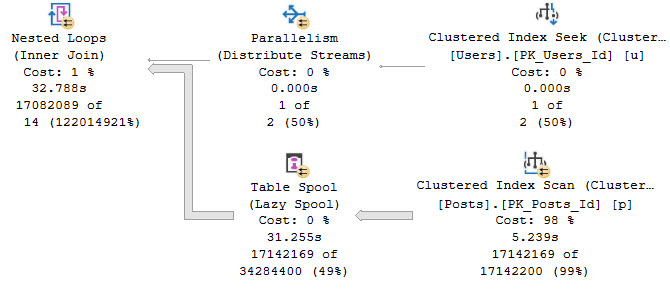
If there’s a headline point to this post, it’s that joins that don’t have an equality predicate in them only have one join choice: Nested Loops. You cannot have a Hash or Merge join with this type of query. Even with the best possible indexes, some of these query patterns just never seem to pan out performance-wise.
There Are Pains
First up, some patterns are less awful than others, and can do just fine with a useful index. Sounds like most other queries, right?
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.LastActivityDate BETWEEN u.CreationDate
AND u.LastAccessDate
WHERE u.Id = 22656;
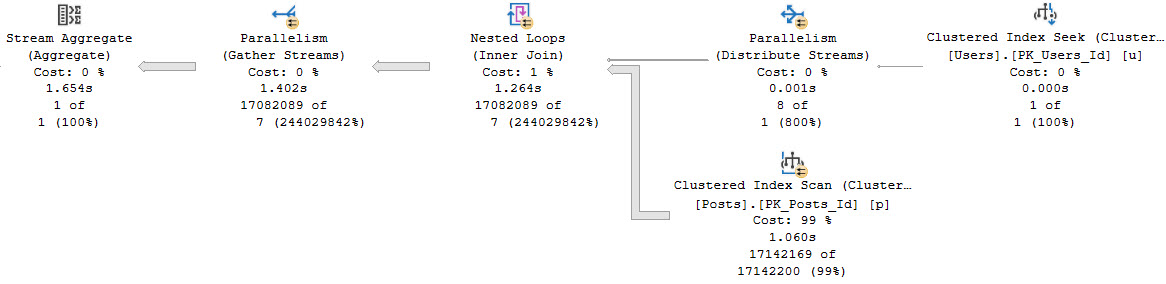
Say we want to count all the posts that were active during Jon Skeet’s active period. This is a simplified version of some interval-type queries.
Even without an index, this does okay because we’re only passing a single row through the Nested Loops Join.
fussy
If our query needs are different, and we threaten more rows going across the Nested Loops Join, things deteriorate quickly.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.LastActivityDate BETWEEN u.CreationDate
AND u.LastAccessDate
WHERE u.Id BETWEEN 22656 AND 22657;
The funny thing here is that there is still only one row actually going through. We’re just threatening additional rows.
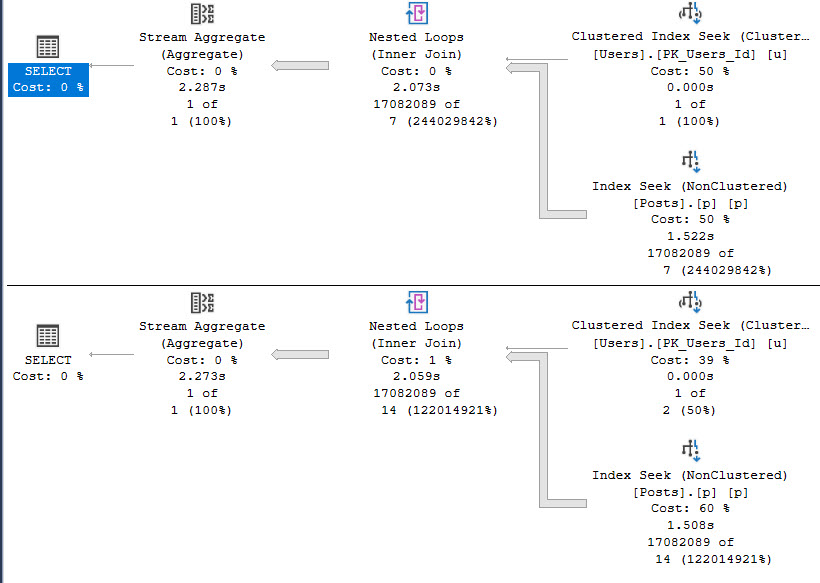
SELECT
u.*
FROM dbo.Users AS u
WHERE u.Id BETWEEN 22656 AND 22666;
How about those identity values, kids?
specify
Here’s what happens, though:
suspect device
There Are Indexes
Indexing only LastActivityDate “fixes” the multi-row query, but…
CREATE INDEX p ON dbo.Posts(LastActivityDate);
regressed
Parallelism being deemed unnecessary slows the access of the Posts table down, which is something we’ve seen before in other entries in this series. That costs us roughly 500 milliseconds in the first query, but saves us about 30 seconds in the second query. I’d probably take that trade.
And Then There Are Pains
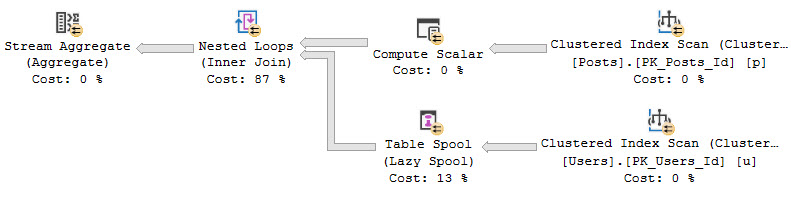
Where things get more painful is with correlations like this.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.DisplayName LIKE '%' + p.LastEditorDisplayName + '%'
WHERE p.PostTypeId = 1;
This query runs basically forever. I gave up on it after several minutes, so you’re only getting the estimated plan.
ehhh
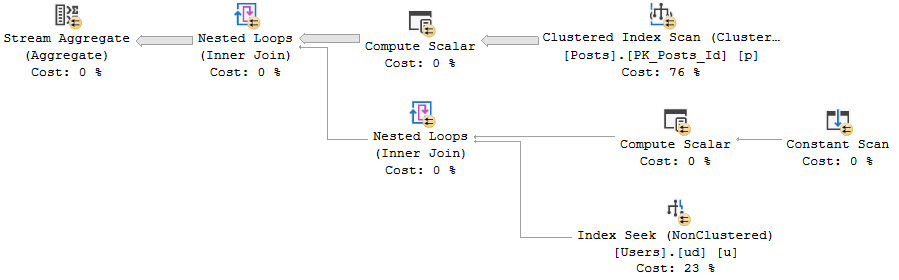
The query plan asks for an index on the Users table! Surely this will solve all our problems.
CREATE INDEX ud ON dbo.Users(DisplayName);
This query, likewise, doesn’t seem too keen on finishing. But we get a new index request along with it.
helipad
This never finishes either. By “never” I mean “I’d like to write about more things so I’m not sitting around waiting for this.”
Sorry.
And Then There Are More Indexes
An index on PostTypeId that includes LastEditorDisplayName. I’m going to flex a little on SQL Server and create this index instead:
CREATE INDEX pl ON dbo.Posts(LastEditorDisplayName)
WHERE PostTypeId = 1
Unfortunately, all this does is change which index is used. It doesn’t improve the performance of the query at all.
But this series is about query plan patterns, so let’s talk about some of those.
Amoral
Like I mentioned at the start of the post, the optimizer only has a single join strategy for queries with no equality predicates on the join condition. This can lead to very bad performance in a number of cases.
In cases where a single row is being passed across, and the query plan shows a single seek or scan on the inner side of the Nested Loops Join, performance will likely be… acceptable.
When you see Spools or Constant Scans on the inner side of the Nested Loops Join, this could be cause for concern. For some details on that, have a look at these links:
After all, even the LIKE predicate is tolerable with appropriate indexes and a single row from the outer side.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.DisplayName LIKE '%' + p.LastEditorDisplayName + '%'
WHERE u.Id = 22656
AND p.PostTypeId = 1;
wild
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Bitmaps can be really useful in parallel hash and merge join plans. They can be used like sargable, but not seekable, predicates.
Where they get created and where they get used is a bit different,
triple x
10/10
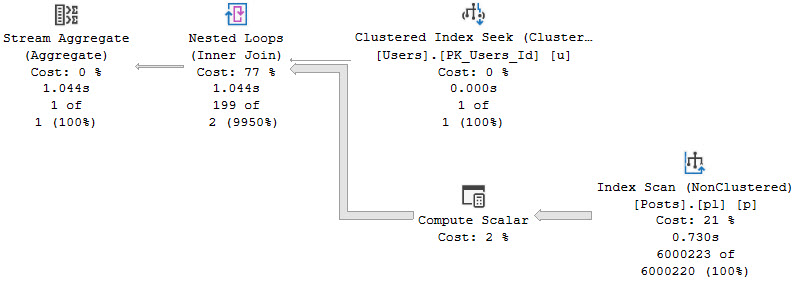
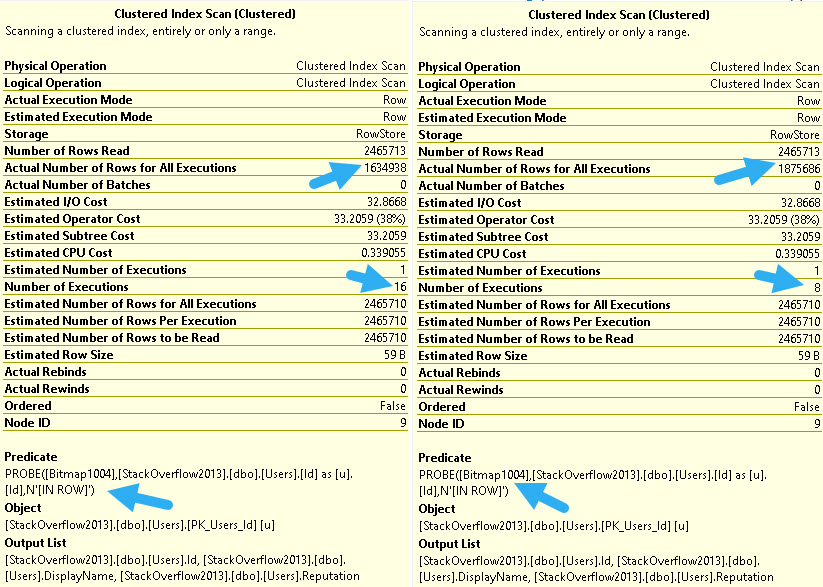
When bitmaps do their job, you can tell. For example, here’s an example of an effective bitmap:
impressionable
At the index scan, we filter out all but around ~40k rows from the Users table.
That’s uh… Eh you can find a percentage calculator.
0/10
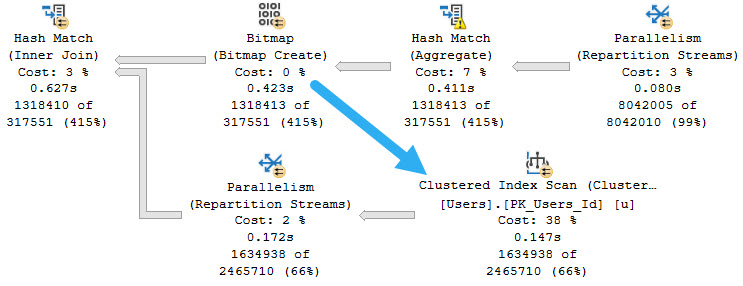
When they don’t, you can also tell. This bitmap hardly eliminates any rows at all.
down down down
But wait! This query runs at DOP 4. You can tell by looking at the number of executions.
Who runs queries at DOP 4?
Fools.
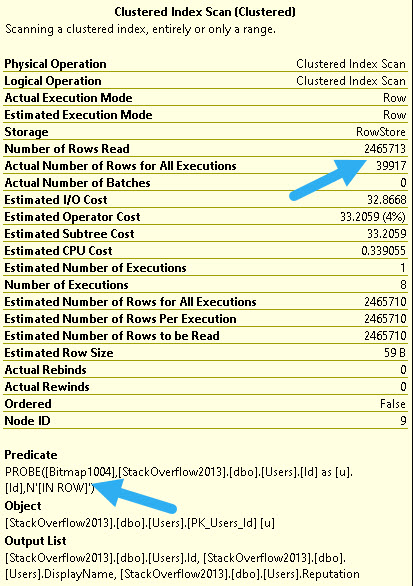
40/40
At higher DOPs, that useless bitmap becomes much more effective.
OBSERVE IF YOU WILL
At DOP 8, we filter out about 600k rows, and at DOP 16 we filter out about 830k rows.
99/1
Like many operators in query plans, Bitmaps aren’t parallel “aware”, meaning there will be one Bitmap per thread.
At times, if you find a Bitmap underperforming at a lower DOP, you may find some benefit from increasing it.
Of course, you may also find general relief from more threads working on other operators as well. Sometimes more CPU really is the answer to queries that process a whole bunch of rows.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
But weird things can happen along the way, especially if you don’t have supporting indexes, or if supporting indexes aren’t chosen by the optimizer for various reasons.
In this post, I’m going to show you a query plan pattern that can occur in semi-join plans, and what you can do about it.
Row Goalies
This can happen without a TOP in the query, I’m only using it because it gets me the plan shape I care about quickly, and returns results “quickly” enough.
SELECT TOP (1)
c.*
FROM dbo.Comments AS c
WHERE NOT EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE c.PostId = v.PostId
)
ORDER BY c.CreationDate DESC;
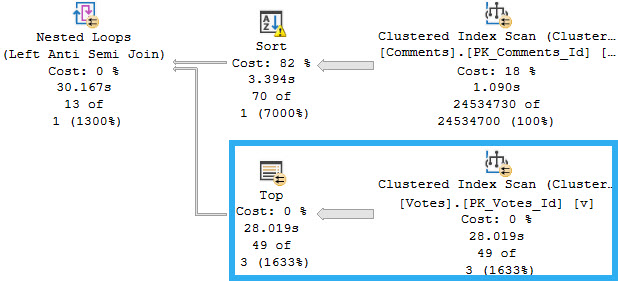
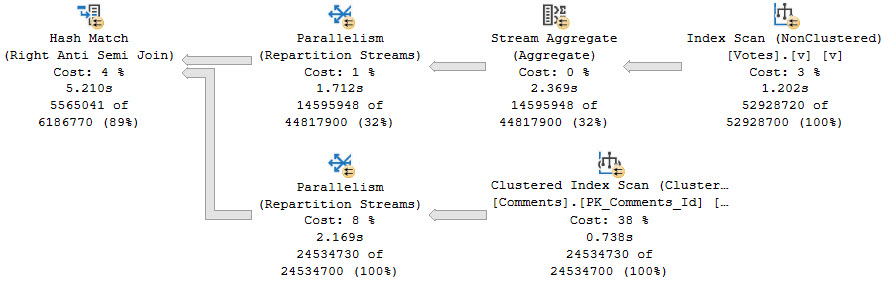
The part of the plan that we care about is on the inner side of the semi join, where the TOP is applied in a funny way.
just party
This is a very good example of where query costing can be quite off. The part of the plan that is responsible for most of the runtime is estimated to cost 0% of the total cost.
Closer
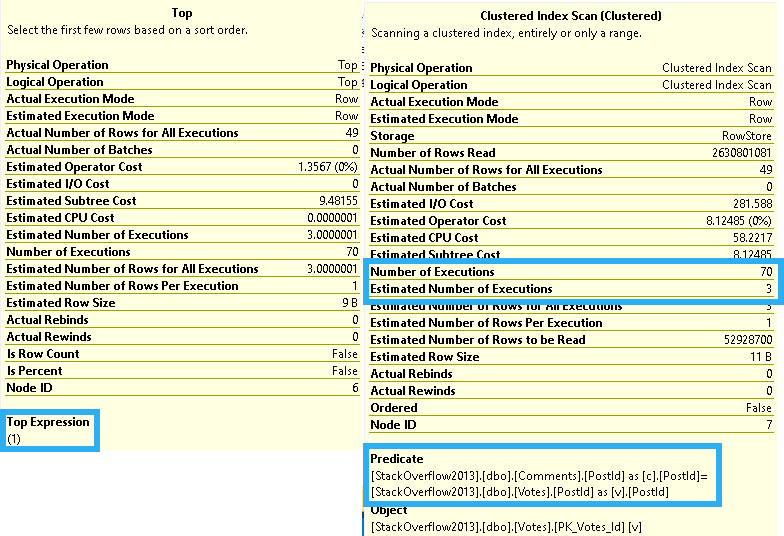
Here’s what’s going on in those two operators!
rock show
The optimizer thinks it can find a matching row in three executions, but it takes 70.
It also takes reading 2,630,801,081 rows to return 49 rows. There are 52,928,700 rows in the table.
Yes, if you multiply 52928700 * 49 = 2630801081. Technically it’s 49.7, but the plan shows rounded numbers. Close enough for the optimizer, so they say.
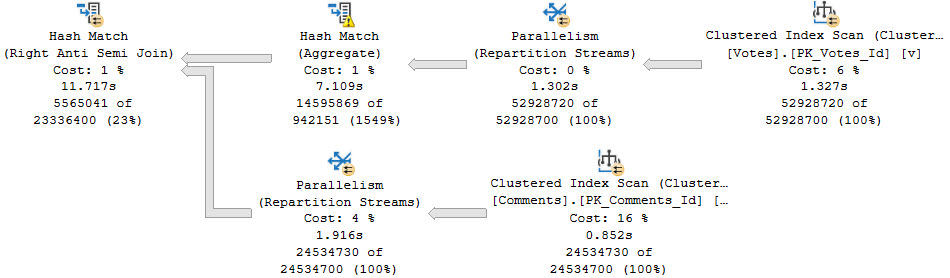
Index Not Exists
Without an index, a hash join plan would have been a much better option, which we can get by adding an OPTION(HASH JOIN) hint to the query.
freeloader
While ~12 seconds is great, we can do better. I’ve heard about these things called indexes.
How do we indexes?
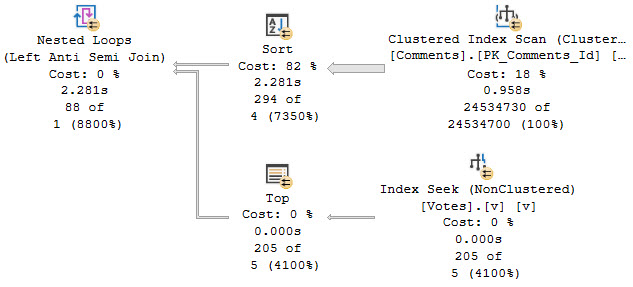
An Index, You Say
It looks straight forward to create an index that should get us the plan we want, if we create it on the PostId column on the Votes table.
CREATE INDEX v ON dbo.Votes(PostId);
Assuming that the plan shape otherwise stays the same, we’ll scan the Comments table, Sort by PostId, and then do a Seek into the Votes table on the inner side of the join.
Right?
wrong
While it is quite a bit faster, it’s not at all what we want. And hey, look, the costs and times here are all screwy again.
Stop looking at costs.
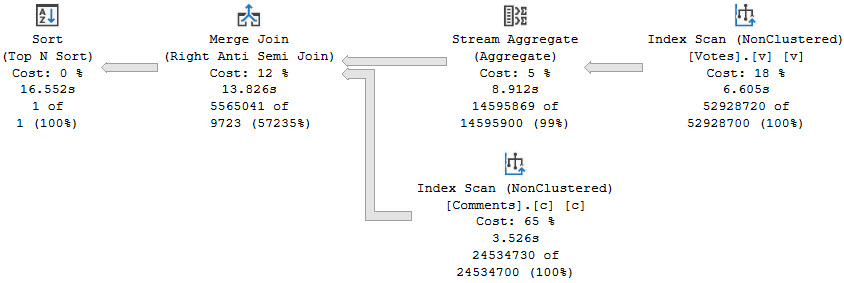
Adding a FORCESEEK hint gets us the plan shape we care about, of course:
SELECT TOP (1)
c.*
FROM dbo.Comments AS c
WHERE NOT EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v WITH(FORCESEEK)
WHERE c.PostId = v.PostId
)
ORDER BY c.CreationDate DESC;
Along with a much faster runtime:
premium tears
Gosh Wrong
If you’re keeping score at home, the optimizer chose:
A TOP > Scan that took 30 seconds instead of a Hash Join that took 11 seconds
A Hash Join that took 5.2 seconds instead of a Top > Seek that took 2.2 seconds
But I bet I know what you’re thinking. We need an index on the Comments table. And I bet you’re thinking it should look something like this:
CREATE INDEX c ON dbo.Comments
(PostId, CreationDate)
INCLUDE
(Score, UserId, Text);
But, prepare you biggest internet sigh, that just won’t work out.
and tears
Much like above, if we add a FORCESEEK hint, we get a better/faster plan that looks a lot like the plan above.
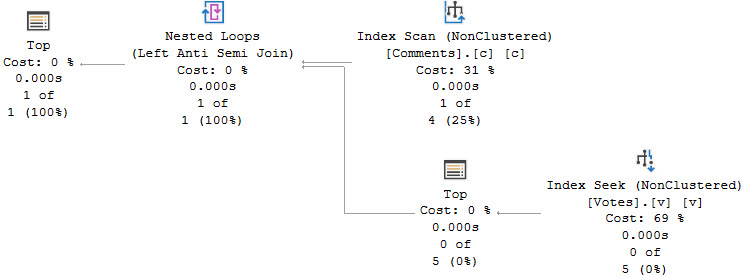
Flip That Script
The only index that gets us a respectable execution plan without a bunch of hints is this one:
CREATE INDEX c ON dbo.Comments
(CreationDate, PostId)
INCLUDE
(Score, UserId, Text);
Which gets us this execution plan:
what i want
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.