Zip Zap Fast
Parallel queries were originally conceived of by David Lee Roth in 198X. He doesn’t remember exactly. It’s cool.
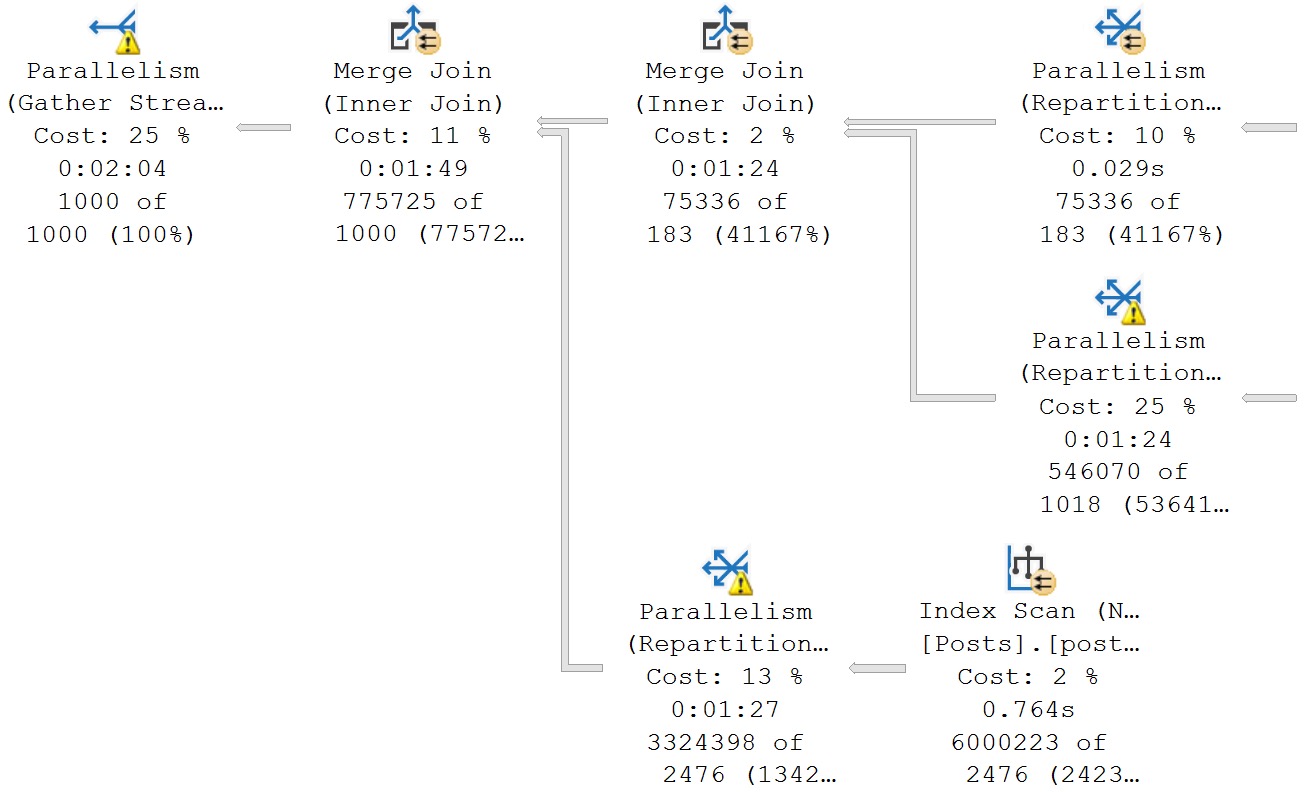
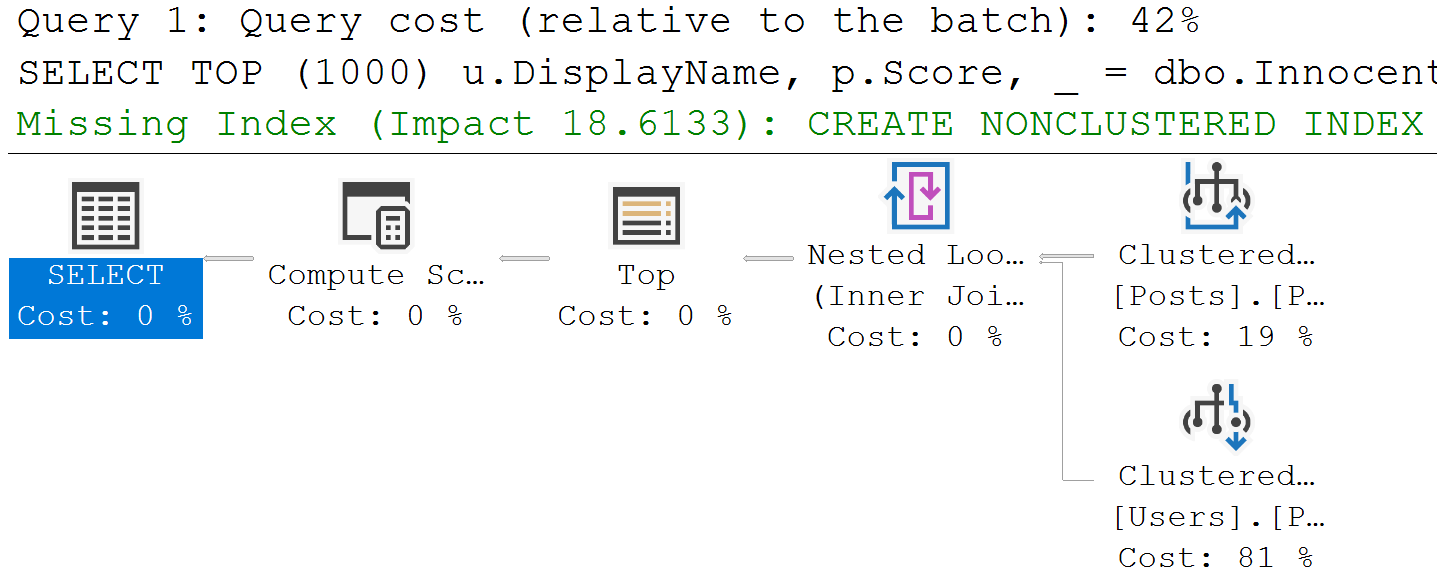
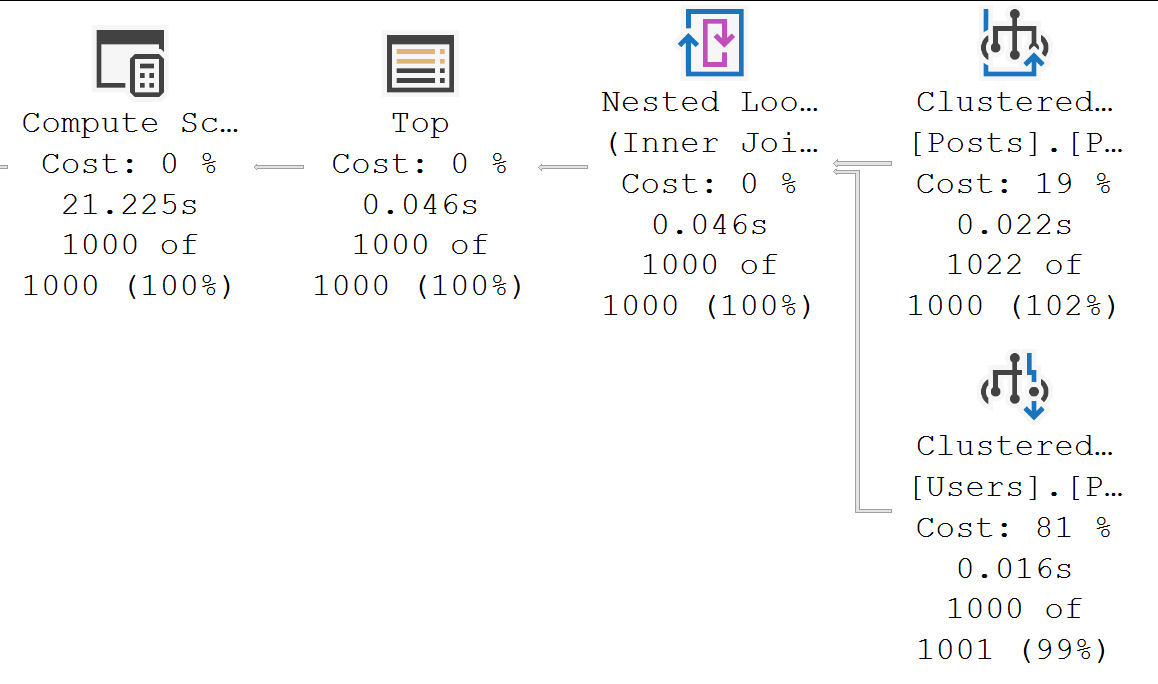
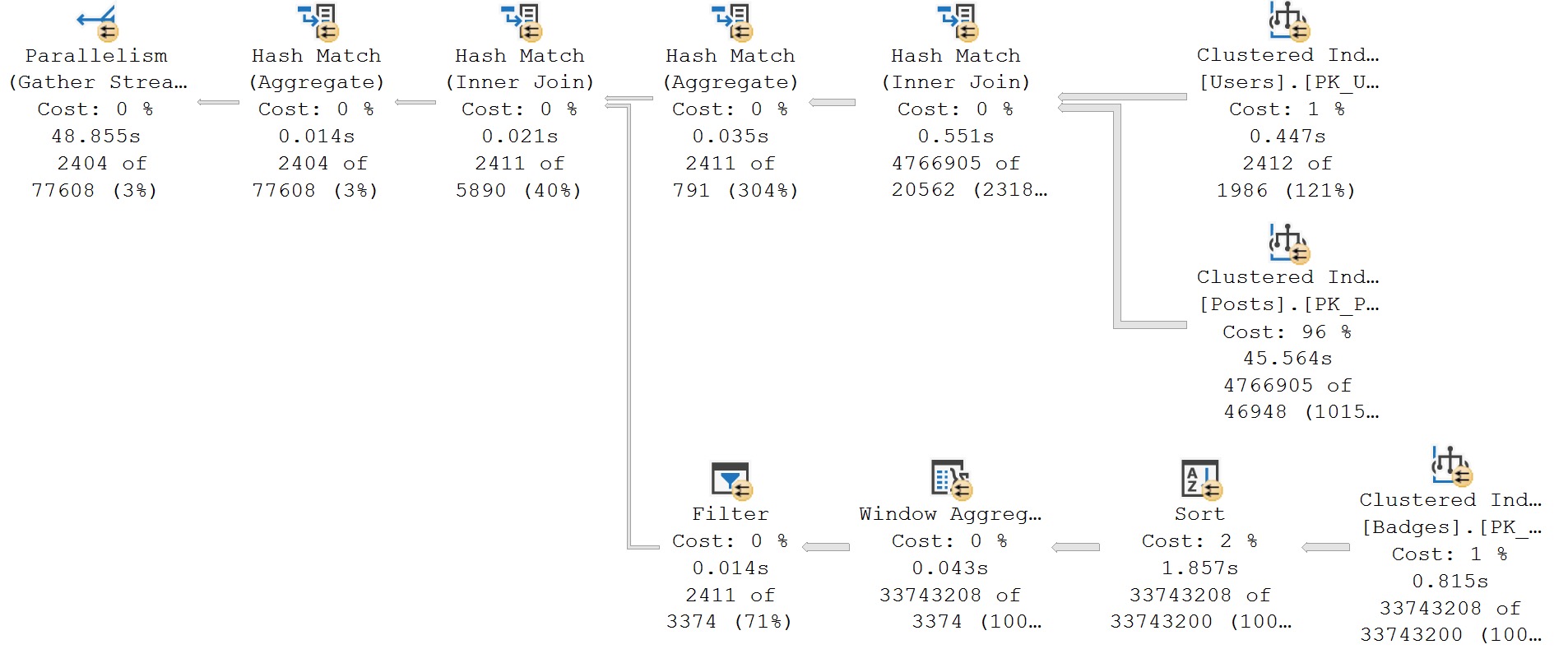
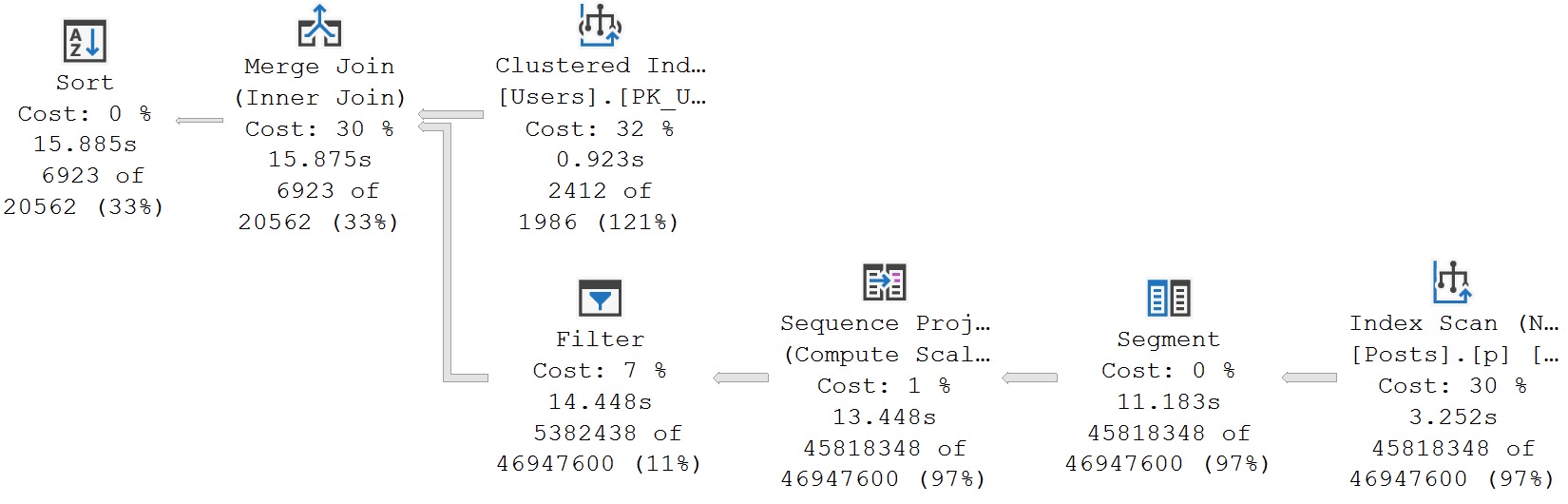
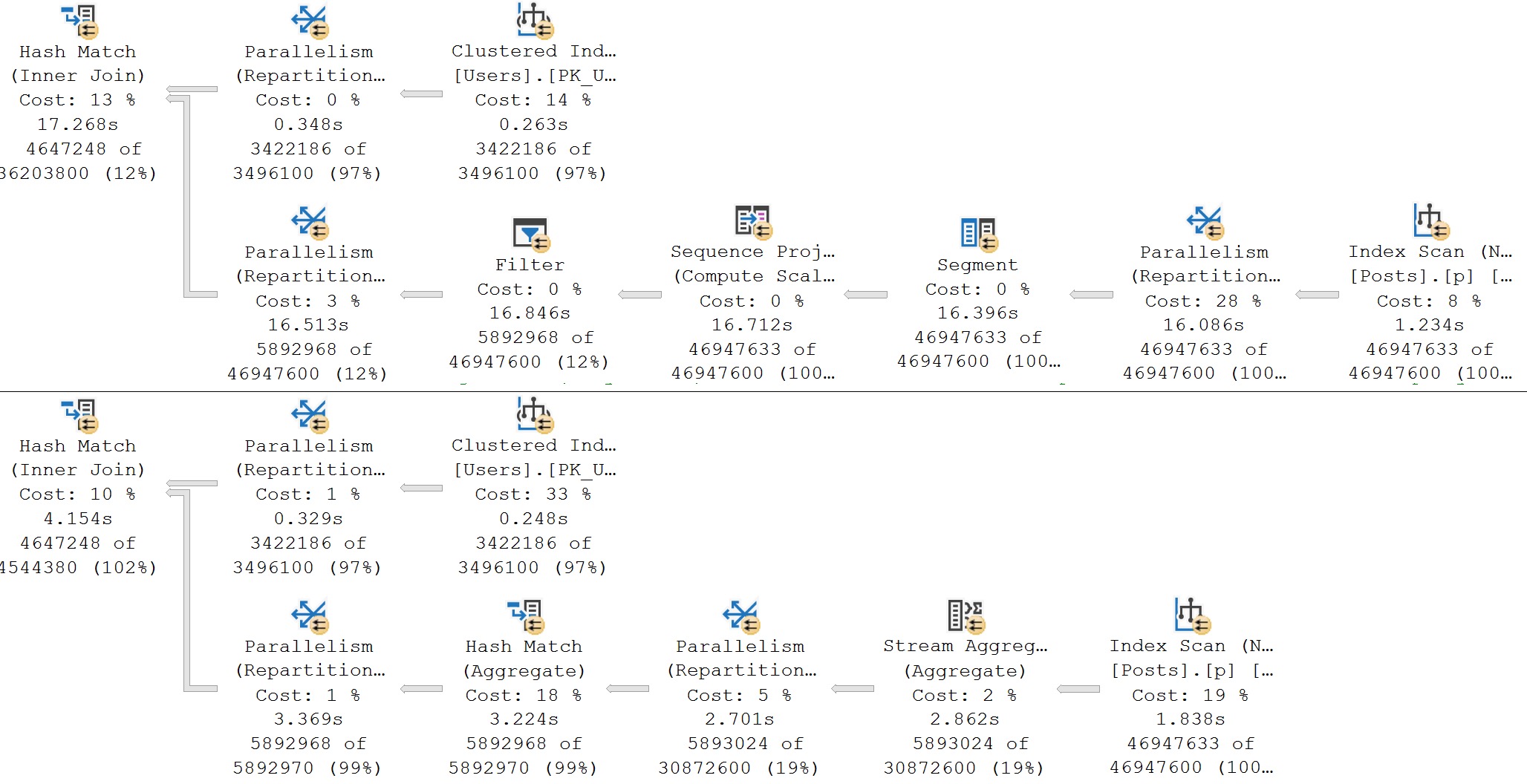
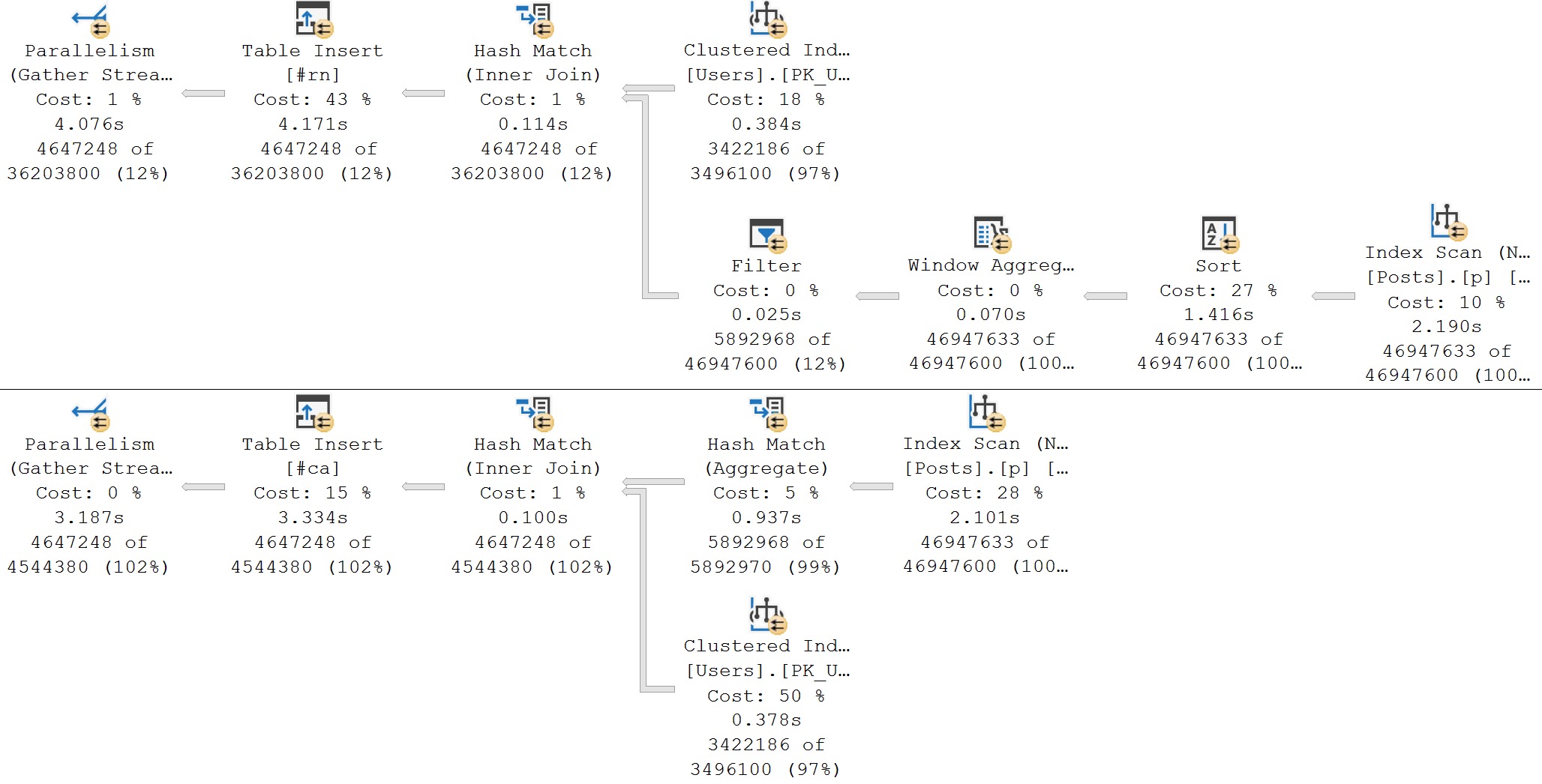
In some cases, they’re the only reasonable option. If your query is processing millions of rows, spreading them out across a bunch of worker threads will reduce wall clock time (assuming nothing goes terribly, horribly wrong elsewhere).
It doesn’t necessarily increase CPU time, though. Again, perfect world (we’re optimists here at Darling Data):
- One thread processing 8 million rows takes one 8 seconds
- Eight threads processing 1 million rows a piece takes 1 second
Either way, you’re looking at 8 seconds of CPU time, but it changes how that’s spread out and who feels it.
- On a single thread, it happens over eight person-seconds to a human being
- One eight threads, it happens over 1 person seconds, but the “strain” is on the CPUs doing extra work
Your Own Parallel Query
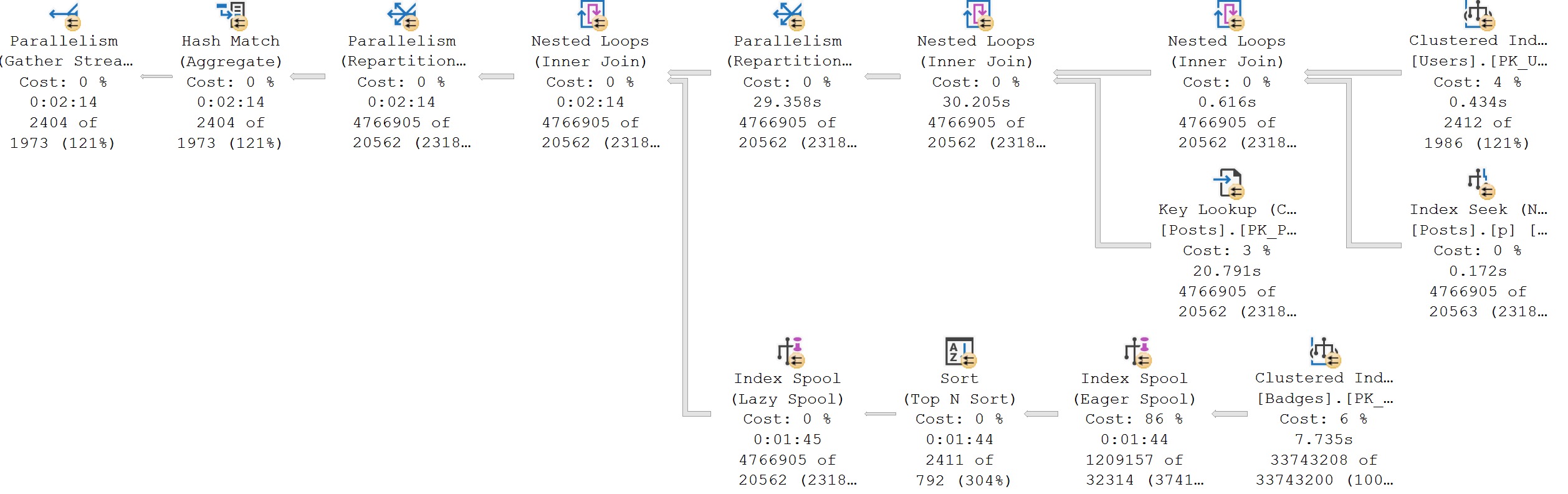
In my corner of the query tuning world, parallelism is the only way to speed up some queries. There’s only so much work you can stick on one thread and get it going faster.
Often, queries aren’t going parallel because of some limiting factor:
- Scalar UDFs anywhere near the vicinity
- Inserting to table variables
- Linked server queries
- Cursor options
There are also times when every query is going overly-parallel because:
- Folks are using the default MAXDOP and Cost Threshold For Parallelism settings
- No one is tuning queries and indexes to keep estimated costs under control
- Entity Framework, Entity Framework, Entity Framework
- Your vendor is a bunch of Vogons and their queries are “poetry”
Neither situation is ideal.
Why Getting Settings Right Is So Tough
We all know the default suck. MAXDOP at 0 and Cost Threshold For Parallelism at 5 is dumb for anything north of Northwinds.
Check out this video to hear my thoughts on it:
Accosted
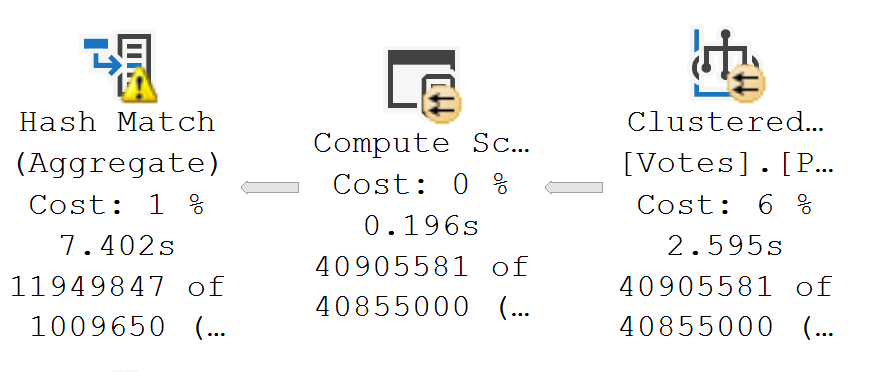
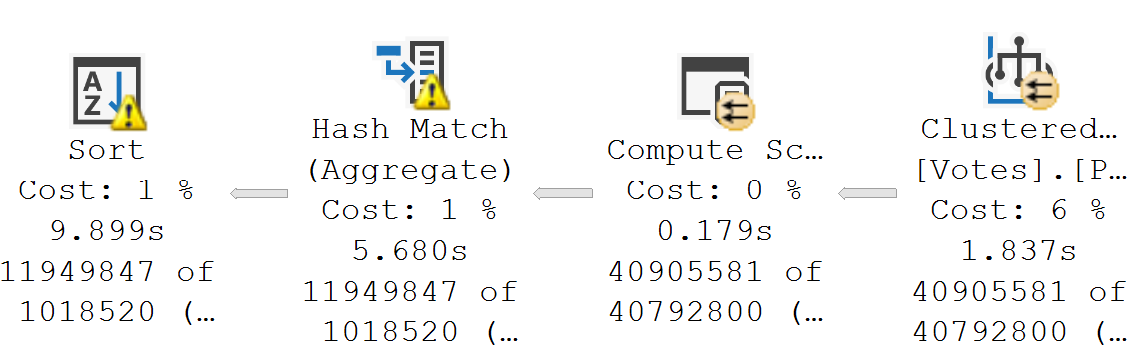
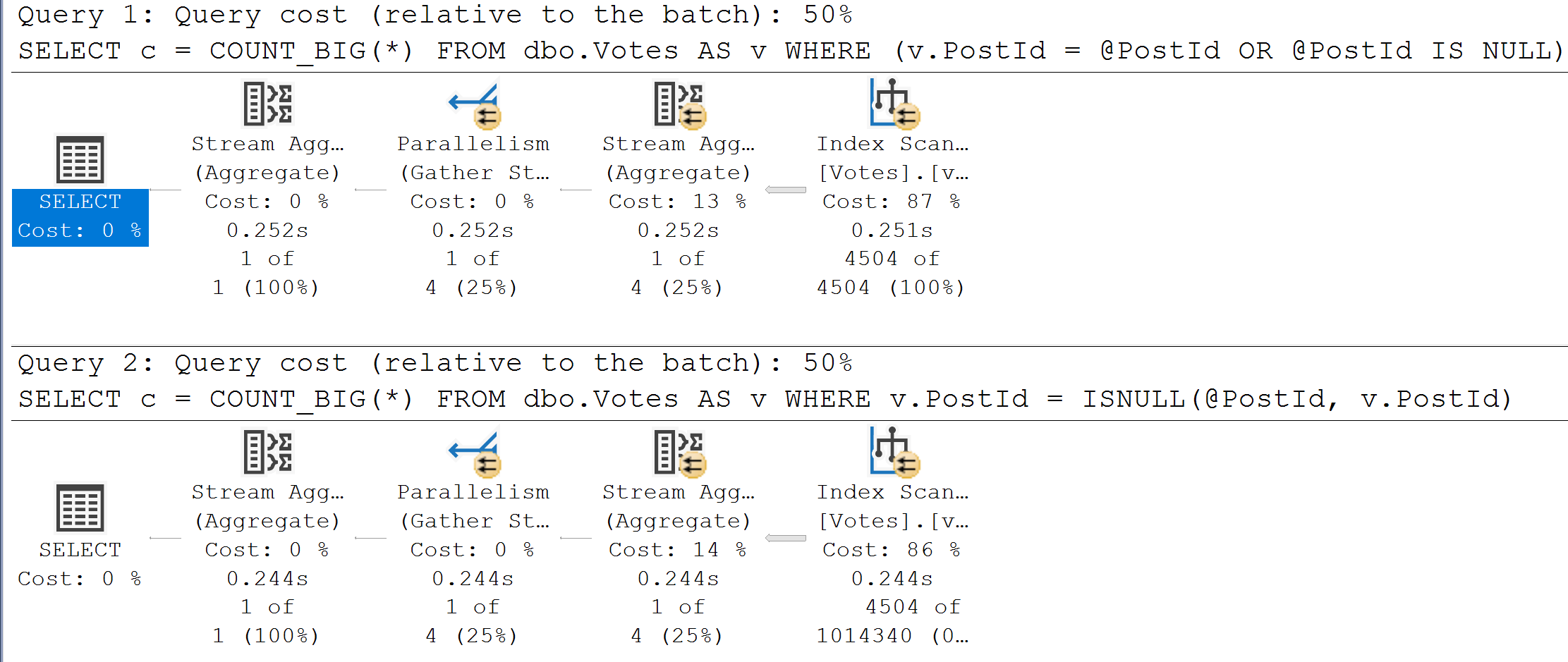
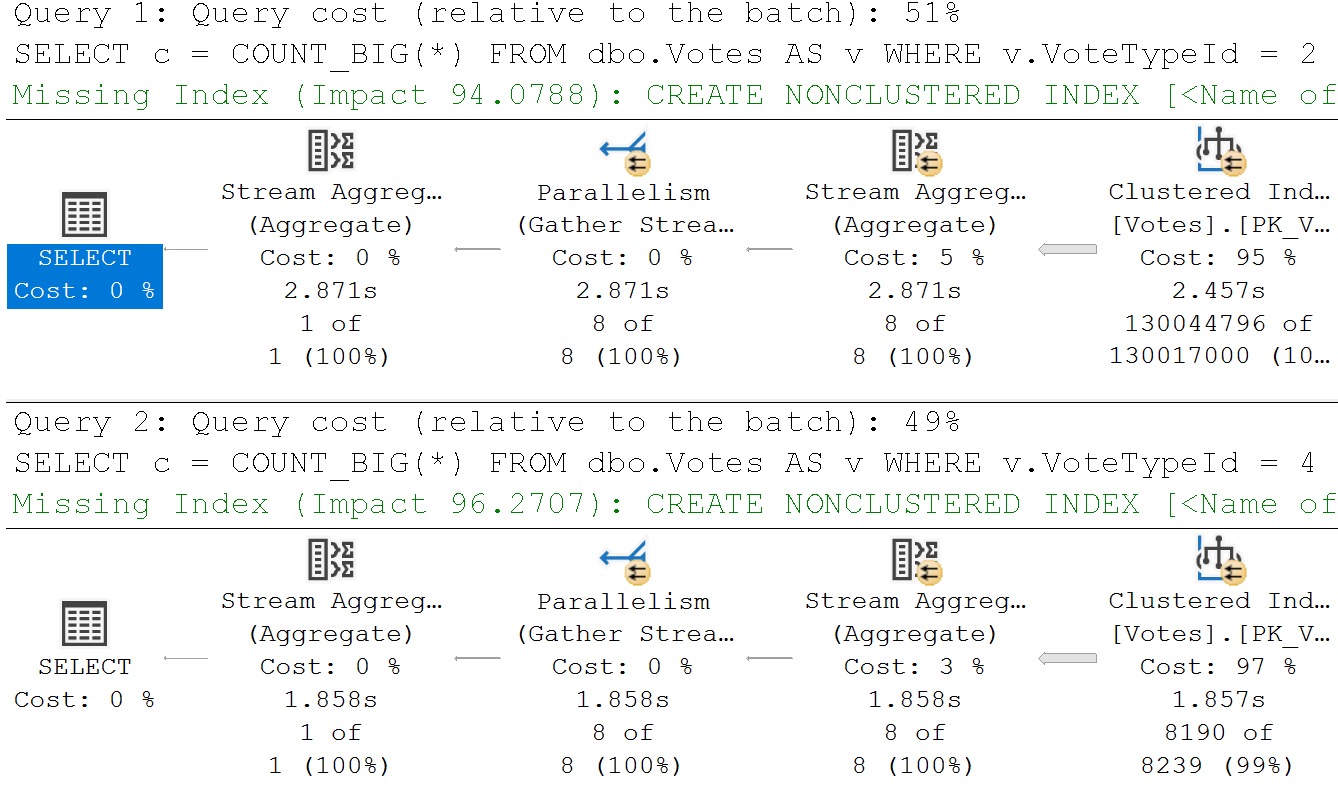
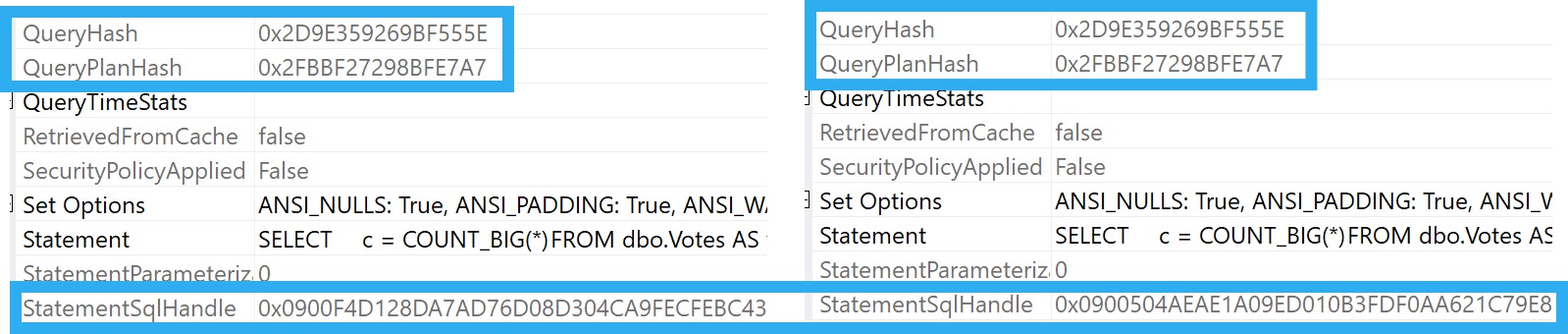
The other thing that’s really tough to reason out about setting Cost Threshold For Parallelism is that every single thing related to cost you see, whether it’s for the entire plan, or just a single operator, is an estimate.
Estimates are… Well, have you ever gotten one? Has it ever been 100%? If you’ve ever hired a contractor, hoo boy. You’re sweating now.
Expensive queries can be fast. Cheap queries can be slow. Parameterized queries can be cheap and fast, but if you get into a situation with bad parameter sniffing, that cheap fast plan can turn into an insufferable relationship.
Yeah, I’m one of those people who usually starts off by bumping Cost Threshold For Parallelism to 50. It’s reasonable enough, and I don’t get married to it. I’m open to changing it if there’s evidence that’s necessary. Plus, it’s pretty low risk to experiment with.
My dear friend Michael J Swart has a Great Post about measuring changes to it here.
The important thing to keep in mind with any of these settings, aside from the defaults being bad, is that you’re not setting them with the goal of eliminating CXPACKET and CXCONSUMER waits completely. Unless you’re running a pure virgin OLTP system, that’s a real bad idea.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.