Groove Is In The Heart
When Brent posted about the availability of, and disappointment with creating ordered column store indexes in SQL Server 2022, I got to work.
I can’t have my dear friend Brent being all distraught with all those fast cars around. That’s how accidents happen, and I fear he might leave the Blitz scripts to me in his will or something.
Anyway, I decided to dig in and see what was going on behind the scenes. Which of course, means query plans, and bothering people who are really good at debuggers.
Most of the problems that you’ll run into in SQL Server will come from sorting data.
Whenever I have to think about Sorts, I head to this post about all the different Sorts you might see in a query plan.
More on that later, though.
Cod Piece
In Paul’s post, he talks about using undocumented trace flag 8666 to get additional details about Sort operators.
Let’s do that. Paul is smart, though he is always completely wrong about which season it is.
DROP TABLE IF EXISTS
dbo.Votes_CCI;
SELECT
v.*
INTO dbo.Votes_CCI
FROM dbo.Votes AS v;
I’m using the Votes table because it’s nice and narrow and I don’t have to tinker with any string columns.
Strings in databases were a mistake, after all.
DBCC TRACEON(8666);
CREATE CLUSTERED COLUMNSTORE INDEX
vcci
ON dbo.Votes_CCI
ORDER (Postid);
DBCC TRACEOFF(8666);
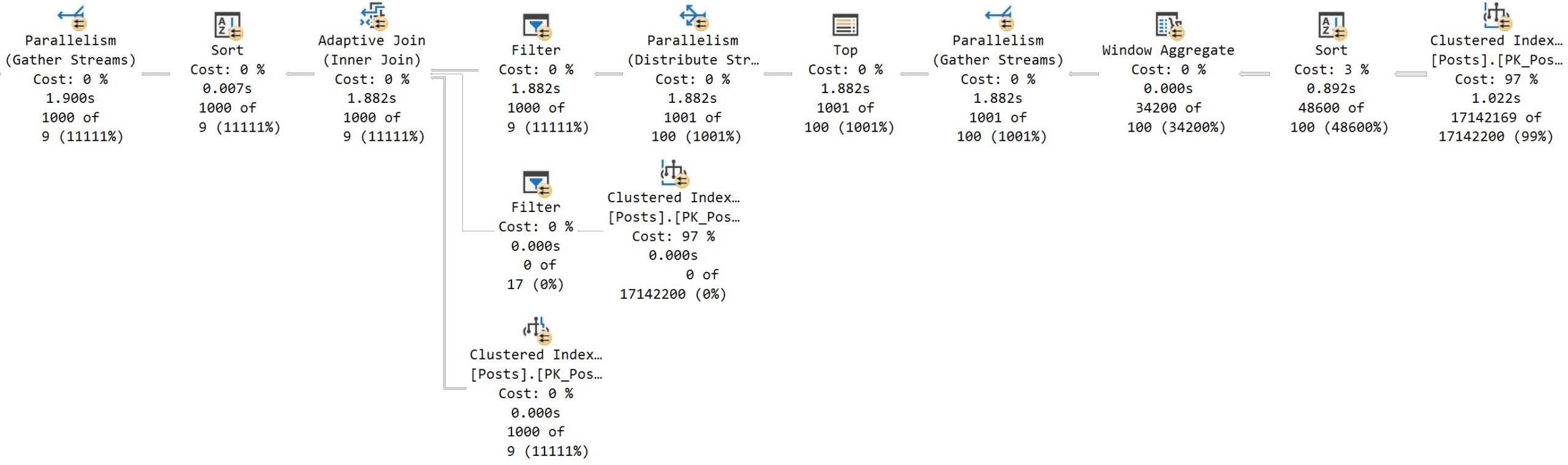
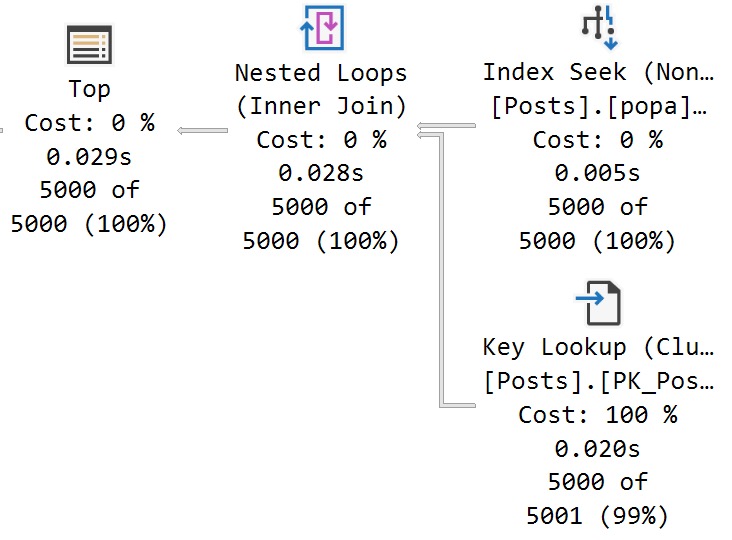
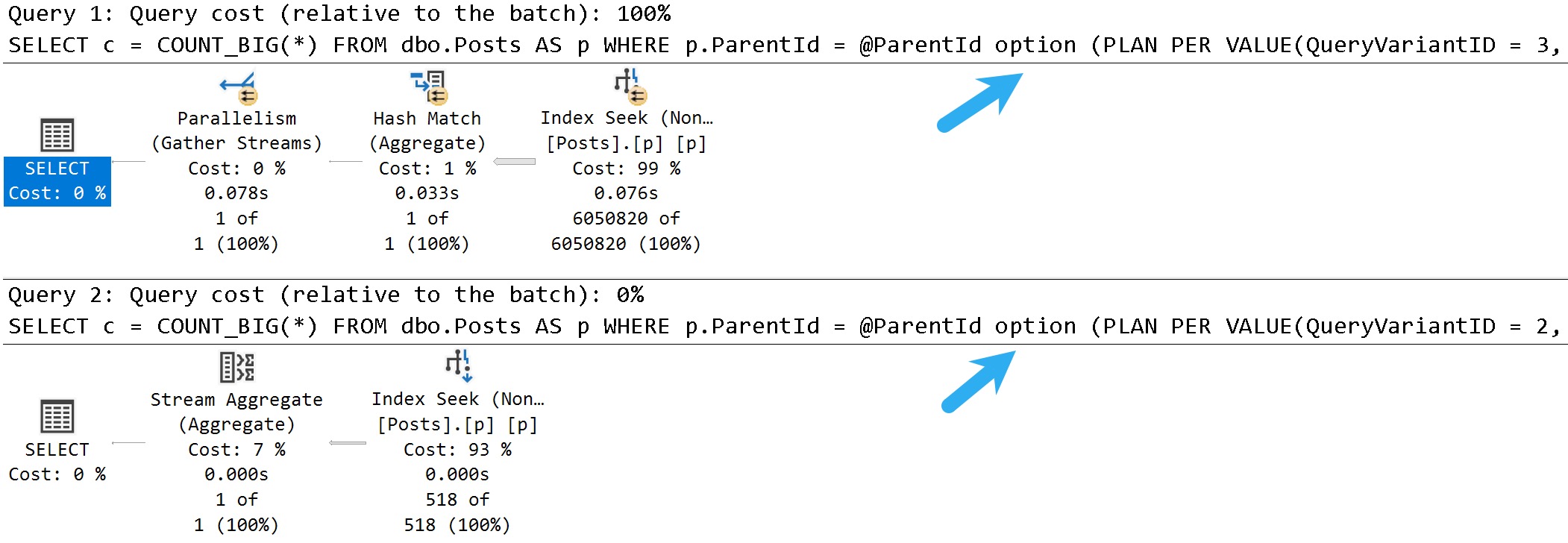
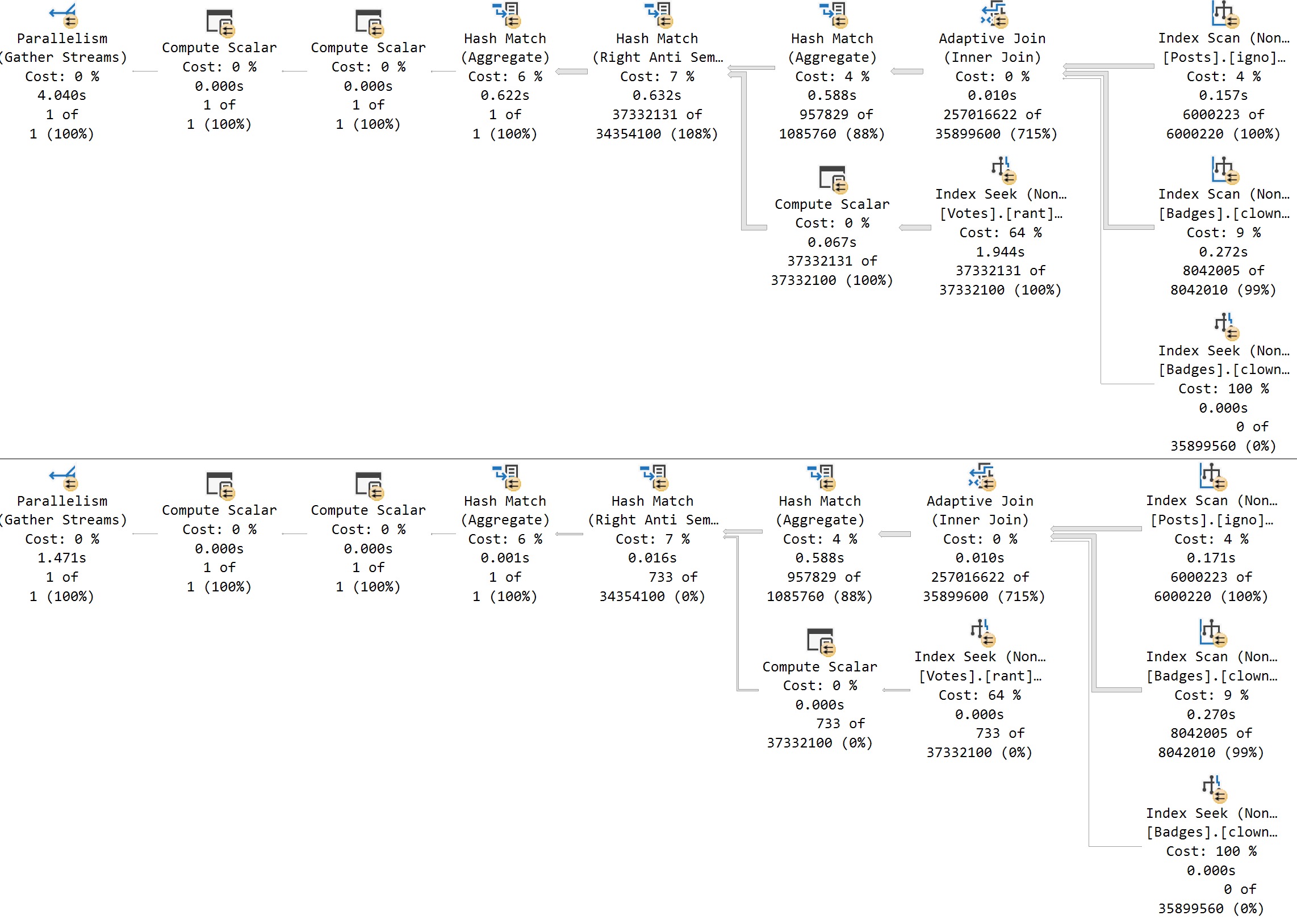
Here’s what we get back in the query plan:
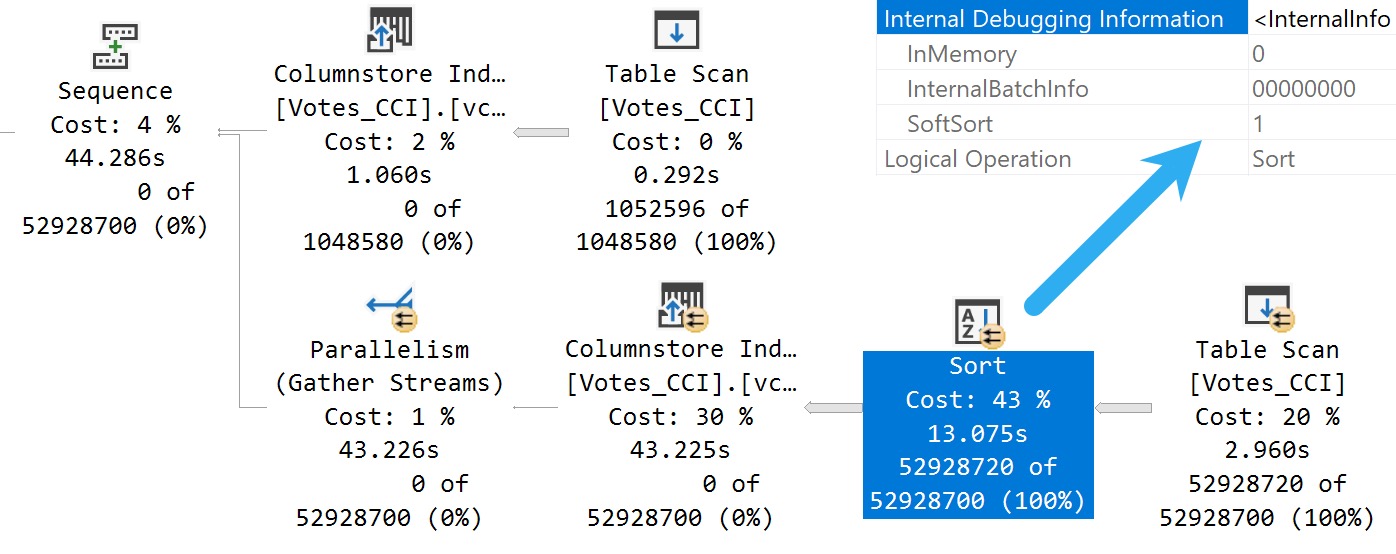
We’ve got a Soft Sort! What does our seasonally maladjusted friend say about those?
A “soft sort” uses only its primary memory grant and never spills. It doesn’t guarantee fully-sorted output. Each sort run using the available memory grant will be sorted. A “sort sort” represents a best effort given the resource available. This property can be used to infer that a Sort is implemented with CQScanPartitionSortNew without attaching a debugger. The meaning of the InMemory property flag shown above will be covered in part 2. It does not indicate whether a regular sort was performed in memory or not.
Well, with that attitude, it’s not surprising that there are so many overlapping buckets in the column store index. If it’s not good enough, what can you do?
Building the index with the Soft Sort here also leads to things being as bad as they were in Brent’s post.
Insert Debugging Here
Alas, there’s (almost) always a way. Microsoft keeps making these trace flag things.
There are a bunch of different ways to track them down, but figuring out the behavior of random trace flags that you may find just by enabling them isn’t easy.
One way to tie a trace flag to a behavior is to use WinDbg to step through different behaviors in action, and see if SQL Server checks to see if a trace flag is enabled when that behavior is performed.
If you catch that, you can be reasonably sure that the trace flag will have some impact on the behavior. Not all trace flags can be enabled at runtime. Some need to be enabled as startup options.
Sometimes it’s hours and hours of work to track this stuff down, and other times Paul White (b|t) already has notes on helpful ones.
The trace flag below, 2417, is present going back to SQL Server 2014, and can help with the Soft Sort issues we’re seeing when building ordered clustered column store indexes today.
Here’s another one:
DBCC TRACEON(8666, 2417);
CREATE CLUSTERED COLUMNSTORE INDEX
vcci
ON dbo.Votes_CCI
ORDER (Postid)
WITH(MAXDOP = 1);
DBCC TRACEOFF(8666, 2417);
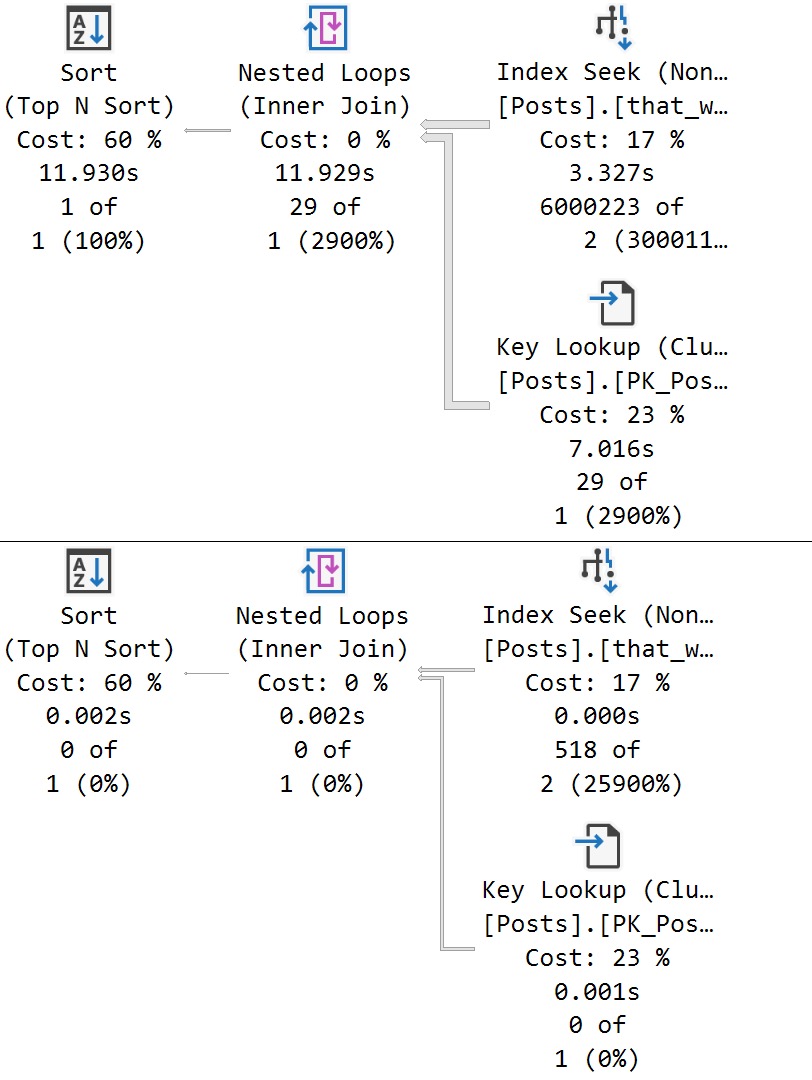
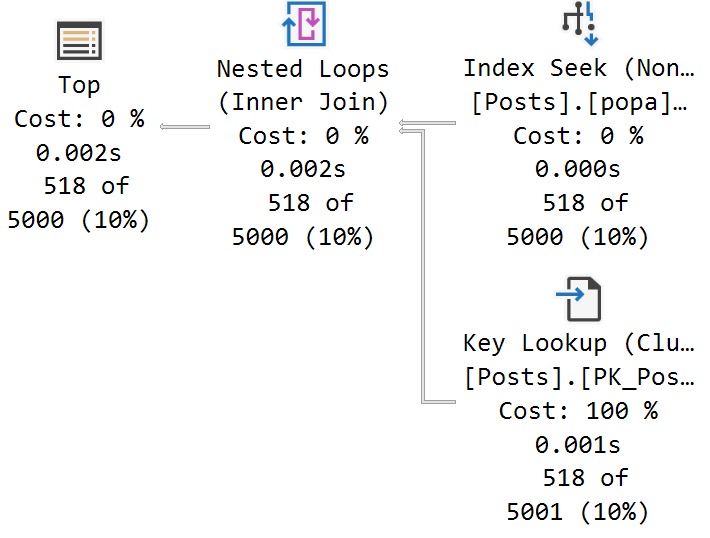
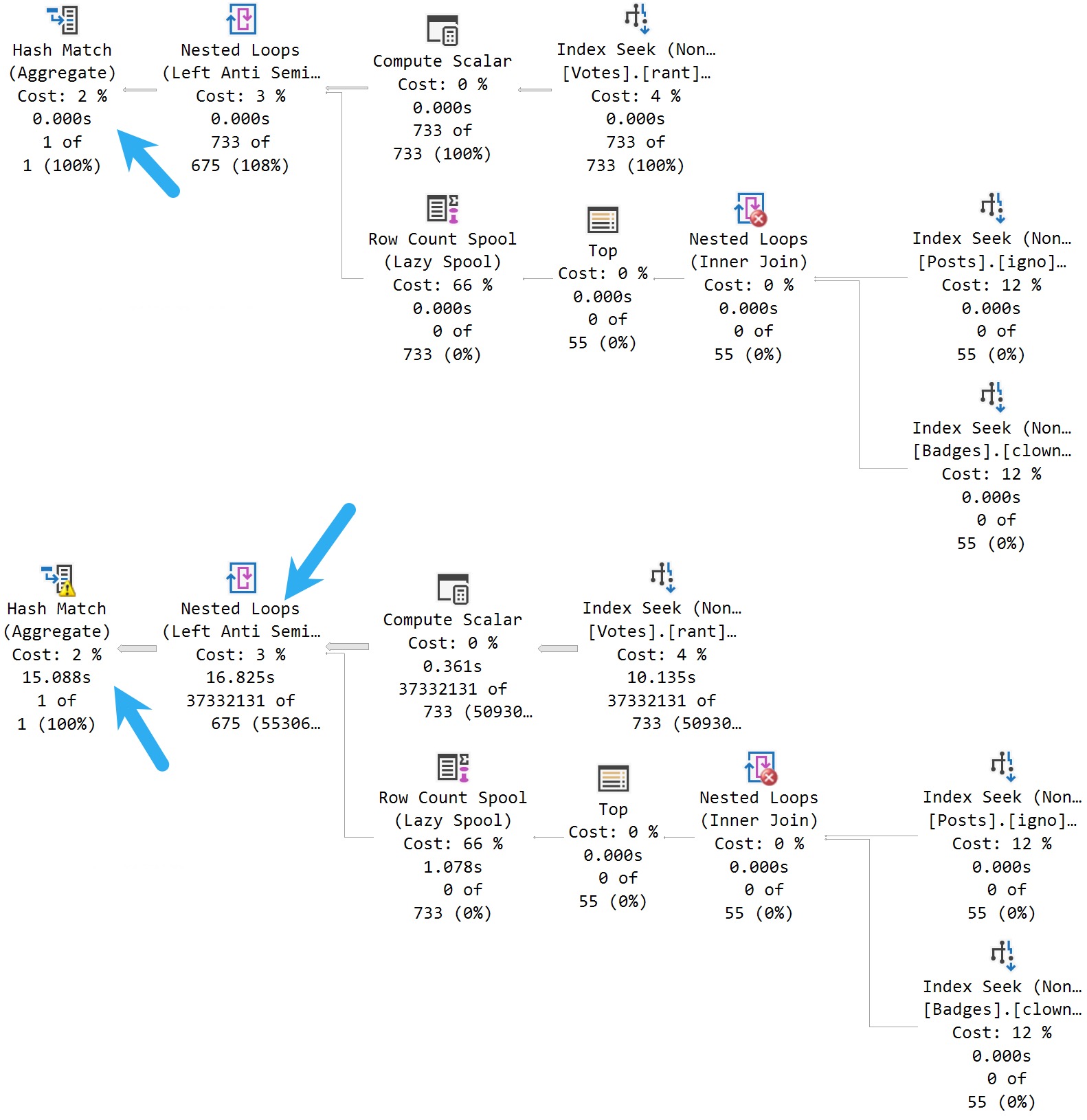
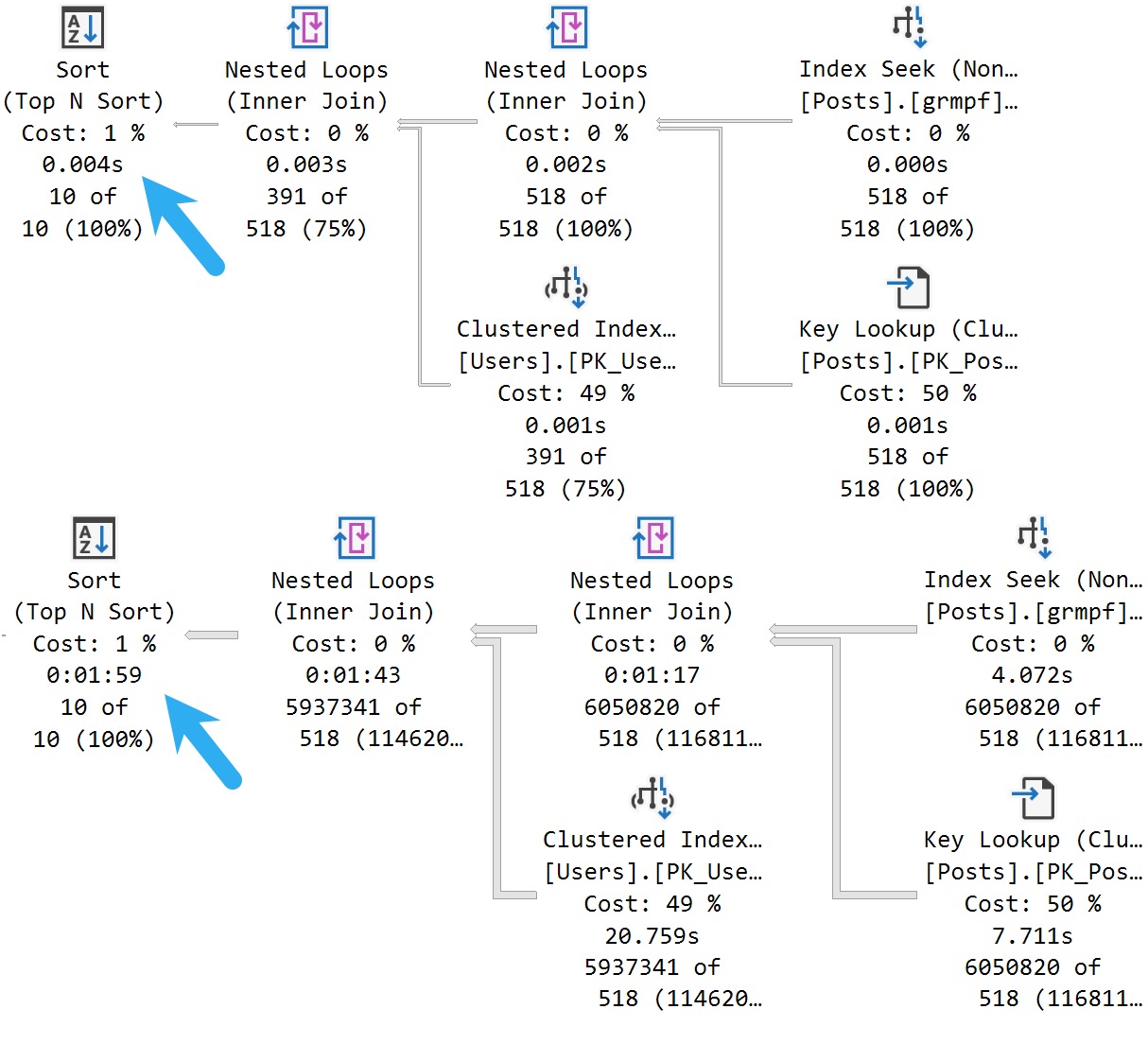
The MAXDOP 1 hint isn’t strictly necessary. With a parallel plan, you may see up to DOP overlapping row groups.

That’s why it was a popular maneuver to emulate this behavior by creating a clustered row store index, and then create a clustered column store index over it with drop existing and a MAXDOP 1 hint.
At DOP 1, you don’t see that overlap. It takes a lot longer of course — 3 minutes instead of 30 or so seconds — which is a real bummer. But without it, you could see DOP over lapping rowgroups.
If you want All The Pretty Little Rowgroups, this is what you have to do.
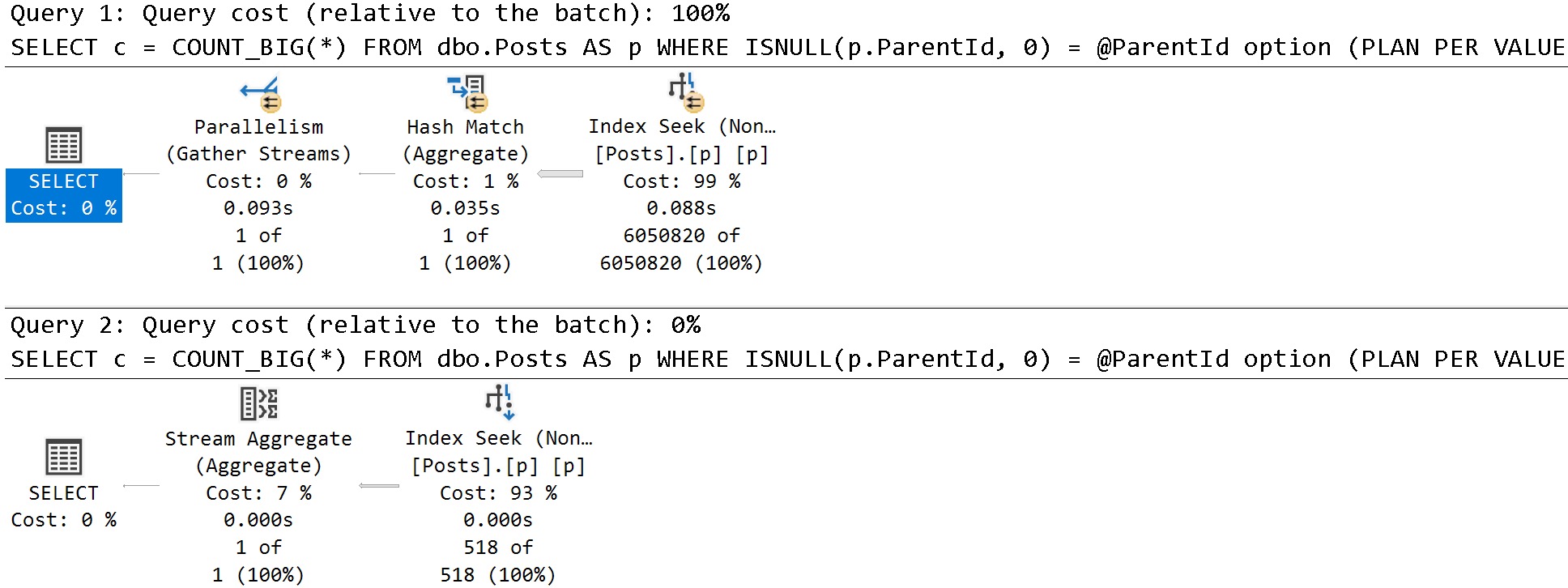
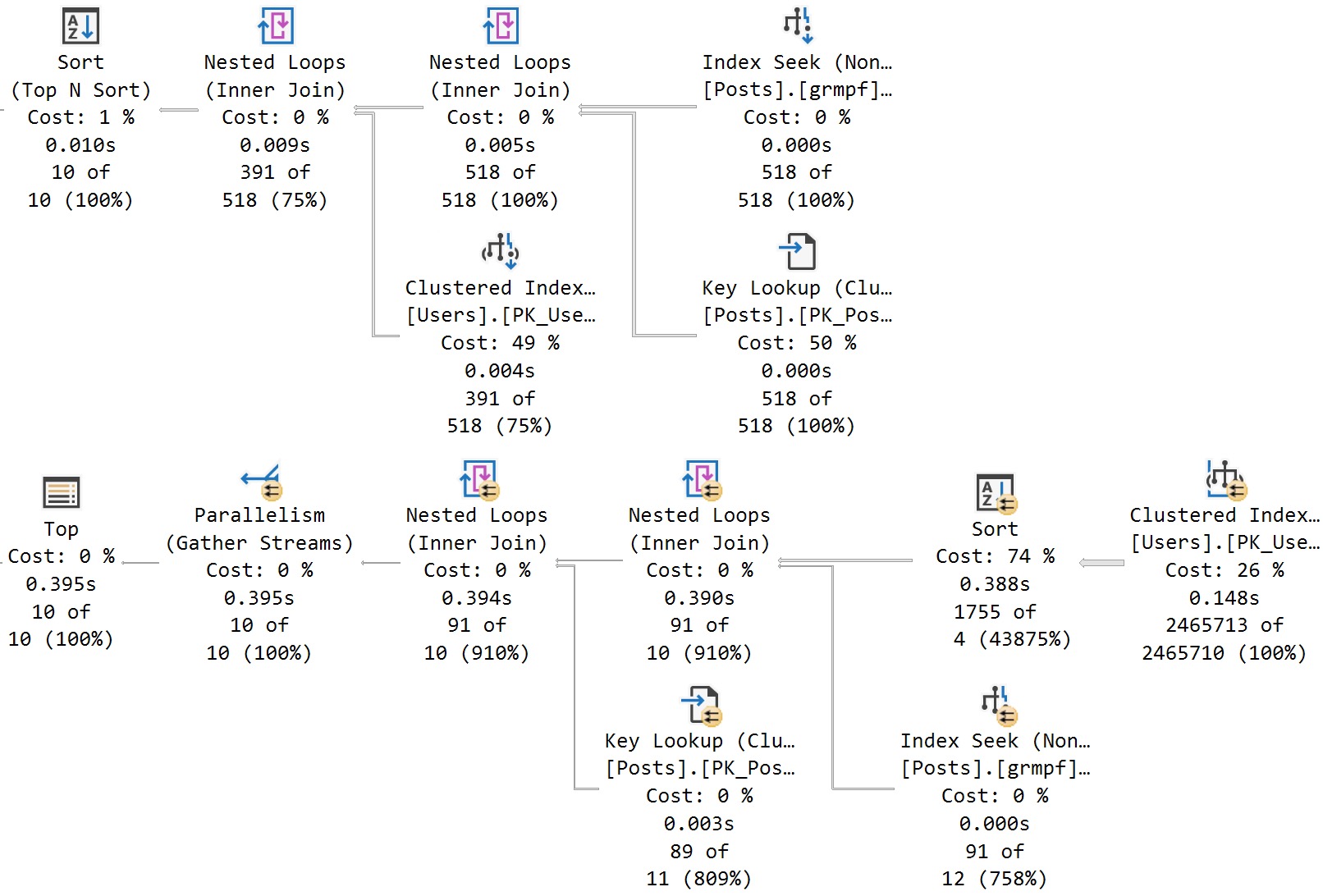
Anyway, the result using sp_BlitzIndex looks a lot better now:
EXEC sp_BlitzIndex
@TableName = 'Votes_CCI';
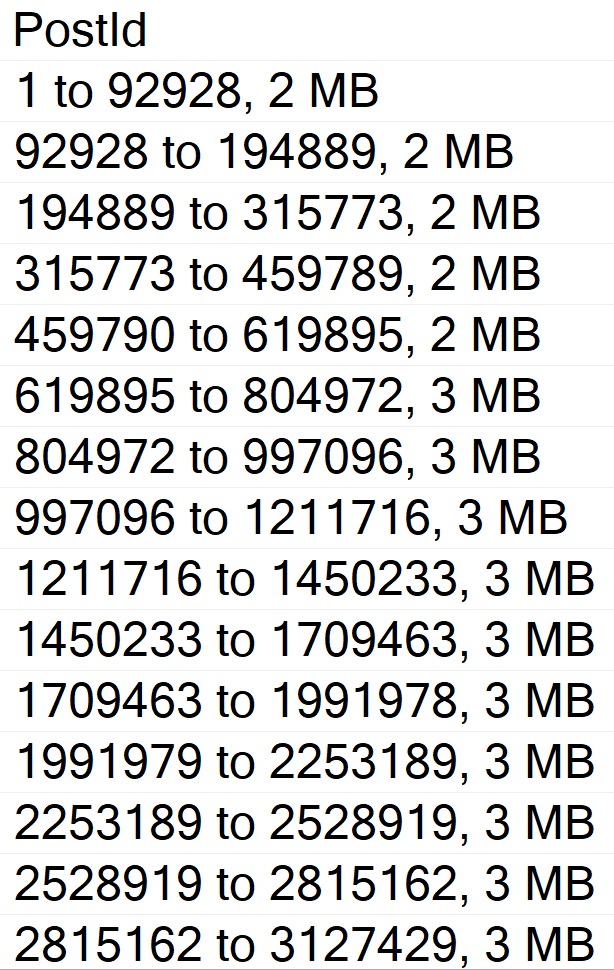
How nice.
You can also use undocumented and unsupported trace flag 11621, which is
Chain Gang
A “reasonable” alternative to trace flags maybe to adjust the index create memory configuration option. If we set it down to the minimum value, we get a “helpful” error message:
EXEC sys.sp_configure
'index create memory',
704;
RECONFIGURE;
As promised:
Msg 8606, Level 17, State 1, Line 31
This index operation requires 123208 KB of memory per DOP.
The total requirement of 985800 KB for DOP of 8 is greater than the sp_configure value of 704 KB set for the advanced server configuration option “index create memory (KB)”.
Increase this setting or reduce DOP and rerun the query.
If you get the actual execution plan for the clustered column store index create or rebuild with the Soft Sort disabled and look at the memory grant, you get a reasonable estimate for what to set index create memory to.
Changing it does two things:
- Avoids the very low memory grant that Soft Sorts receive, and causes the uneven row groups
- The Soft Sort keeps the index create from going above that index create memory number
Setting index create memory for this particular index creation/rebuild to 5,561,824 gets you the nice, even row groups (at MAXDOP 1) that we saw when disabling the Soft Sort entirely.
Bottom line, here is that uneven row groups happen with column store indexes when there’s a:
- Parallel create/rebuild
- Low memory grant create/rebuild
If this sort of thing is particularly important to you, you could adjust index create memory to a value that allows the Soft Sort adequate memory.
But that’s a hell of a lot of work, and I hope Microsoft just fixes this in a later build.
Reality Bites
The cute thing here is that, while this syntactical functionality has been available in Azure Cloud Nonsense© for some time, no one uses that, so no one cares.
The bits for this were technically available in SQL Server 2019 as well, but I’m not telling you how to do that. It’s not supported, and bad things might happen if you use it.
I mean, bad things happen in SQL Server 2022 where it’s supported unless you use an undocumented trace flag, but… Uh. I dunno.
This trace flag seems to set things back to how things worked in the Before Times, though, which is probably how they should have stayed.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.