Long Time Coming
When Microsoft first started coming up with these Intelligent Query Processing features, I think everyone who cares about That Sort Of Thing© wondered when parameter sensitivity would get fixed.
Let’s take a brief moment to talk about terminology here, so you don’t go getting yourself all tied up in knots:
- Parameter Sniffing: When the optimizer creates and caches a plan based on a set of parameter(s) for reuse
- Parameter Sensitivity: When a cached plan for one set of parameter(s) is not a good plan for other sets of parameter(s)
The first one is a usually-good thing, because your SQL Server won’t spend a lot of time compiling plans constantly. This is obviously more important for OLTP workloads than for data warehouses.
This can pose problems in either type of environment when data is skewed towards one or more values, because queries that need to process a lot of rows typically need a different execution plan strategy than queries processing a small number of rows.
This seems a good fit for the Intelligent Query Processing family of SQL Server features, because fixing it sometimes requires a certain level of dynamism.
Choice 2 Choice
The reason this sort of thing can happen often comes down to indexing. That’s obviously not the only thing. Even a perfect index won’t make nested loops more efficient than a hash join (and vice versa) under the right circumstances.
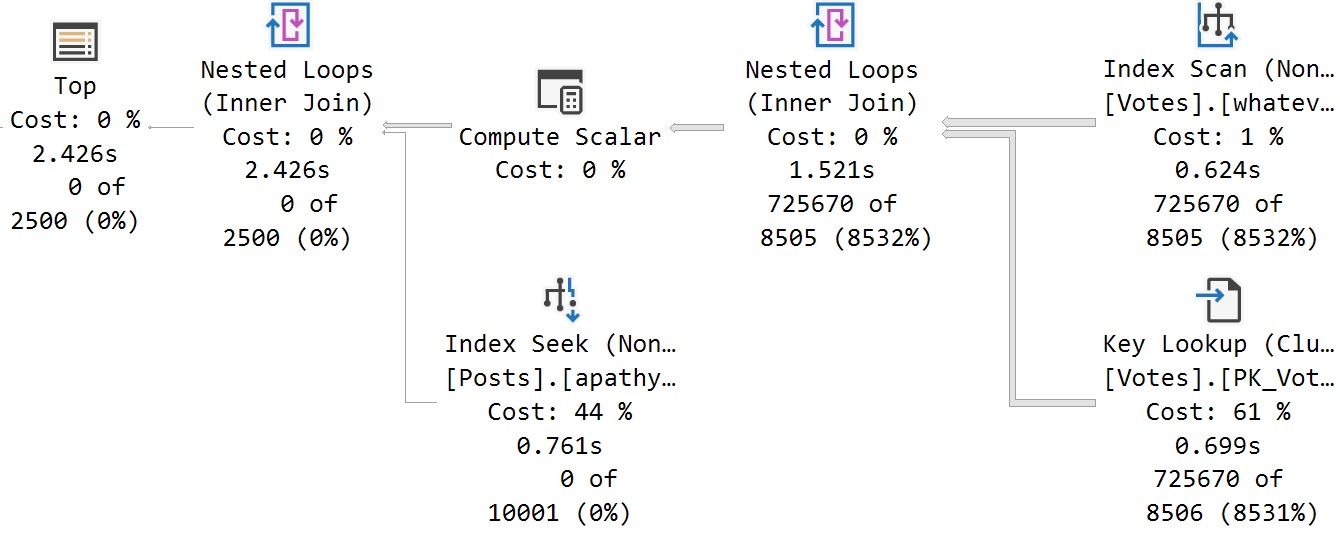
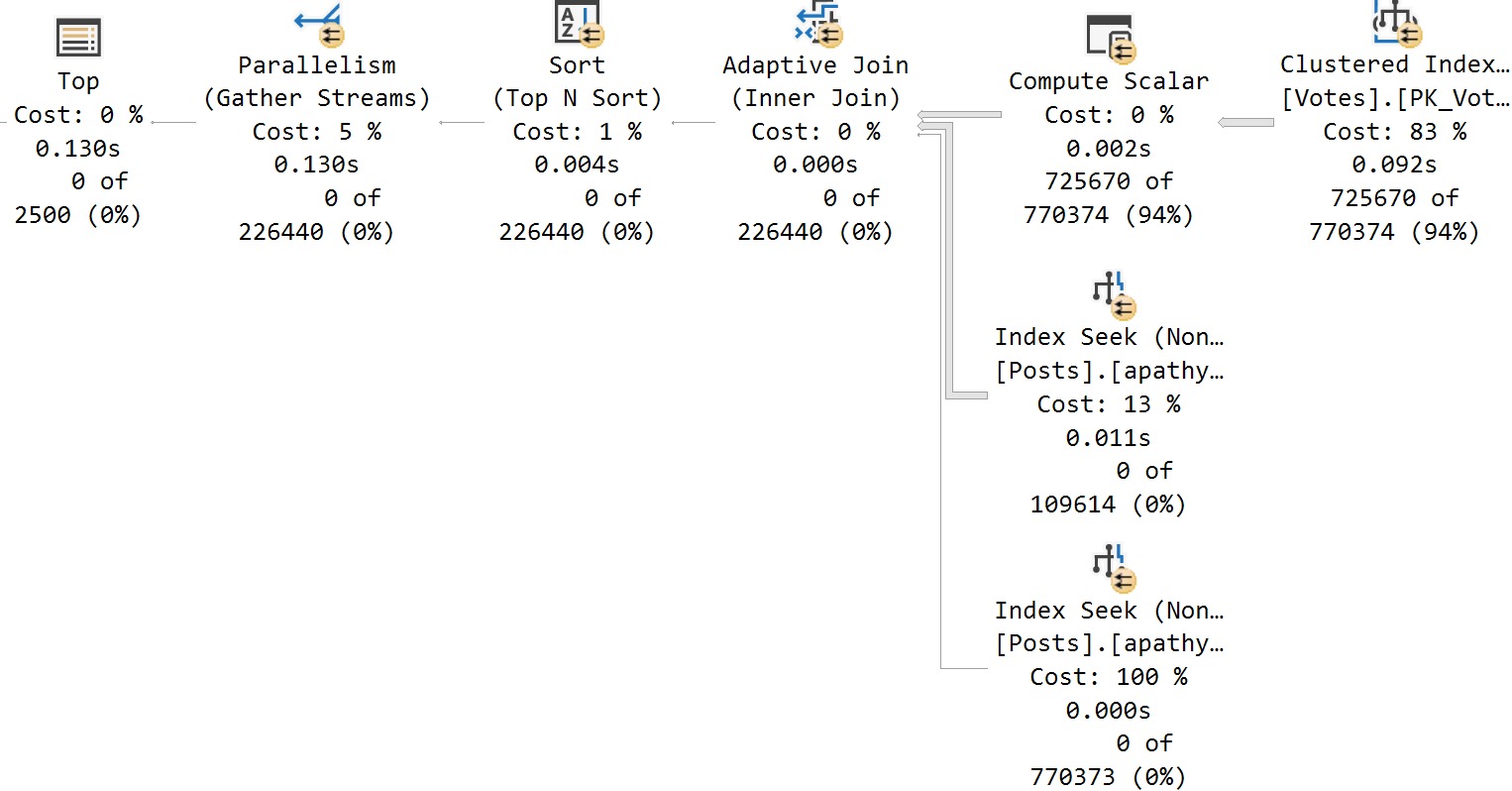
Probably the most classic parameter sensitivity issue, and why folks spend a long time trying to fix them, is the also-much-maligned Lookup.
But consider the many other things that might happen in a query plan that will hamper performance.
- Join type
- Join order
- Memory grants
- Parallelism
- Aggregate type
- Sort/Sort Placement
- Batch Mode
The mind boggles at all the possibilities. This doesn’t even get into all the wacky and wild things that can mess SQL Server’s cost-based optimizer up a long the way.
- Table variables
- Local variables
- Optimize for unknown
- Non-SARGable predicates
- Wrong cardinality estimation model
- Row Goals
- Out of date statistics
The mind also boggles here. Anyway, I’ve written quite a bit about parameter sensitivity in the past, so I’m going to link you to the relevant post tag for those.
Unlearn
With SQL Server 2022, we’ve finally got a starting point for resolving this issue.
In tomorrow’s post, we’ll talk a bit about how this new feature works to help with your parameter sensitivity issues, which are issues.
Not your parameter sniffing issues, which are not issues.
For the rest of the week, I’m going to dig deeper into some of the stuff that the documentation glosses over, where it helps, and show you a situation where it should kick in and help but doesn’t.
Keep in mind that these are early thoughts, and I expect things to evolve both as RTM season approaches, and as Cumulative Updates are released for SQL Server 2022.
Remember scalar UDF inlining? That thing morphed quite a bit.
Can’t wait for all of you to get on SQL Server 2019 and experience it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.